Introduction à l’apprentissage automatique
CSI 4506 - Automne 2025
Version: sept. 9, 2025 10h13
Citation du jour

Citation du jour (suite)

Yoshua Bengio, Université de Montréal, a été à nouveau reconnu par TIME comme l’une des personnes les plus influentes dans le domaine de l’intelligence artificielle.
Justification
Pourquoi un programme informatique devrait-il apprendre ?

Concepts

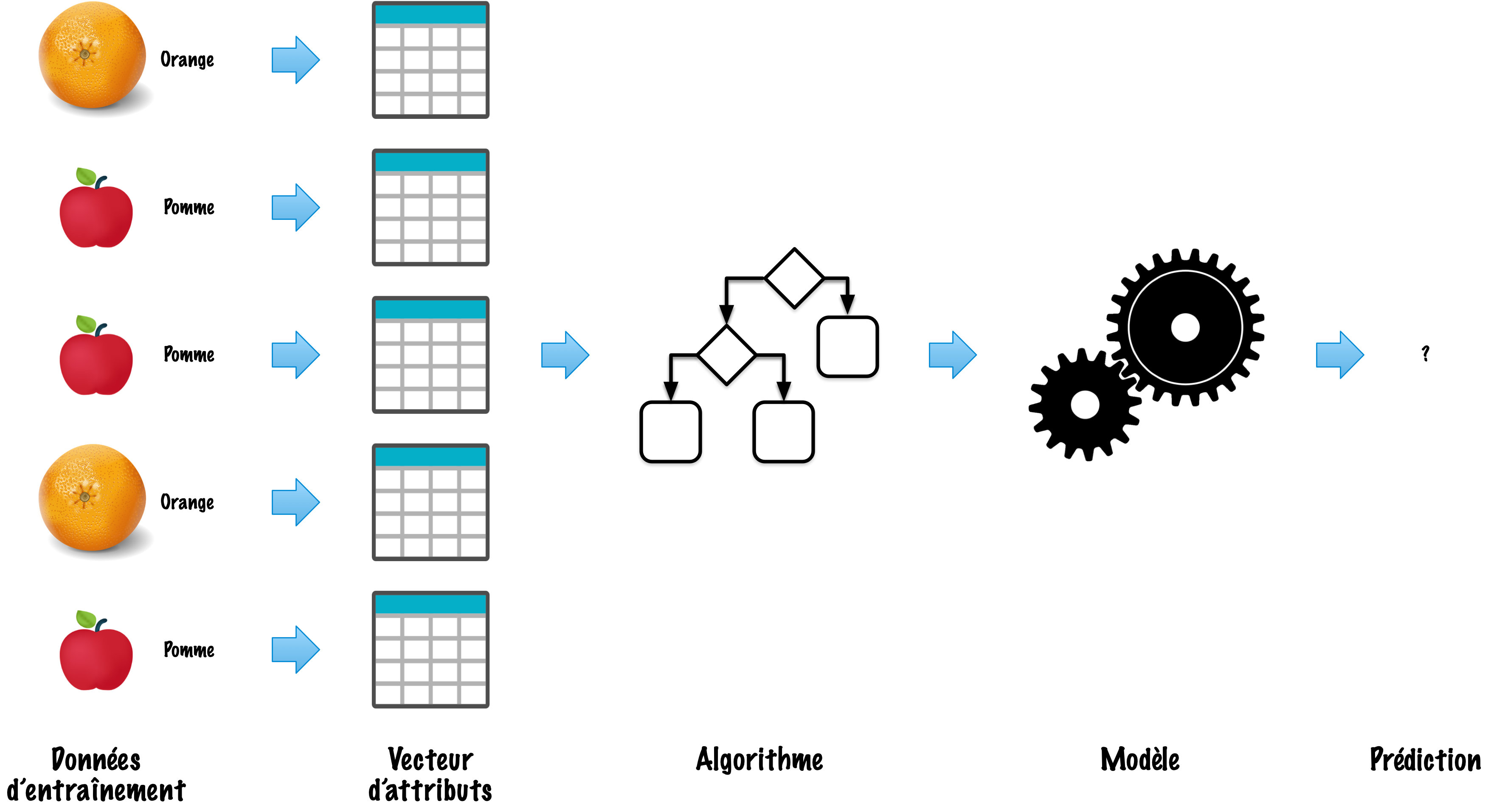
Apprentissage (construction)
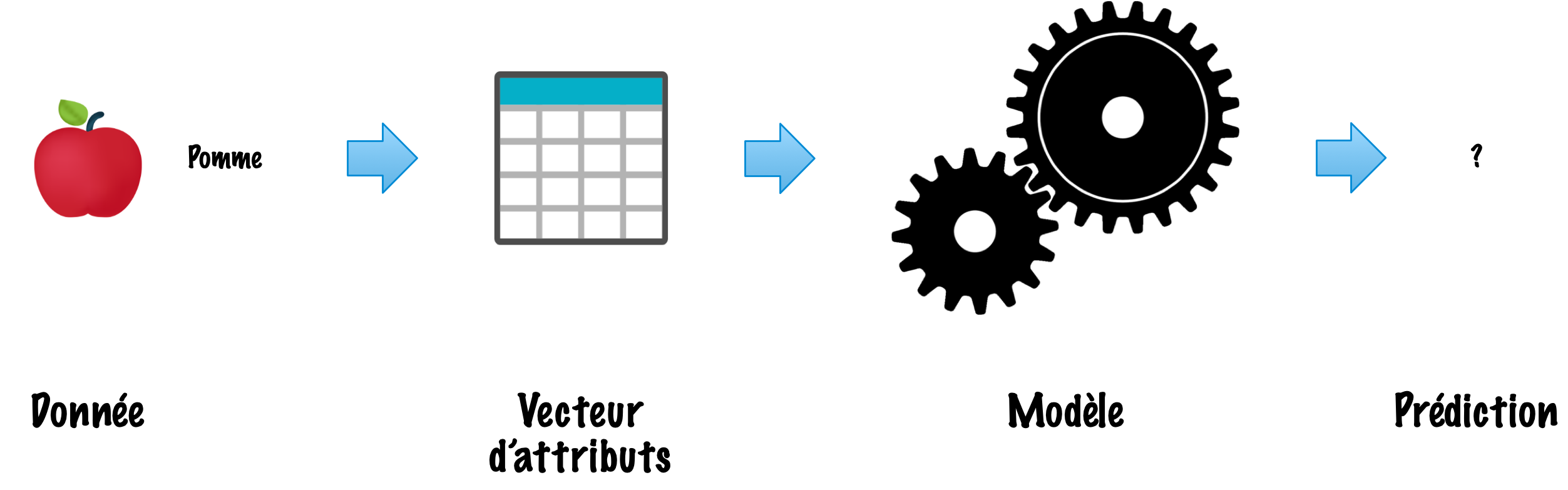
Inférence (utilisation du modèle)
