Model Evaluation and Hyperparameter Tuning
CSI 4106 - Fall 2025
Version: Sep 23, 2025 12:55
Preamble
Message of the Day

Learning Objectives
- Understand the Purpose of Data Splitting:
- Describe the roles of the training, validation, and test sets in model evaluation.
- Explain why and how datasets are divided for effective model training and evaluation.
- Explain Cross-Validation Techniques:
- Define cross-validation and its importance in model evaluation.
- Illustrate the process of \(k\)-fold cross-validation and its advantages over a single train-test split.
- Discuss the concepts of underfitting and overfitting in the context of cross-validation.
- Hyperparameter Tuning:
- Explain the difference between model parameters and hyperparameters.
- Describe methods for tuning hyperparameters, including grid search and randomized search.
- Implement hyperparameter tuning using
GridSearchCVin scikit-learn.
- Evaluate Model Performance:
- Interpret cross-validation results and understand metrics like mean and standard deviation of scores.
- Discuss how cross-validation helps in assessing model generalization and reducing variability.
- Machine Learning Engineering Workflow:
- Outline the steps involved in preparing data for machine learning models.
- Utilize scikit-learn pipelines for efficient data preprocessing and model training.
- Emphasize the significance of consistent data transformations across training and production environments.
- Critical Evaluation of Machine Learning Models:
- Assess the limitations and challenges associated with hyperparameter tuning and model selection.
- Recognize potential pitfalls in data preprocessing, such as incorrect handling of missing values or inconsistent encoding.
- Advocate for thorough testing and validation to ensure model reliability and generalizability.
- Integrate Knowledge in Practical Applications:
- Apply the learned concepts to real-world datasets (e.g., OpenML datasets like ‘diabetes’ and ‘adult’).
- Interpret and analyze the results of model evaluations and experiments.
- Develop a comprehensive understanding of the end-to-end machine learning pipeline.
Introduction
Dataset - openml
OpenML is an open platform for sharing datasets, algorithms, and experiments - to learn how to learn better, together.
Dataset - openml
Author: Vincent Sigillito
Source: Obtained from UCI
Please cite: UCI citation policy
Title: Pima Indians Diabetes Database
Sources:
- Original owners: National Institute of Diabetes and Digestive and Kidney Diseases
- Donor of database: Vincent Sigillito (vgs@aplcen.apl.jhu.edu) Research Center, RMI Group Leader Applied Physics Laboratory The Johns Hopkins University Johns Hopkins Road Laurel, MD 20707 (301) 953-6231
- Date received: 9 May 1990
Past Usage:
Smith,J.W., Everhart,J.E., Dickson,W.C., Knowler,W.C., & Johannes,R.S. (1988). Using the ADAP learning algorithm to forecast the onset of diabetes mellitus. In {it Proceedings of the Symposium on Computer Applications and Medical Care} (pp. 261–265). IEEE Computer Society Press.
The diagnostic, binary-valued variable investigated is whether the patient shows signs of diabetes according to World Health Organization criteria (i.e., if the 2 hour post-load plasma glucose was at least 200 mg/dl at any survey examination or if found during routine medical care). The population lives near Phoenix, Arizona, USA.
Results: Their ADAP algorithm makes a real-valued prediction between 0 and 1. This was transformed into a binary decision using a cutoff of 0.448. Using 576 training instances, the sensitivity and specificity of their algorithm was 76% on the remaining 192 instances.
Relevant Information: Several constraints were placed on the selection of these instances from a larger database. In particular, all patients here are females at least 21 years old of Pima Indian heritage. ADAP is an adaptive learning routine that generates and executes digital analogs of perceptron-like devices. It is a unique algorithm; see the paper for details.
Number of Instances: 768
Number of Attributes: 8 plus class
For Each Attribute: (all numeric-valued)
- Number of times pregnant
- Plasma glucose concentration a 2 hours in an oral glucose tolerance test
- Diastolic blood pressure (mm Hg)
- Triceps skin fold thickness (mm)
- 2-Hour serum insulin (mu U/ml)
- Body mass index (weight in kg/(height in m)^2)
- Diabetes pedigree function
- Age (years)
- Class variable (0 or 1)
Missing Attribute Values: None
Class Distribution: (class value 1 is interpreted as “tested positive for diabetes”)
Class Value Number of instances 0 500 1 268
Brief statistical analysis:
Attribute number: Mean: Standard Deviation:
3.8 3.4120.9 32.069.1 19.420.5 16.079.8 115.232.0 7.90.5 0.333.2 11.8
Relabeled values in attribute ‘class’ From: 0 To: tested_negative
From: 1 To: tested_positive
Downloaded from openml.org.
