Assign \(y_i = 0\), if \(h_\theta(x_i) < 0.5\); \(y_i = 1\), if \(h_\theta(x_i) \geq 0.5\)
The parameter vector \(\theta\) is optimized using gradient descent.
Which loss function should be used and why?
Remarks
In constructing machine learning models with libraries like scikit-learn or keras, one has to select a loss function or accept the default one.
Initially, the terminology can be confusing, as identical functions may be referenced by various names.
Our aim is to elucidate these complexities.
It is actually not that complicated!
Parameter Estimation
Logistic regression is statistical model.
Its output is \(\hat{y} = P(y = 1 | x, \theta)\).
\(P(y = 0 | x, \theta) = 1 - \hat{y}\).
Assumes that \(y\) values come from a Bernoulli distribution.
\(\theta\) is commonly found by Maximum Likelihood Estimation.
Parameter Estimation
Maximum Likelihood Estimation (MLE) is a statistical method used to estimate the parameters of a probabilistic model.
It identifies the parameter values that maximize the likelihood function, which measures how well the model explains the observed data.
Likelihood Function
Assuming the \(y\) values are independent and identically distributed (i.i.d.), the likelihood function is expressed as the product of individual probabilities.
In other words, given our data, \(\{(x_i, y_i)\}_{i=1}^N\), the likelihood function is given by this equation. \[
\mathcal{L}(\theta) = \prod_{i=1}^{N} P(y_i \mid x_i, \theta)
\]
Simplifying the equation. \[
J(\theta) = - \sum_{i=1}^{N} \log [ \sigma(\theta x_i)^{y_i} (1 - \sigma(\theta x_i))^{1-y_i} ]
\] by distributing the \(\log\) into the square parenthesis. \[
J(\theta) = - \sum_{i=1}^{N} [ \log \sigma(\theta x_i)^{y_i} + \log (1 - \sigma(\theta x_i))^{1-y_i} ]
\]
Loss Function (continued)
Simplifying the equation further. \[
J(\theta) = - \sum_{i=1}^{N} [ \log \sigma(\theta x_i)^{y_i} + \log (1 - \sigma(\theta x_i))^{1-y_i} ]
\] by moving the exponents in front of the \(\log\)s.
Decision tree algorithms often employ entropy, a measure from information theory, to evaluate the quality of splits or partitions in decision rules.
Entropy quantifies the uncertainty or impurity associated with the potential outcomes of a random variable.
Entropy
Entropy in information theory quantifies the uncertainty or unpredictability of a random variable’s possible outcomes. It measures the average amount of information produced by a stochastic source of data and is typically expressed in bits for binary systems. The entropy \(H\) of a discrete random variable \(X\) with possible outcomes \(\{x_1, x_2, \ldots, x_n\}\) and probability mass function \(P(X)\) is given by:
\[
H(X) = -\sum_{i=1}^n P(x_i) \log_2 P(x_i)
\]
Cross-Entropy
Cross-entropy quantifies the difference between two probability distributions, typically the true distribution and a predicted distribution.
\[
H(p, q) = -\sum_{i} p(x_i) \log q(x_i)
\] where \(p(x_i)\) is the true probability distribution, and \(q(x_i)\) is the predicted probability distribution.
Cross-Entropy
Consider \(y\) as the true probability distribution and \(\hat{y}\) as the predicted probability distribution.
Cross-entropy quantifies the discrepancy between these two distributions.
Cross-Entropy
Consider the negative log-likelihood loss function:
This expression illustrates that the negative log-likelihood is optimized by minimizing the cross-entropy.
For Each Example
Code
import matplotlib.pyplot as pltimport numpy as npnp.random.seed(42)# Generate an array of p values from just above 0 to 1p_values = np.linspace(0.001, 1, 1000)# Compute the natural logarithm of each p valueln_p_values =- np.log(p_values)# Plot the graphplt.figure(figsize=(5, 4))plt.plot(p_values, ln_p_values, label=r'$-\log(\hat{y})$', color='b')# Add labels and titleplt.xlabel(r'$\hat{y}$')plt.ylabel(r'J')plt.title(r'Graph of $-\log(\hat{y})$ for $\hat{y}$ from 0 to 1')plt.grid(True)plt.axhline(0, color='gray', lw=0.5) # Add horizontal line at y=0plt.axvline(0, color='gray', lw=0.5) # Add vertical line at x=0# Display the plotplt.legend()plt.show()
Remarks
Cross-entropy loss is particularly well-suited for probabilistic classification tasks due to its alignment with maximum likelihood estimation.
In logistic regression, cross-entropy loss preserves convexity, contrasting with the non-convex nature of mean squared error (MSE)1.
Remarks
For classification problems, cross-entropy loss often achieves faster convergence compared to MSE, enhancing model efficiency.
Within deep learning architectures, MSE can exacerbate the vanishing gradient problem, an issue we will address in a subsequent discussion.