1. Problème : Vont-ils mordre aujourd’hui ?
Objectif : Développer un modèle prédictif pour évaluer la probabilité de succès d’une journée de pêche, classée en trois catégories : ‘Médiocre’, ‘Moyenne’ ou ‘Excellente’.

Scikit-learn

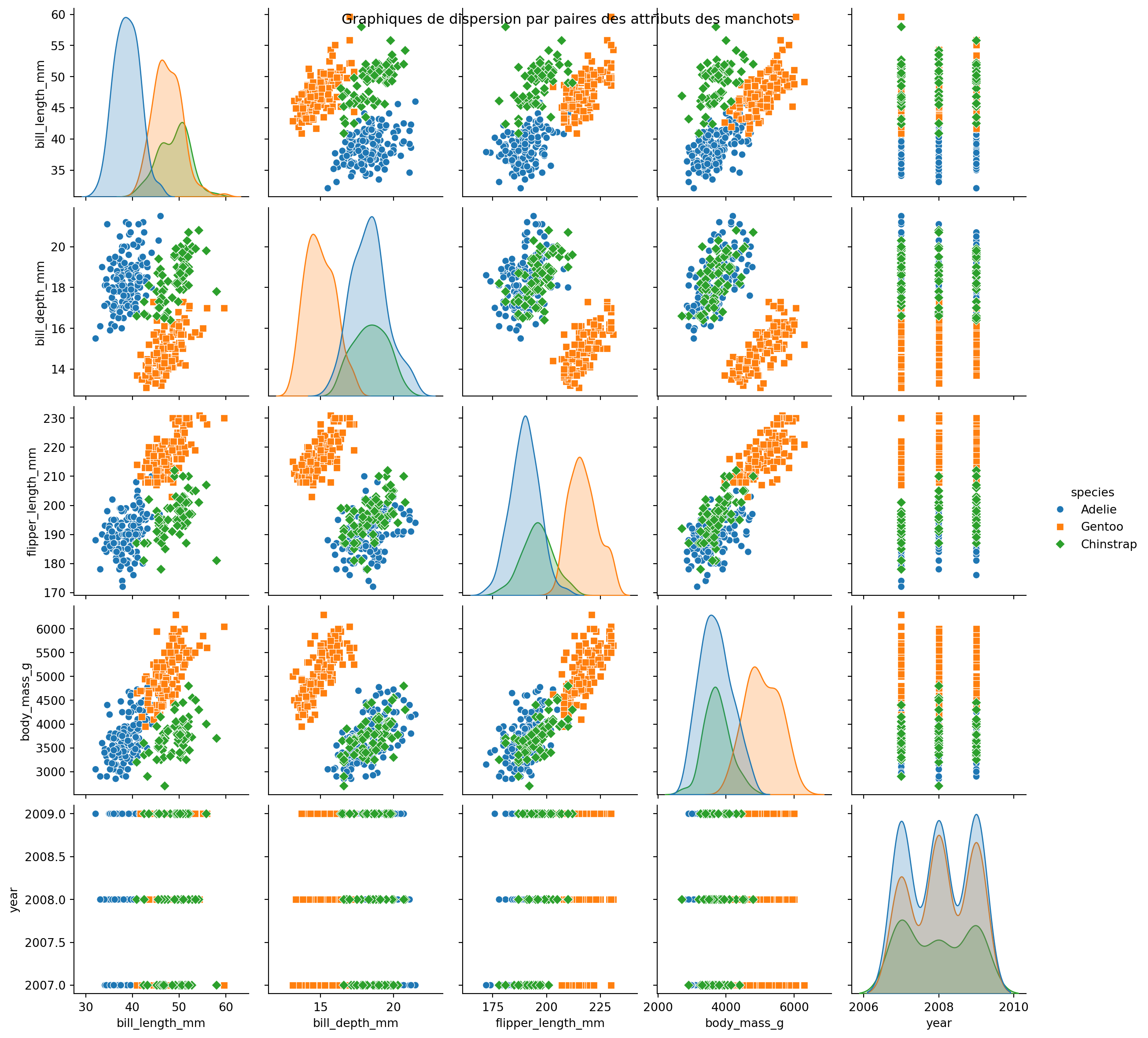