Dataset - return_X_y
fetch_openml returns a Bunch, a DataFrame, or X and y
Mild imbalance (ratio less than 3 or 4)
Cross-evaluation
Training and test set
Sometimes called holdout method.
Guideline: Typically, allocate 80% of your dataset for training and reserve the remaining 20% for testing.
Training Set: This subset of data is utilized to train your model.
Test Set: This is an independent subset used exclusively at the final stage to assess the model’s performance.
Training and test set
Training Error:
- Generally tends to be low
- Achieved by optimizing learning algorithms to minimize error through parameter adjustments (e.g., weights)
Training and test set
Generalization Error: The error rate observed when the model is evaluated on new, unseen data.
Training and test set
Underfitting:
- High training error
- Model is too simple to capture underlying patterns
- Poor performance on both training and new data
Overfitting:
- Low training error, but high generalization error
- Model captures noise or irrelevant patterns
- Poor performance on new, unseen data
Definition
Cross-validation is a method used to evaluate and improve the performance of machine learning models.
It involves partitioning the dataset into multiple subsets, training the model on some subsets while validating it on the remaining ones.
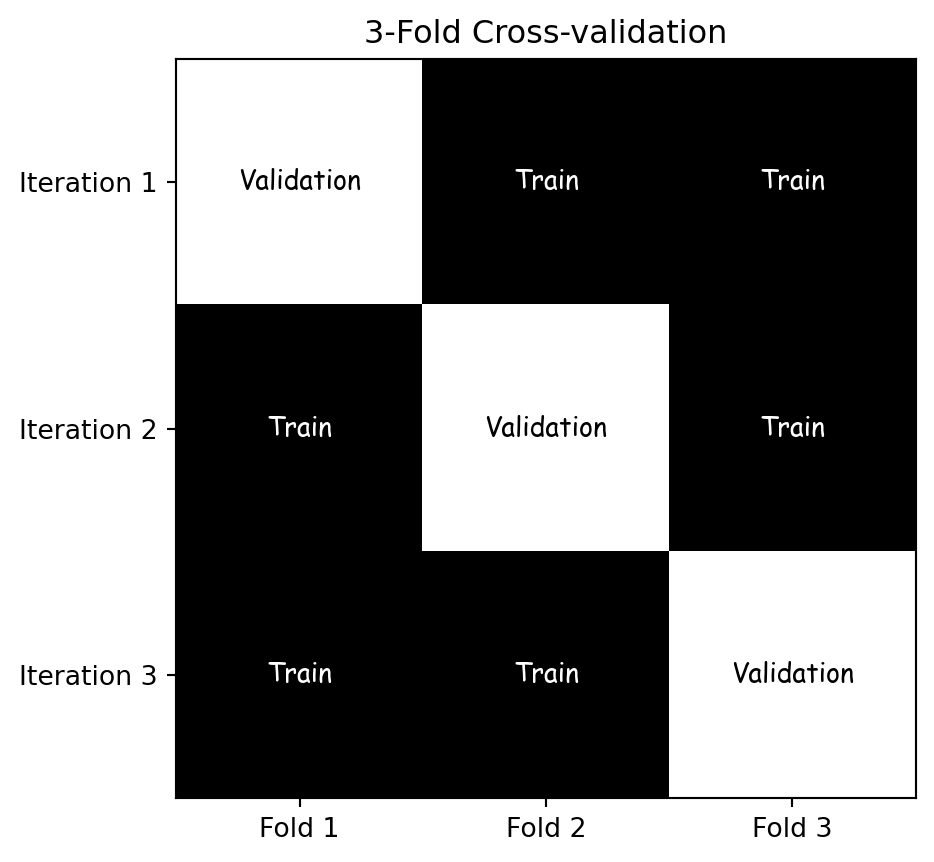
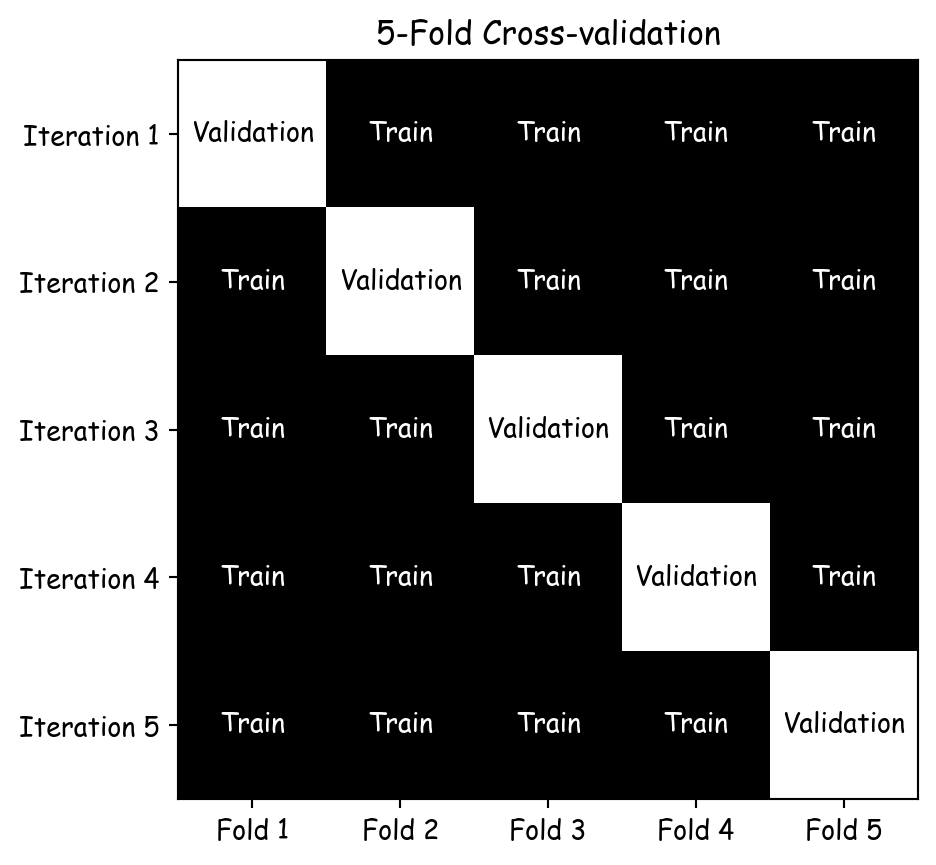
k-fold cross-validation
- Divide the dataset into \(k\) equally sized parts (folds).
- Training and validation:
- For each iteration, one fold is used as the validation set, the remaining \(k\)-1 folds are used as the training set.
- Evaluation: The model’s performance is evaluated in each iteration, resulting in \(k\) performance measures.
- Aggregation: Statistics are calculated based on \(k\) performance measures.
3-Fold Cross-validation
5-Fold Cross-validation
More Reliable Model Evaluation
- More reliable estimate of model performance compared to a single train-test split.
- Reduces the variability associated with a single split, leading to a more stable and unbiased evaluation.