Why not MSE as a Loss Function?
What is the Difference?
Geometric Interpretation
Geometric Interpretation
Do you recognize this equation? \[
w_1 x_1 + w_2 x_2 + \ldots + w_D x_2
\]
This is the dot product of \(\mathbf{w}\) and \(\mathbf{x}\), \(\mathbf{w} \cdot \mathbf{x}\).
What is the geometric interpretation of the dot product?
The dot product determines the angle \((\theta)\) between vectors.
It quantifies how much one vector extends in the direction of another.
Its value is zero, if the vectors are perpendicular\((\theta = 90^\circ)\).
Geometric Interpretation
Logistic regression uses a linear combination of the input features, \(\mathbf{w} \cdot \mathbf{x} + b\), as the argument to the sigmoid (logistic) function.
Geometrically, \(\mathbf{w}\) can be viewed as a vector normal to a hyperplane in the feature space, and any point \(\mathbf{x}\) is projected onto \(\mathbf{w}\) via the dot product \(\mathbf{w} \cdot \mathbf{x}\).
Geometric Interpretation
The decision boundary is where this linear combination equals zero, i.e., \(\mathbf{w} \cdot \mathbf{x} + b = 0\).
Points on one side of the boundary have a positive dot product and are more likely to be classified as the positive class (1).
Points on the other side have a negative dot product and are more likely to be in the opposite class (0).
The sigmoid function simply turns this signed distance into a probability between 0 and 1.
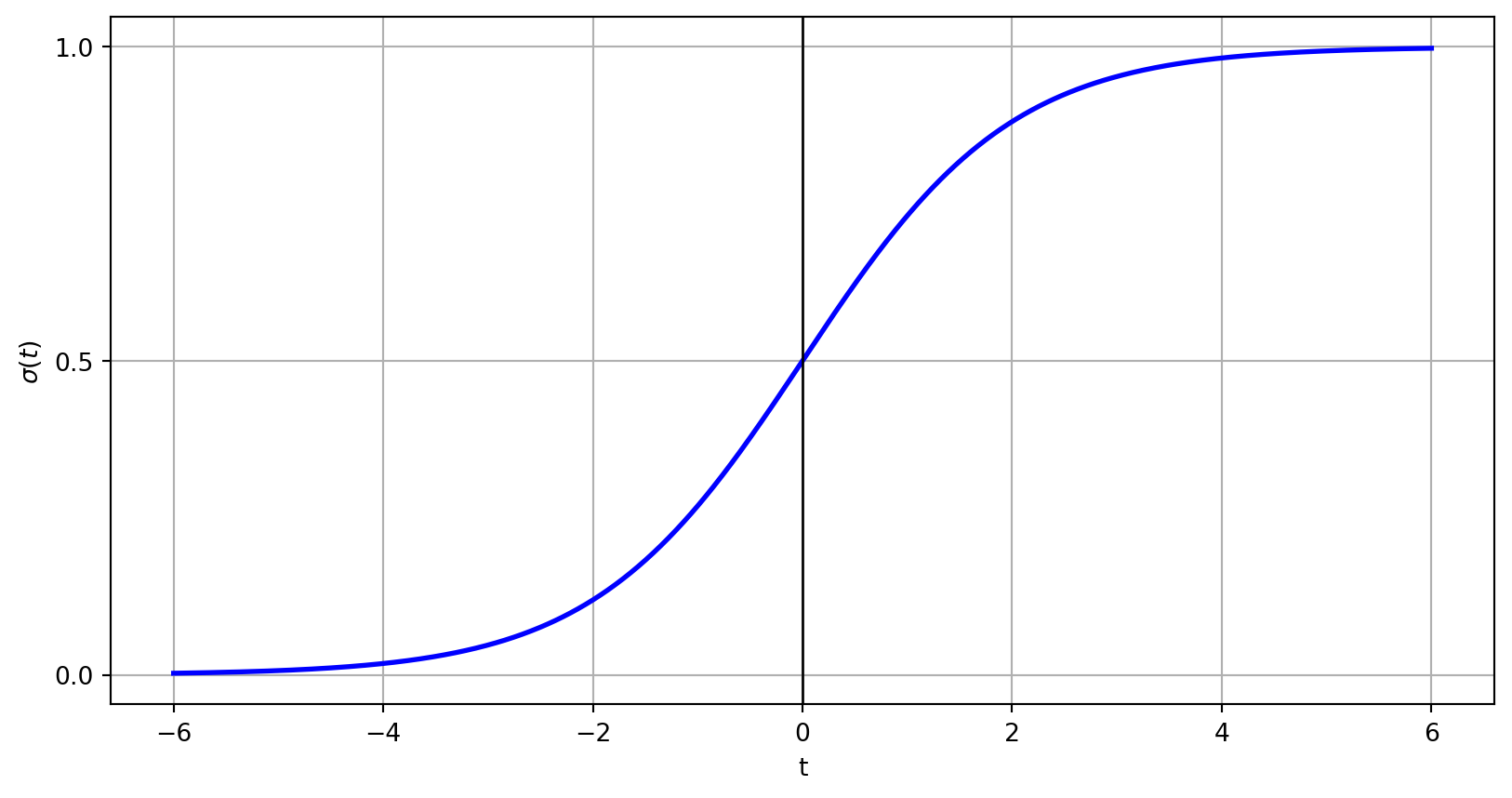
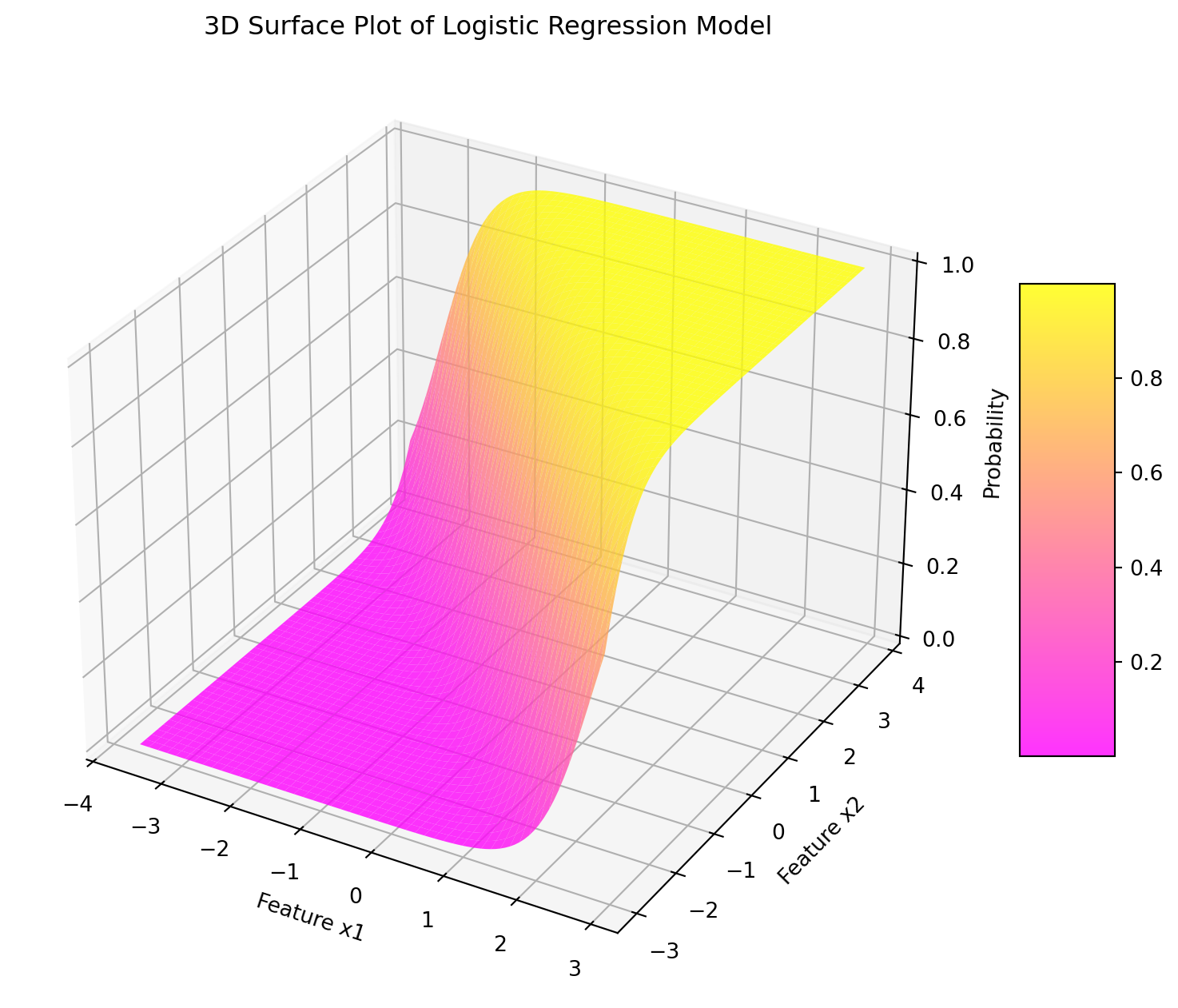
Logistic Function
\[
\sigma(t) = \frac{1}{1+e^{-t}}
\]
As \(t \to \infty\), \(e^{-t} \to 0\), so \(\sigma(t) \to 1\).
As \(t \to -\infty\), \(e^{-t} \to \infty\), making the denominator approach infinity, so \(\sigma(t) \to 0\).
When \(t = 0\), \(e^{-t} = 0\), resulting in a denominator of 2, so \(\sigma(t) = 0.5\).