Exemple : Manchots de Palmer

Exemple : Visualisation (1/2)
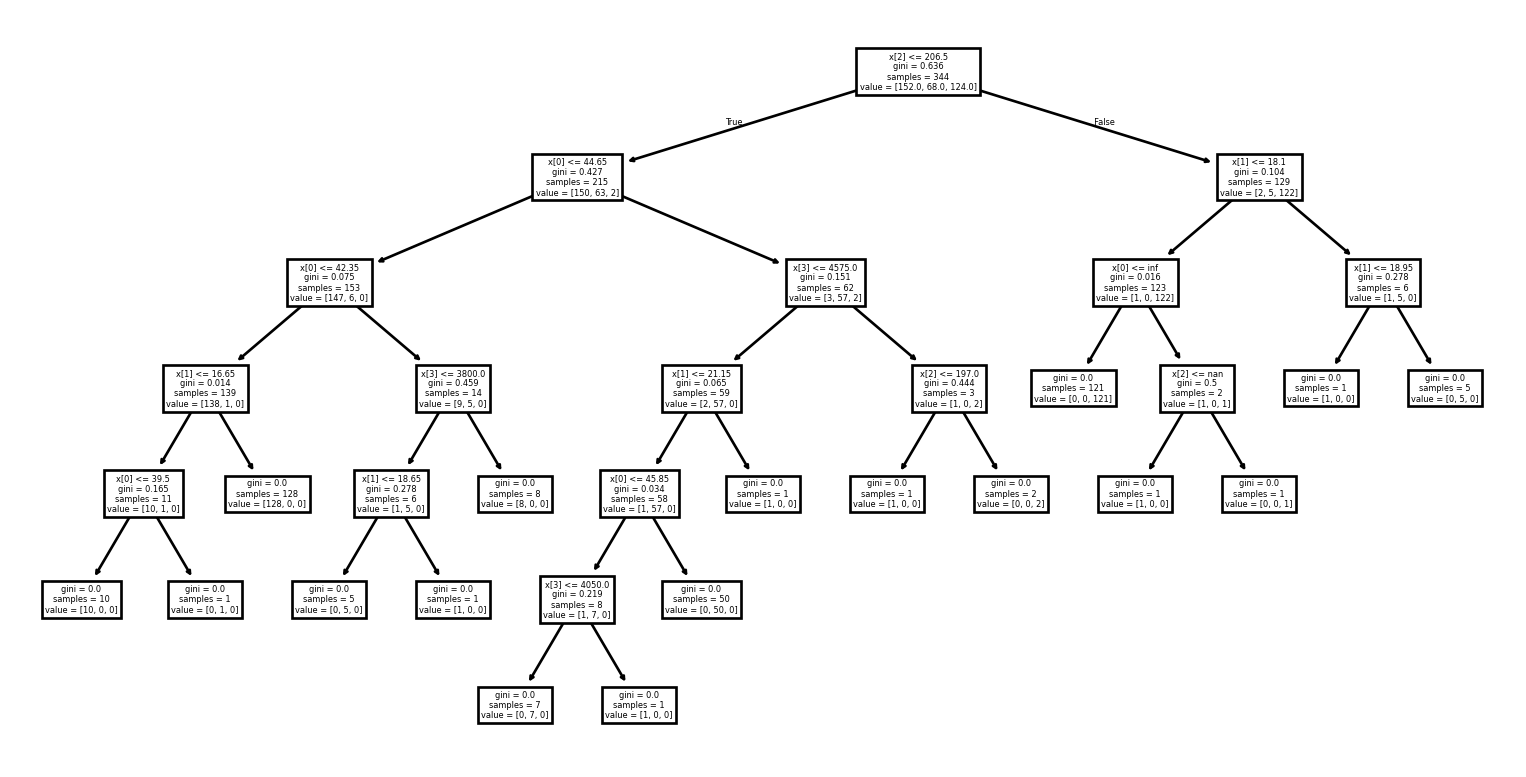
Exemple : Visualisation (2/2)
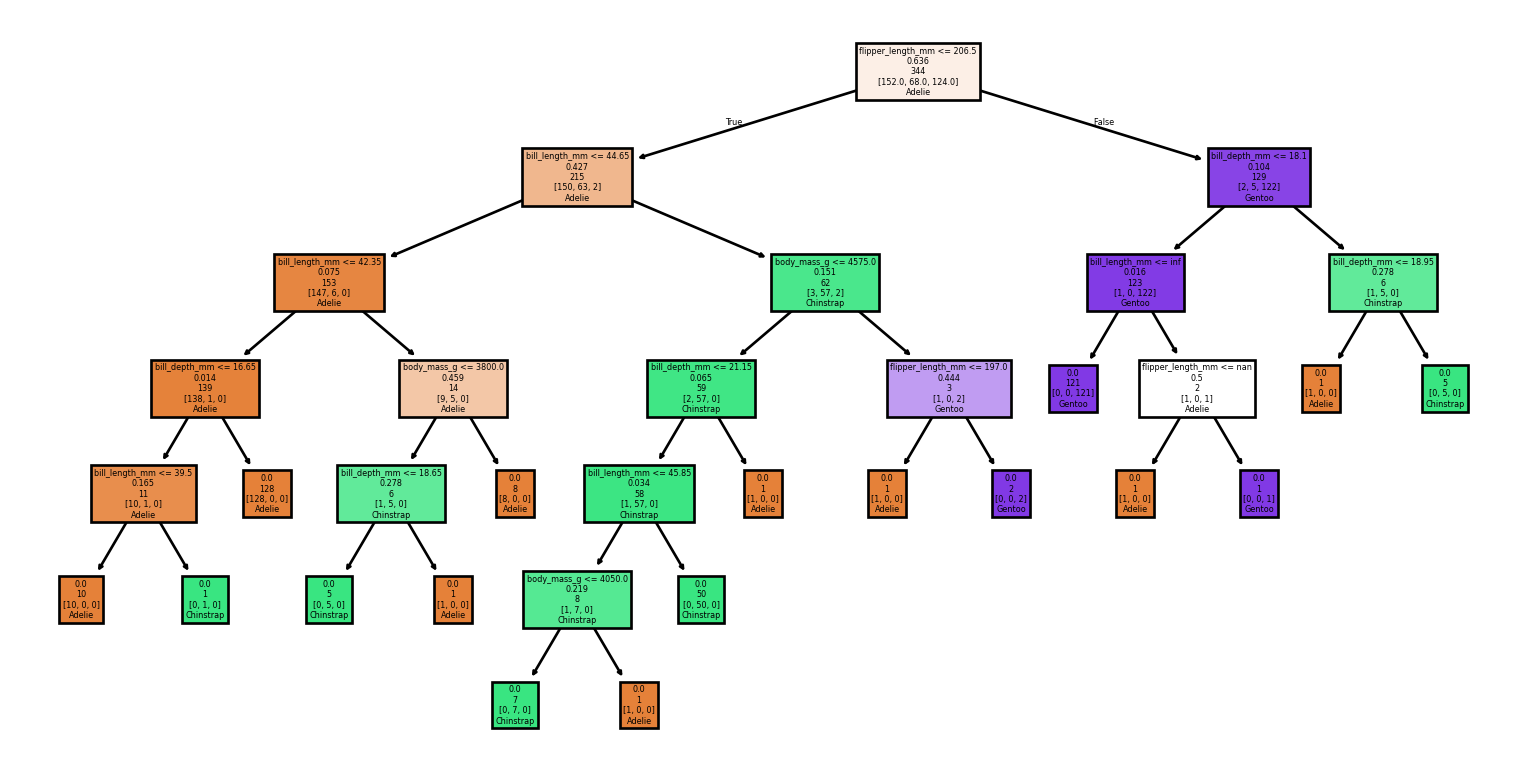
Exemple : Complet
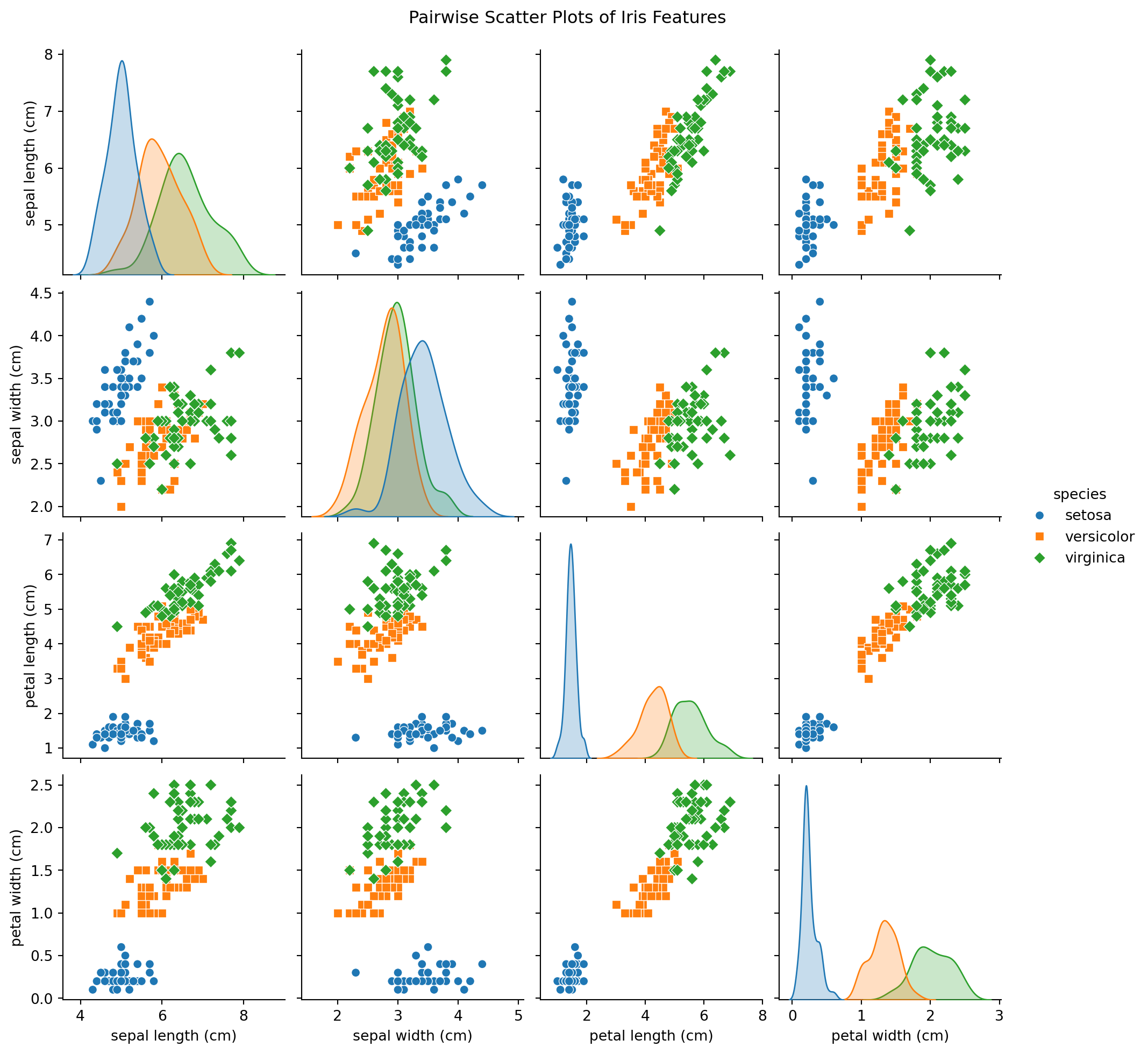