- For large values of \(k\)1, consider the average, variance, and confidence interval.
Better Generalization
- Helps in assessing how the model generalizes to an independent dataset.
- It ensures that the model’s performance is not overly optimistic or pessimistic by averaging results over multiple folds.
Efficient Use of Data
- Particularly beneficial for small datasets, cross-validation ensures that every data point is used for both training and validation.
- This maximizes the use of available data, leading to more accurate and reliable model training.
Hyperparameter Tuning
- Commonly used during hyperparameter tuning, allowing for the selection of the best model parameters based on their performance across multiple folds.
- This helps in identifying the optimal configuration that balances bias and variance.
Challenges
- Computational Cost: Requires multiple model trainings.
- Leave-One-Out (LOO): Extreme case where ( k = N ).
- Class Imbalance: Folds may not represent minority classes.
- Use Stratified Cross-Validation to maintain class proportions.
- Complexity: Error-prone implementation, especially for nested cross-validation, bootstraps, or integration into larger pipelines.
cross_val_score
Scores: [0.71428571 0.66883117 0.71428571 0.79738562 0.73202614]
Mean: 0.73
Standard deviation: 0.04Hyperparameter tuning
Workflow

Workflow - implementation
Definition
A hyperparameter is a configuration external to the model that is set prior to the training process and governs the learning process, influencing model performance and complexity.
Hyperparameters - Decision Tree
criterion:gini,entropy,log_loss, measure the quality of a split.max_depth: limits the number of levels in the tree to prevent overfitting.
Hyperparameters - Logistic Regression
penalty:l1orl2, helps in preventing overfitting.solver:liblinear,newton-cg,lbfgs,sag,saga.max_iter: maximum number of iterations taken for the solvers to converge.tol: stopping criteria, smaller values mean higher precision.
Hyperparameters - KNN
n_neighbors: number of neighbors to use for \(k\)-neighbors queries.weights:uniformordistance, equal weight or distance-based weight.