Code
# Sigmoid functiondef sigmoid(t):return1/ (1+ np.exp(-t))# Generate t valuest = np.linspace(-6, 6, 1000)# Compute y values for the sigmoid functionsigma = sigmoid(t)# Create a figurefig, ax = plt.subplots()ax.plot(t, sigma, color='blue', linewidth=2) # Keep the curve opaque# Draw vertical axis at x = 0ax.axvline(x=0, color='black', linewidth=1)# Add labels on the vertical axisax.set_yticks([0, 0.5, 1.0])# Add labels to the axesax.set_xlabel('t')ax.set_ylabel(r'$\sigma(t)$')plt.grid(True)plt.show()
What’s special about e?
\[
\sigma(t) = \frac{1}{1+e^{-t}}
\]
Instead of \(e\), we might have used another constant, say 2.
Derivative Simplicity: For the logistic function \(\sigma(x) = \tfrac{1}{1 + e^{-x}}\), the derivative simplifies to \(\sigma'(x) = \sigma(x)(1 - \sigma(x))\). This elegant form arises because the exponential base \(e\) has the unique property that \(\tfrac{d}{dx} e^x = e^x\), avoiding an extra multiplicative constant.
Code
import mathdef logistic(x, e):"""Compute a modified logistic function using b rather than e."""return1/ (1+ np.power(e, -x))# Define a range for x values.x = np.linspace(-6, 6, 400)# Plot 1: Varying e.plt.figure(figsize=(8, 6))e_values = [2, math.e, 4, 8, 16] # different steepness valuesfor e in e_values: plt.plot(x, logistic(x, e), label=f'e = {e}')plt.title('Effect of Varying e')plt.xlabel('x')plt.ylabel(r'$\frac{1}{1+e^{-x}}$')plt.legend()plt.grid(True)
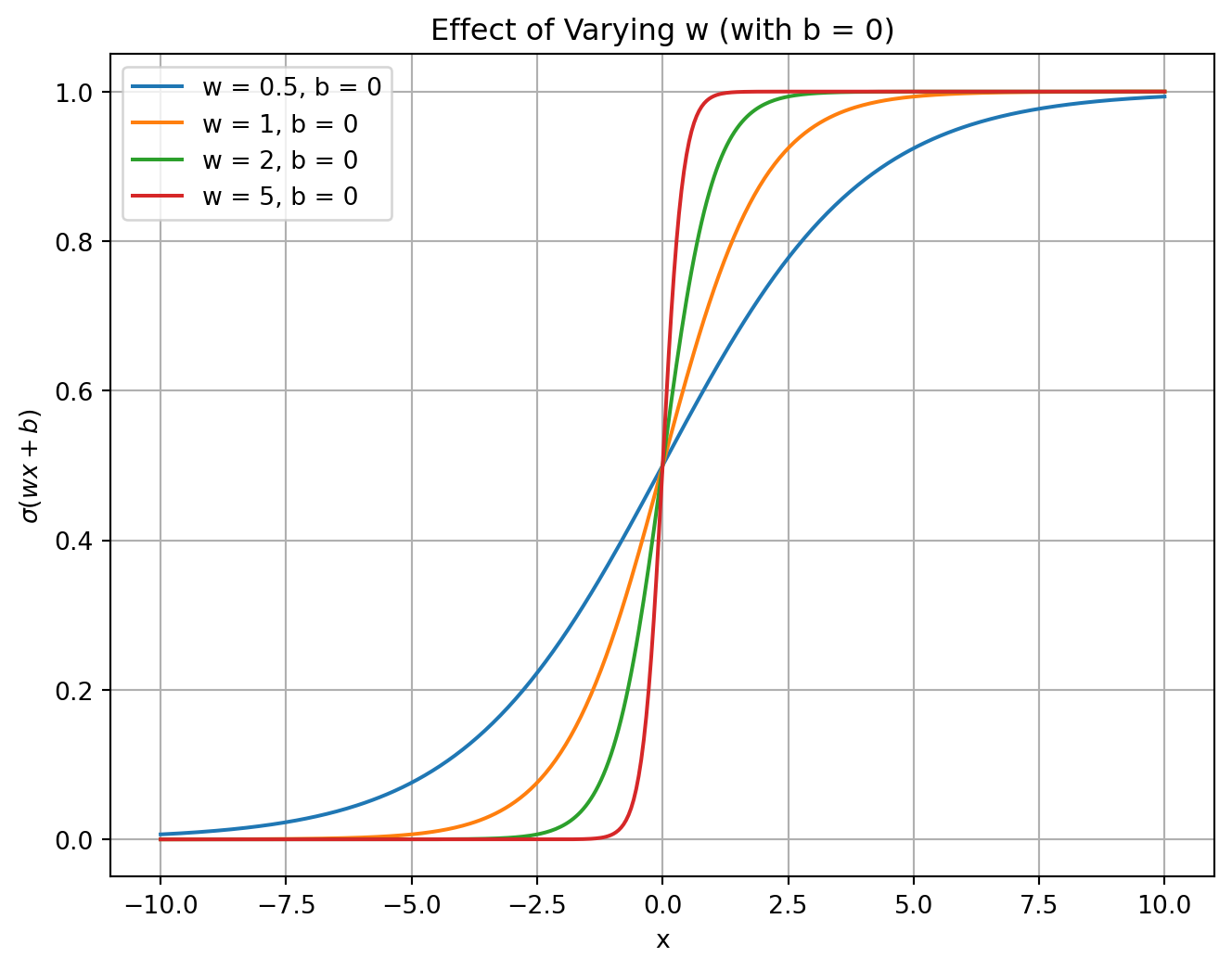
Varying w
\[
\sigma(wx + b)
\]
Code