Exemple : Utilisation de Seaborn
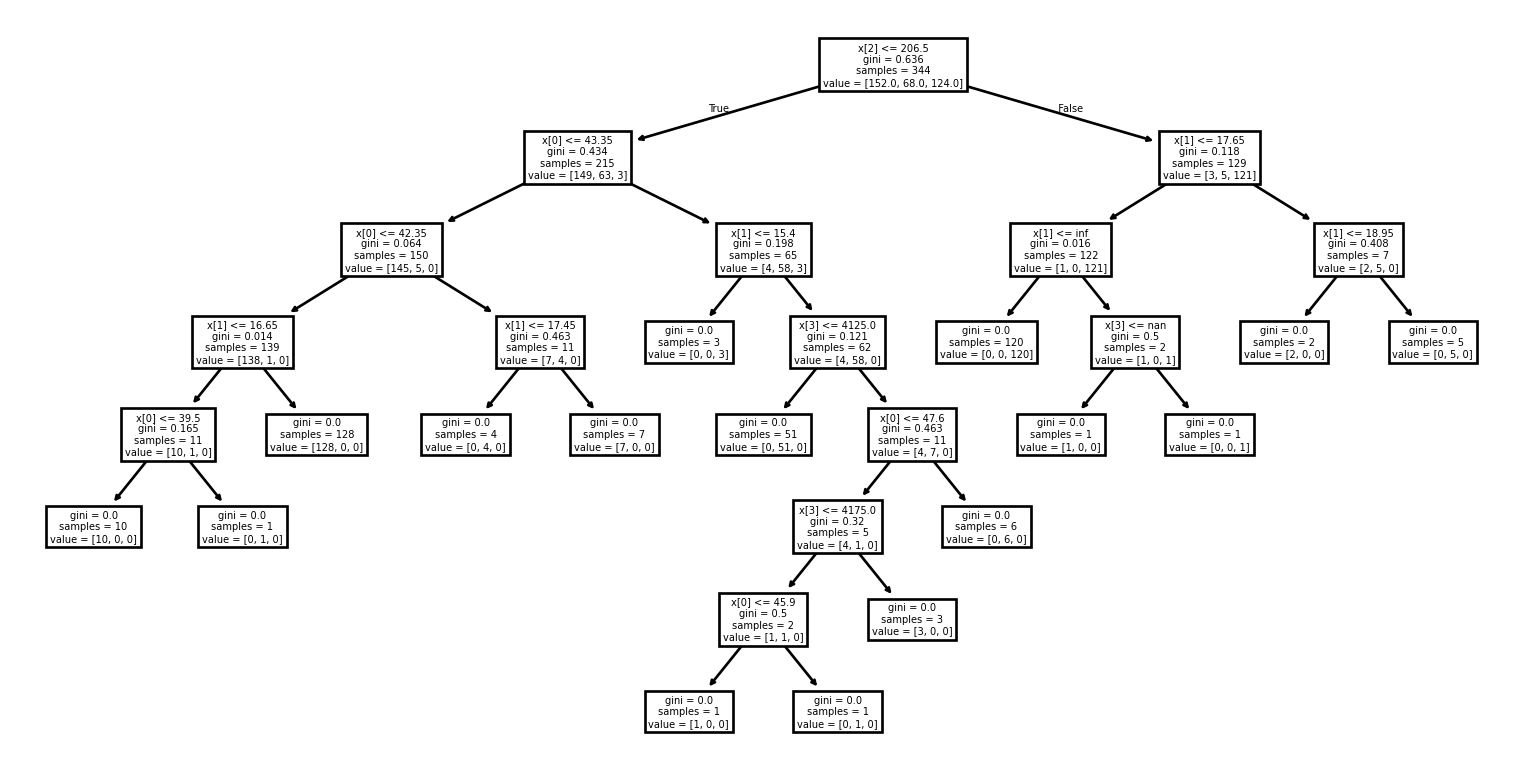
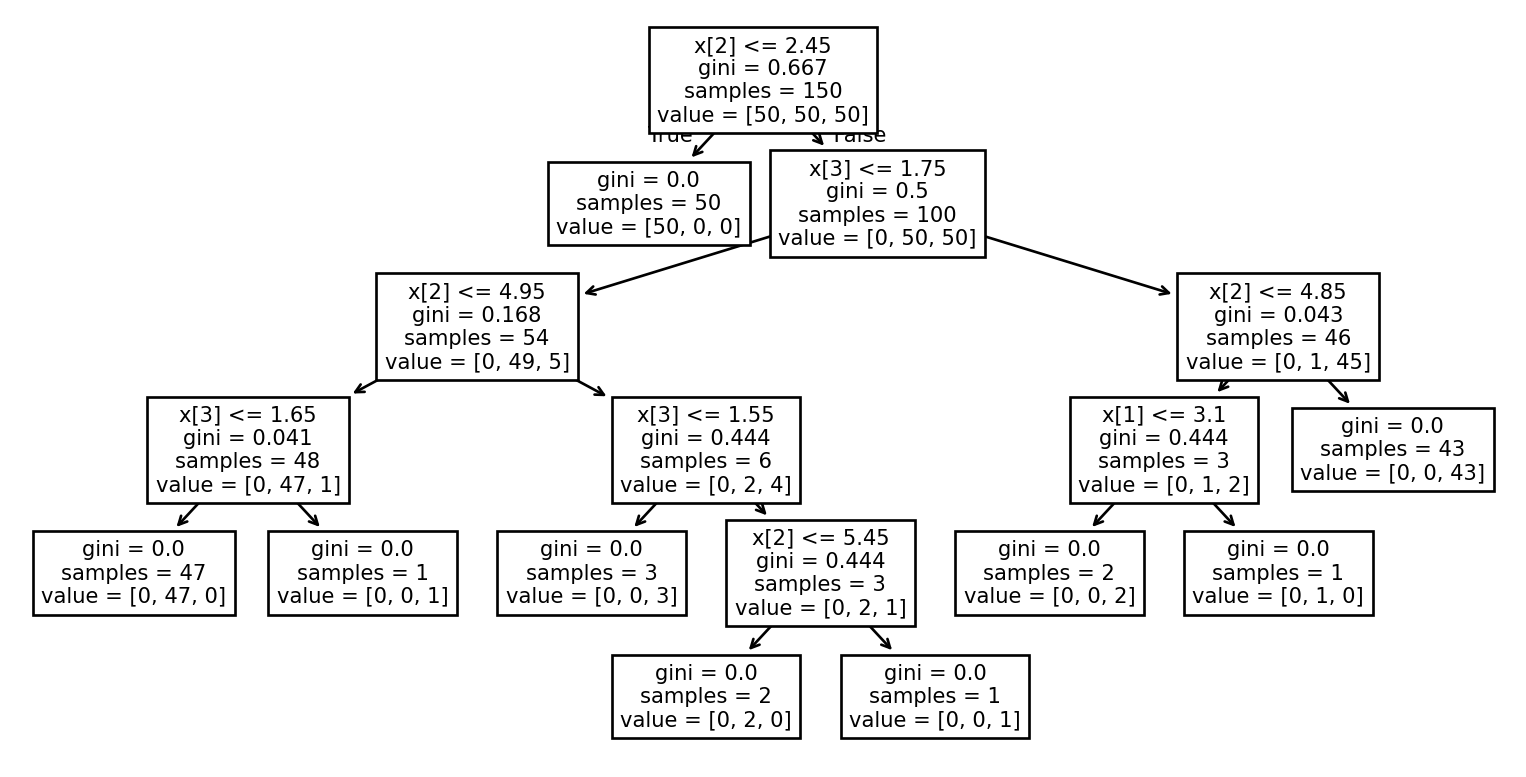
Exemple : Visualisation de l’arbre
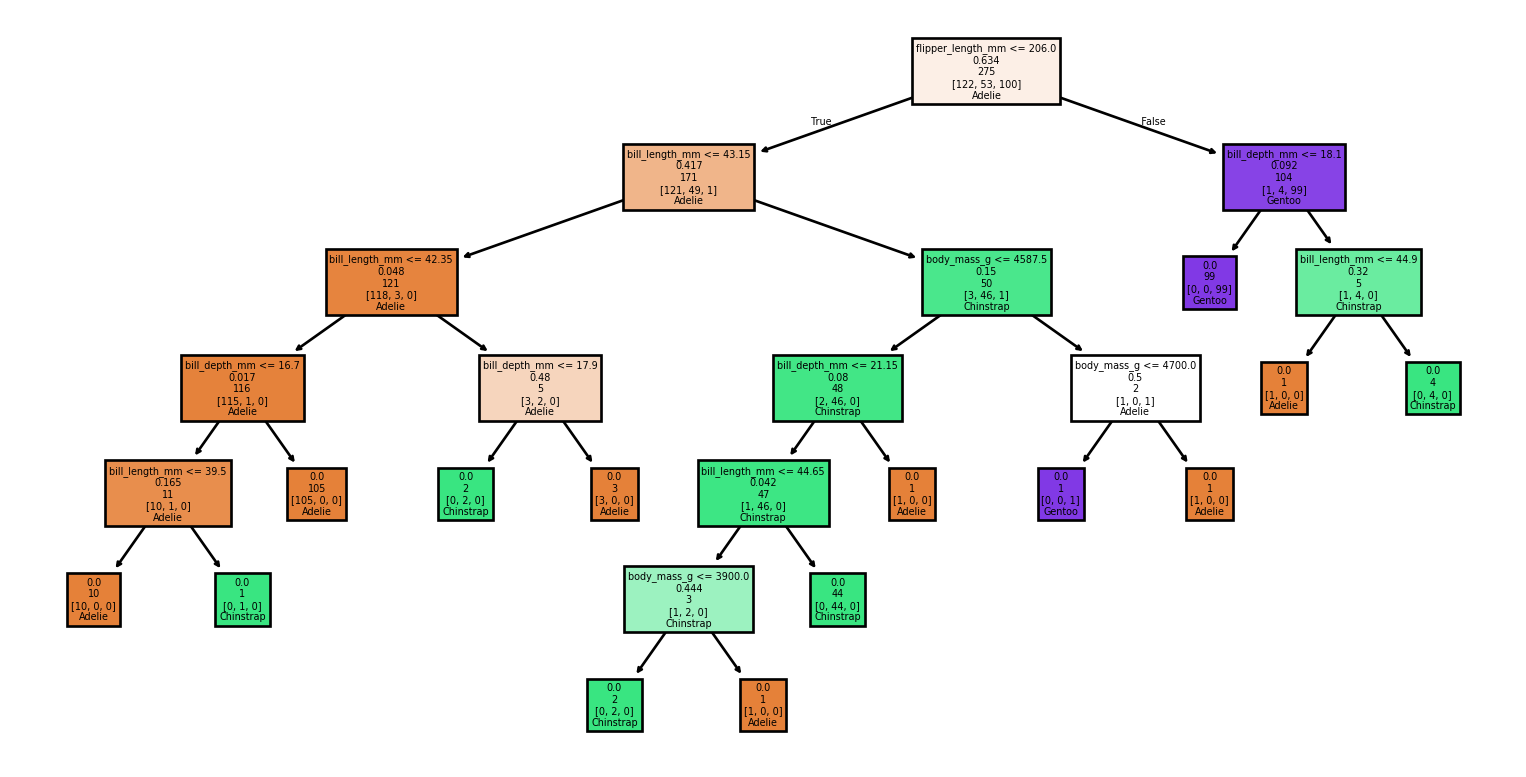
Lectures supplémentaires (1/3)

- The Hundred-Page Machine Learning Book (Burkov 2019) est un manuel succinct et ciblé qui peut être lu en une semaine, ce qui en fait une excellente ressource d’introduction.
- Disponible sous un modèle « lire d’abord, acheter ensuite », permettant aux lecteurs d’évaluer son contenu avant de l’acheter.
- Son auteur, Andriy Burkov, a obtenu son doctorat en IA à l’Université Laval.
Lectures supplémentaires (2/3)

- Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow (Géron 2022) fournit des exemples pratiques et exploite des frameworks Python prêts pour la production.