Experiment: max_depth
max_depth = 3
Mean: 0.74
Standard deviation: 0.04
max_depth = 5
Mean: 0.76
Standard deviation: 0.04
max_depth = 7
Mean: 0.73
Standard deviation: 0.04
max_depth = None
Mean: 0.71
Standard deviation: 0.05Experiment: criterion
criterion = gini
Mean: 0.76
Standard deviation: 0.04
criterion = entropy
Mean: 0.75
Standard deviation: 0.05
criterion = log_loss
Mean: 0.75
Standard deviation: 0.05Experiment: n_neighbors
from sklearn.neighbors import KNeighborsClassifier
for value in range(1, 11):
clf = KNeighborsClassifier(n_neighbors=value)
clf_scores = cross_val_score(clf, X_train, y_train, cv=10)
print("\nn_neighbors = ", value)
print(f"Mean: {clf_scores.mean():.2f}")
print(f"Standard deviation: {clf_scores.std():.2f}")Experiment: n_neighbors
n_neighbors = 1
Mean: 0.67
Standard deviation: 0.05
n_neighbors = 2
Mean: 0.71
Standard deviation: 0.03
n_neighbors = 3
Mean: 0.69
Standard deviation: 0.05
n_neighbors = 4
Mean: 0.73
Standard deviation: 0.03
n_neighbors = 5
Mean: 0.72
Standard deviation: 0.03
n_neighbors = 6
Mean: 0.73
Standard deviation: 0.05
n_neighbors = 7
Mean: 0.74
Standard deviation: 0.04
n_neighbors = 8
Mean: 0.75
Standard deviation: 0.04
n_neighbors = 9
Mean: 0.73
Standard deviation: 0.05
n_neighbors = 10
Mean: 0.73
Standard deviation: 0.04Experiment: weights
from sklearn.neighbors import KNeighborsClassifier
for value in ["uniform", "distance"]:
clf = KNeighborsClassifier(n_neighbors=5, weights=value)
clf_scores = cross_val_score(clf, X_train, y_train, cv=10)
print("\nweights = ", value)
print(f"Mean: {clf_scores.mean():.2f}")
print(f"Standard deviation: {clf_scores.std():.2f}")
weights = uniform
Mean: 0.72
Standard deviation: 0.03
weights = distance
Mean: 0.73
Standard deviation: 0.04Hyperparameter Tuning: Grid Search
Many hyperparameters need tuning
- Major disadvantage of ML algorithms
Manual exploration of combinations is tedious
Grid search is more systematic
Enumerate all possible hyperparameter combinations
Train on training set, evaluate on validation set
GridSearchCV
from sklearn.model_selection import GridSearchCV
param_grid = [
{'max_depth': range(1, 10),
'criterion': ["gini", "entropy", "log_loss"]}
]
clf = tree.DecisionTreeClassifier()
grid_search = GridSearchCV(clf, param_grid, cv=5)
grid_search.fit(X_train, y_train)
(grid_search.best_params_, grid_search.best_score_)({'criterion': 'gini', 'max_depth': 5}, np.float64(0.7481910124074653))GridSearchCV
({'n_neighbors': 14, 'weights': 'uniform'}, np.float64(0.7554165363361485))GridSearchCV
from sklearn.linear_model import LogisticRegression
# 2 * 5 * 5 * 3 = 150 tests!
param_grid = [
{'penalty': ["l1", "l2", None],
'solver' : ['liblinear', 'newton-cg', 'lbfgs', 'sag', 'saga'],
'max_iter' : [100, 200, 400, 800, 1600],
'tol' : [0.01, 0.001, 0.0001]}
]
clf = LogisticRegression()
grid_search = GridSearchCV(clf, param_grid, cv=5)
grid_search.fit(X_train, y_train)
(grid_search.best_params_, grid_search.best_score_)({'max_iter': 100, 'penalty': 'l2', 'solver': 'newton-cg', 'tol': 0.001},
np.float64(0.7756646856427901))Randomized Search
- Large number of combinations (many hyperparameters, many values)
- Use RandomizedSearchCV:
- Supply list of values or probability distribution for hyperparameters
- Specify number of iterations (combinations to try)
- Predictable execution time
Workflow
Finally, we proceed with testing
precision recall f1-score support
0 0.83 0.83 0.83 52
1 0.64 0.64 0.64 25
accuracy 0.77 77
macro avg 0.73 0.73 0.73 77
weighted avg 0.77 0.77 0.77 77
Prologue
Summary
- Training Set Size: Impact on model efficacy and generalization.
- Attribute Encoding: Evaluation of techniques to capture biological phenomena.
- Preprocessing:
- Data Scaling
- Handling Missing Values
- Managing Class Imbalance
Next lecture
- We will further discuss machine learning engineering.
References
Marcel Turcotte
School of Electrical Engineering and Computer Science (EECS)
University of Ottawa