def logistic(x, w, b):"""Compute the logistic function with parameters w and b."""return1/ (1+ np.exp(-(w * x + b)))# Define a range for x values.x = np.linspace(-10, 10, 400)# Plot 1: Varying w (steepness) with b fixed at 0.plt.figure(figsize=(8, 6))w_values = [0.5, 1, 2, 5] # different steepness valuesb =0# fixed biasfor w in w_values: plt.plot(x, logistic(x, w, b), label=f'w = {w}, b = {b}')plt.title('Effect of Varying w (with b = 0)')plt.xlabel('x')plt.ylabel(r'$\sigma(wx+b)$')plt.legend()plt.grid(True)plt.show()
Varying b
\[
\sigma(wx + b)
\]
Code
# Plot 2: Varying b (horizontal shift) with w fixed at 1.plt.figure(figsize=(8, 6))w =1# fixed steepnessb_values = [-5, -2, 0, 2, 5] # different bias valuesfor b in b_values: plt.plot(x, logistic(x, w, b), label=f'w = {w}, b = {b}')plt.title('Effect of Varying b (with w = 1)')plt.xlabel('x')plt.ylabel(r'$\sigma(wx+b)$')plt.legend()plt.grid(True)plt.show()
Implementation
Implementation: Generating Data
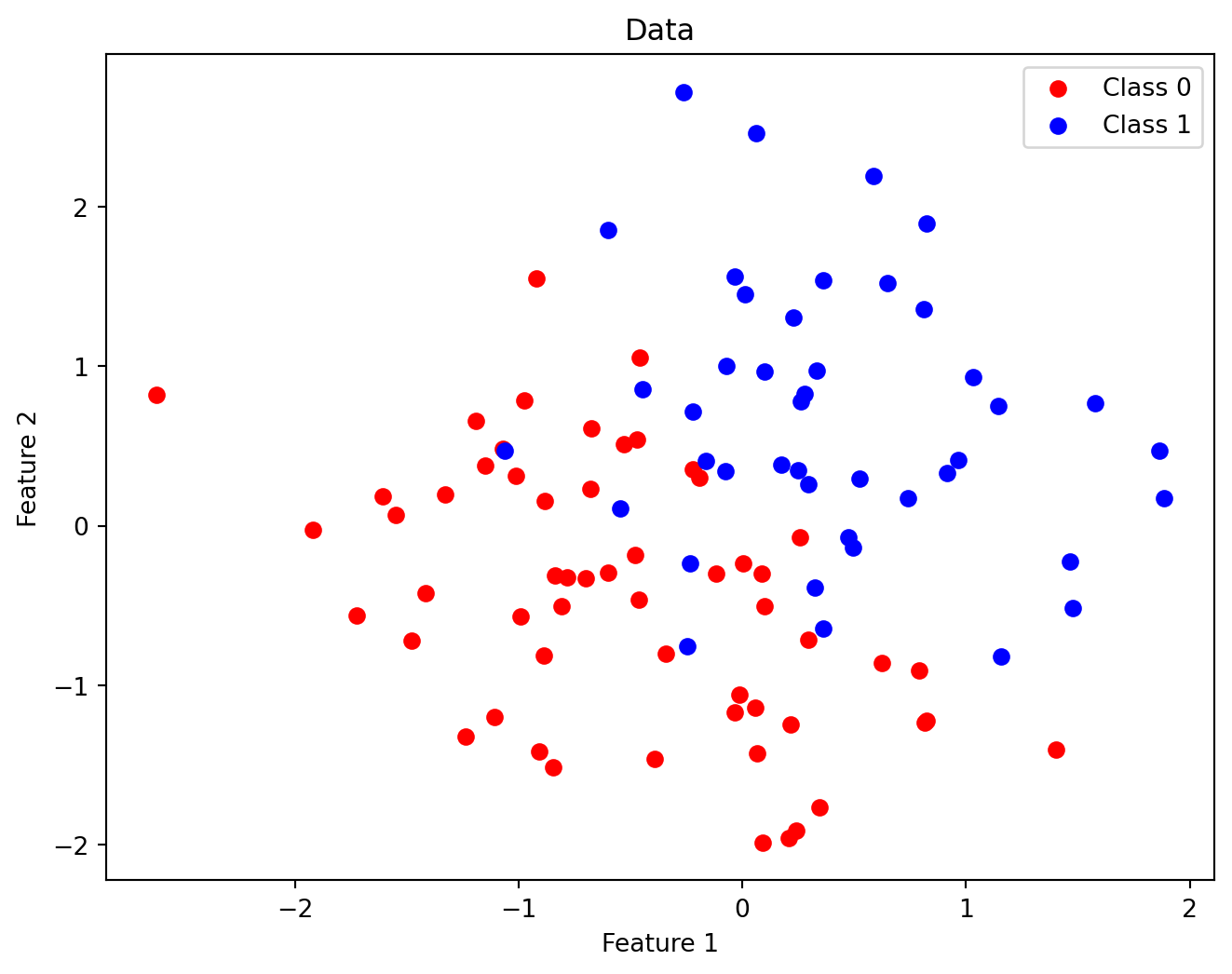
# Generate synthetic data for a binary classification problemm =100# number of examplesd =2# number of featuesX = np.random.randn(m, d)# Define labels using a linear decision boundary with some noise:noise =0.5* np.random.randn(m)y = (X[:, 0] + X[:, 1] + noise >0).astype(int)
Implementation: Vizualization
Code
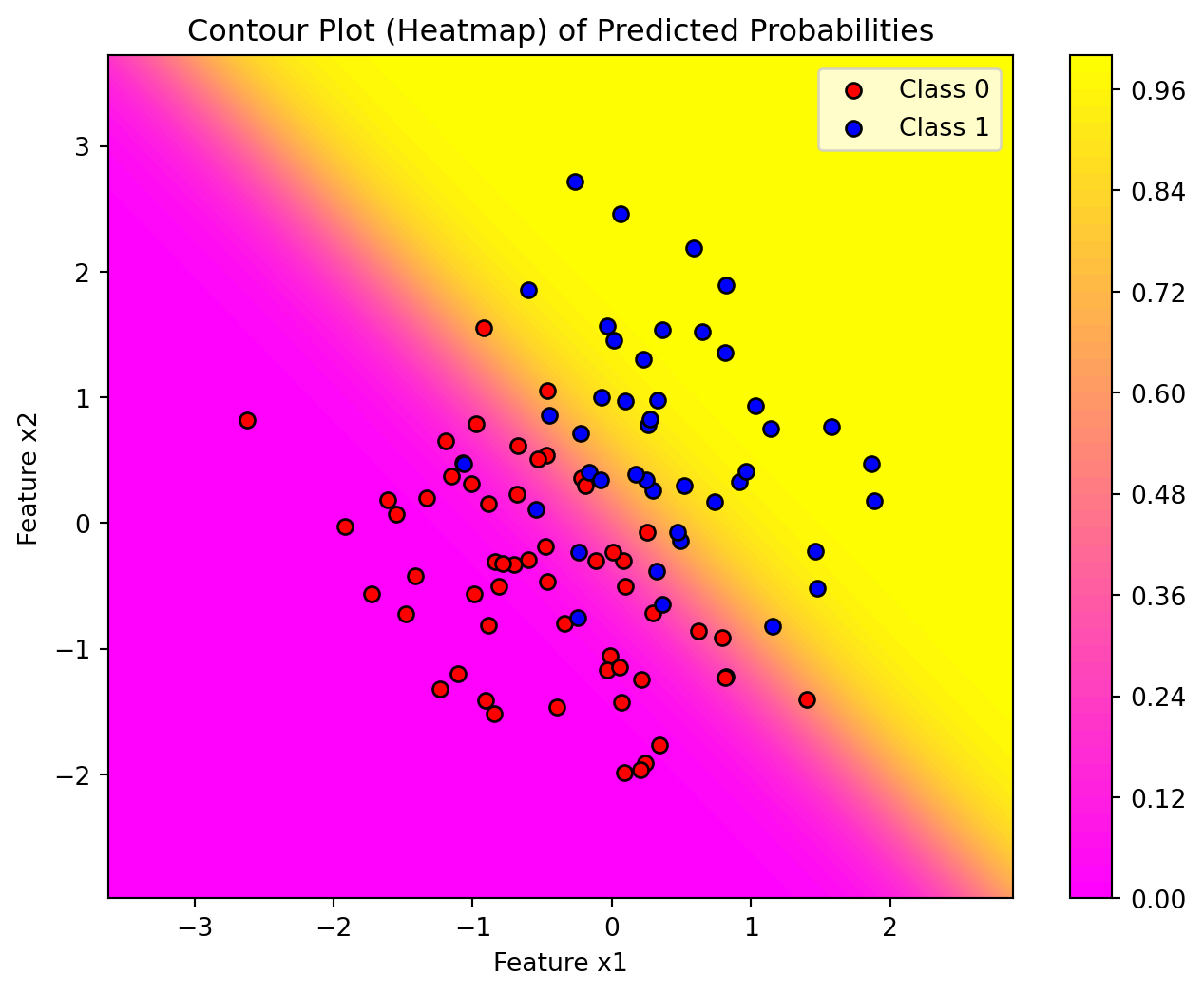
# Visualize the decision boundary along with the data pointsplt.figure(figsize=(8, 6))plt.scatter(X[y ==0][:, 0], X[y ==0][:, 1], color='red', label='Class 0')plt.scatter(X[y ==1][:, 0], X[y ==1][:, 1], color='blue', label='Class 1')plt.xlabel("Feature 1")plt.ylabel("Feature 2")plt.title("Data")plt.legend()plt.show()
Implementation: Cost Function