- La couverture complète inclut non seulement les modèles, mais aussi des bibliothèques pour le réglage des hyperparamètres, le prétraitement des données et la visualisation.
- Exemples de code et solutions aux exercices disponibles sous forme de Jupyter Notebooks sur GitHub.
- Aurélien Géron est un ancien chef de produit YouTube, qui a dirigé la classification vidéo pour la recherche et la découverte.
Lectures supplémentaires (3/3)

- Mathematics for Machine Learning (Deisenroth, Faisal, et Ong 2020) vise à fournir les compétences mathématiques nécessaires pour lire des livres sur l’apprentissage automatique.
- PDF du livre
- “Ce livre offre une excellente couverture de tous les concepts mathématiques de base pour l’apprentissage automatique. J’ai hâte de le partager avec les étudiants, les collègues et toute personne intéressée à acquérir une compréhension solide des fondamentaux.” Joelle Pineau, Université McGill et Facebook
Exemple: iris data set

Exemple: Visualiser l’arbre (1/2)
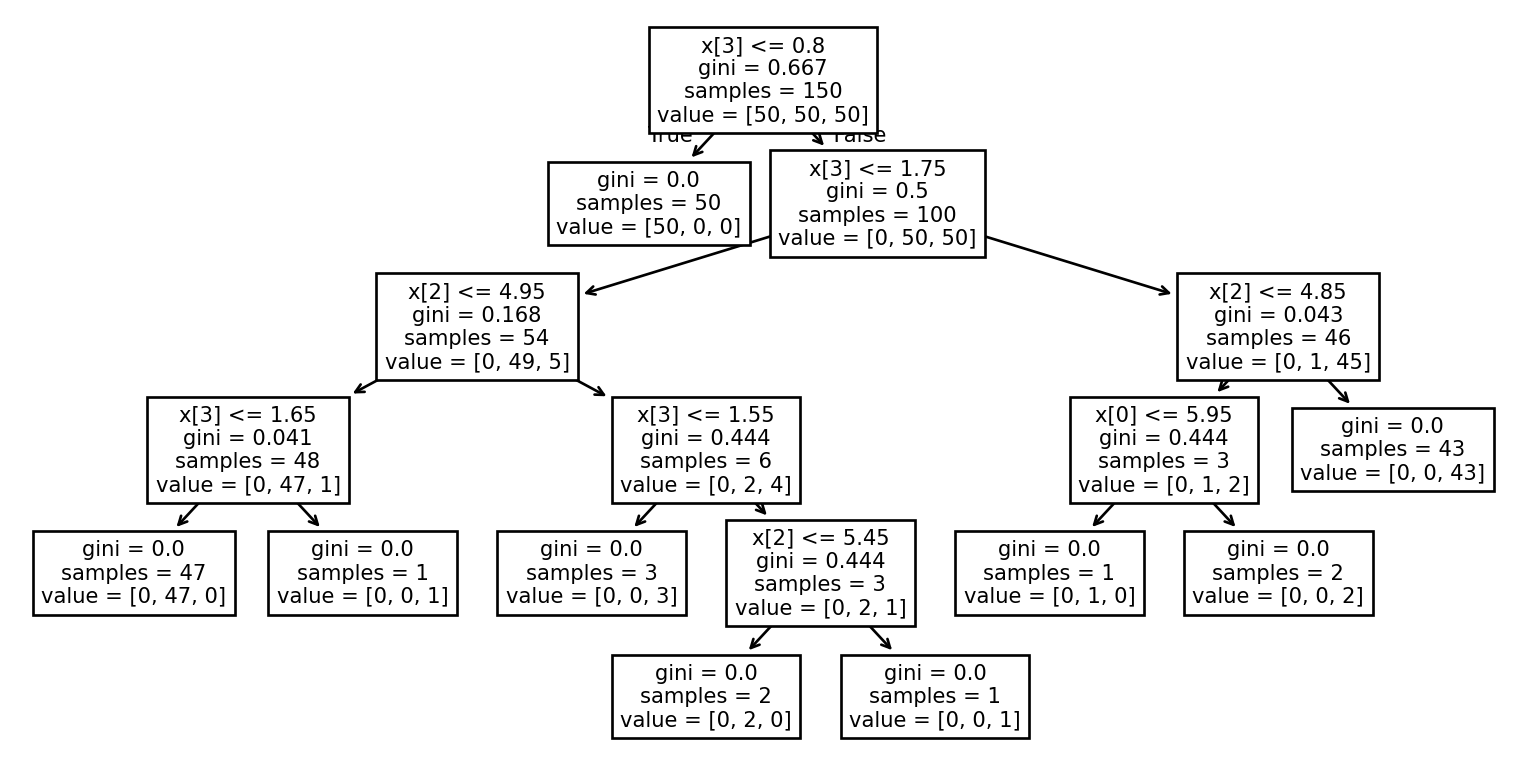
Exemple: Visualiser l’arbre (2/2)

Exemple: Complet
Exemple: Utilisant Seaborn
{kind=link}