# Sigmoid functiondef sigmoid(z):return1/ (1+ np.exp(-z))# Cost function: binary cross-entropydef cost_function(theta, X, y): m =len(y) h = sigmoid(X.dot(theta)) epsilon =1e-5# avoid log(0) cost =-(1/m) * np.sum(y * np.log(h + epsilon) + (1- y) * np.log(1- h + epsilon))return cost# Gradient of the cost functiondef gradient(theta, X, y): m =len(y) h = sigmoid(X.dot(theta)) grad = (1/m) * X.T.dot(h - y)return grad
Implementation: Logistic Regression
# Logistic regression training using gradient descentdef logistic_regression(X, y, learning_rate=0.1, iterations=1000): m, n = X.shape theta = np.zeros(n) cost_history = []for i inrange(iterations): theta -= learning_rate * gradient(theta, X, y) cost_history.append(cost_function(theta, X, y))return theta, cost_history
Training
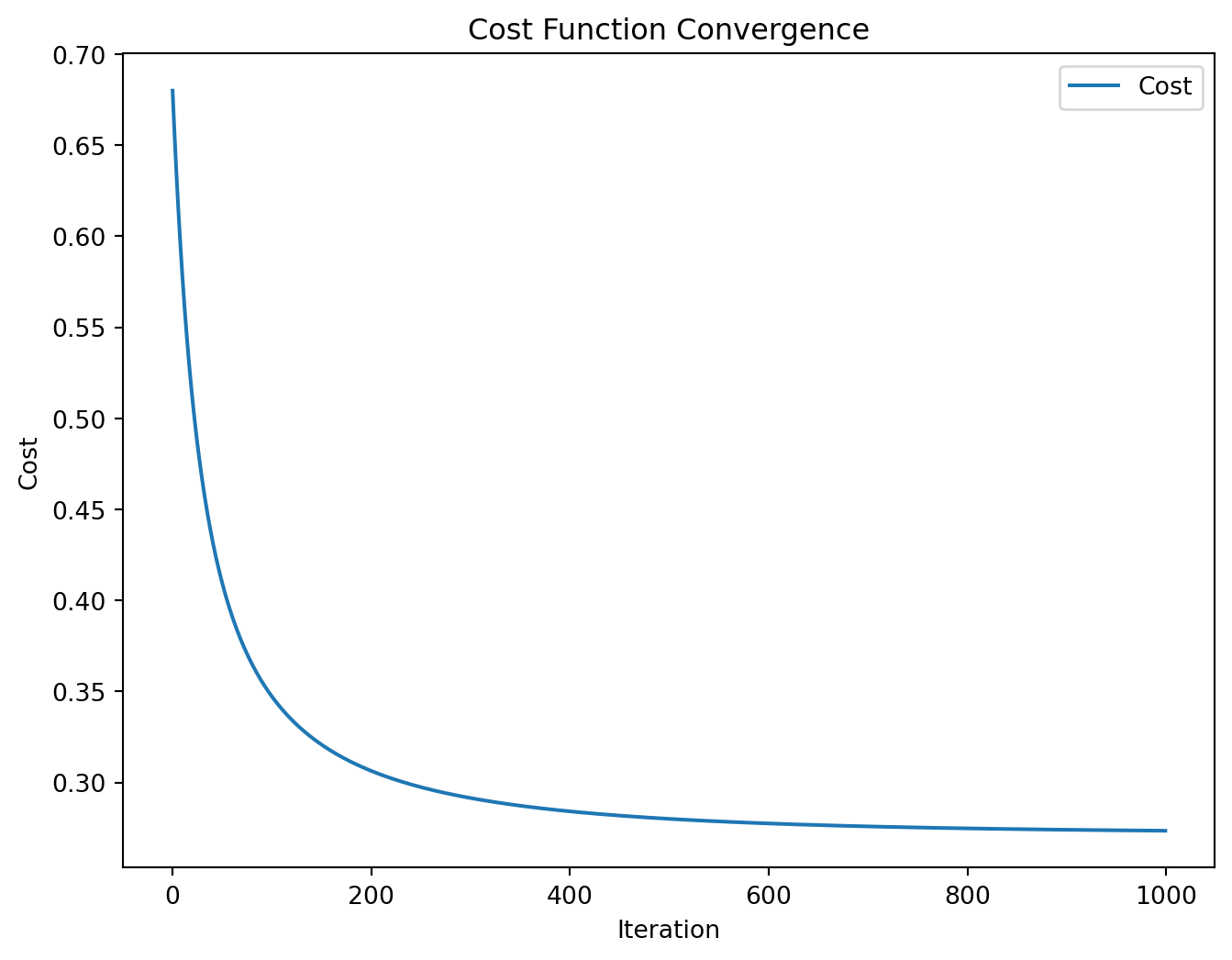
# Add intercept term (bias)X_with_intercept = np.hstack([np.ones((m, 1)), X])# Train the logistic regression modeltheta, cost_history = logistic_regression(X_with_intercept, y, learning_rate=0.1, iterations=1000)print("Optimized theta:", theta)
plt.figure(figsize=(8, 6))plt.plot(cost_history, label="Cost")plt.xlabel("Iteration")plt.ylabel("Cost")plt.title("Cost Function Convergence")plt.legend()plt.show()
# Predict function: returns class labels and probabilities for new datadef predict(theta, X, threshold=0.5): probs = sigmoid(X.dot(theta))return (probs >= threshold).astype(int), probs
Predictions
# New examples must include the intercept term.# Negative example (likely class 0): Choose a point far in the negative quadrant.example_neg = np.array([1, -3, -3])# Positive example (likely class 1): Choose a point far in the positive quadrant.example_pos = np.array([1, 3, 3])# Near decision boundary: Choose x1 = 0 and compute x2 from the decision boundary equation.x1_near =0x2_near =-(theta[0] + theta[1] * x1_near) / theta[2]example_near = np.array([1, x1_near, x2_near])
Predictions (continued)
# Combine the examples into one array for prediction.new_examples = np.vstack([example_neg, example_pos, example_near])labels, probabilities = predict(theta, new_examples)print("\nPredictions on new examples:")print("Negative example {} -> Prediction: {} (Probability: {:.4f})".format(example_neg[1:], labels[0], probabilities[0]))print("Positive example {} -> Prediction: {} (Probability: {:.4f})".format(example_pos[1:], labels[1], probabilities[1]))print("Near-boundary example {} -> Prediction: {} (Probability: {:.4f})".format(example_near[1:], labels[2], probabilities[2]))
Predictions on new examples:
Negative example [-3 -3] -> Prediction: 0 (Probability: 0.0000)
Positive example [3 3] -> Prediction: 1 (Probability: 1.0000)
Near-boundary example [0. 0.11760374] -> Prediction: 1 (Probability: 0.5000)
Visualizing the Weight Vector
In the previous lecture, we established that logistic regression determines a weight vector that is orthogonal to the decision boundary.
Conversely, the decision boundary itself is orthogonal to the weight vector, which is derived through gradient descent optimization.
Visualizing the Weight Vector
Code
# Plot decision boundary and data pointsplt.figure(figsize=(8, 6))plt.scatter(X[y ==0][:, 0], X[y ==0][:, 1], color='red', label='Class 0')plt.scatter(X[y ==1][:, 0], X[y ==1][:, 1], color='blue', label='Class 1')# Decision boundary: theta0 + theta1*x1 + theta2*x2 = 0x_vals = np.array([min(X[:, 0]) -1, max(X[:, 0]) +1])y_vals =-(theta[0] + theta[1] * x_vals) / theta[2]plt.plot(x_vals, y_vals, label='Decision Boundary', color='green')# --- Draw the normal vector ---# The normal vector is (theta[1], theta[2]).# Choose a reference point on the decision boundary. Here, we use x1 = 0:x_ref =0y_ref =-theta[0] / theta[2] # when x1=0, theta0 + theta2*x2=0 => x2=-theta0/theta2# Create the normal vector from (theta[1], theta[2]).normal = np.array([theta[1], theta[2]])# Normalize and scale for displaynormal_norm = np.linalg.norm(normal)if normal_norm !=0: normal_unit = normal / normal_normelse: normal_unit = normalscale =2# adjust scale as needednormal_display = normal_unit * scale# Draw an arrow starting at the reference pointplt.arrow(x_ref, y_ref, normal_display[0], normal_display[1], head_width=0.1, head_length=0.2, fc='black', ec='black')plt.text(x_ref + normal_display[0]*1.1, y_ref + normal_display[1]*1.1, r'$(\theta_1, \theta_2)$', color='black', fontsize=12)plt.xlabel("Feature 1")plt.ylabel("Feature 2")plt.title("Logistic Regression Decision Boundary and Normal Vector")plt.legend()plt.gca().set_aspect('equal', adjustable='box')plt.ylim(-3, 3)plt.show()