# Chargement de notre jeu de données
try:
from palmerpenguins import load_penguins
except:
! pip install palmerpenguins
from palmerpenguins import load_penguins
penguins = load_penguins()
# Pairplot avec seaborn
import matplotlib.pyplot as plt
import seaborn as sns
sns.pairplot(penguins, hue='species', markers=["o", "s", "D"])
plt.suptitle("Graphiques de dispersion par paires des attributs des manchots")
plt.show()Algorithmes d’apprentissage
CSI 4506 - automne 2025
Version: sept. 16, 2025 10h03
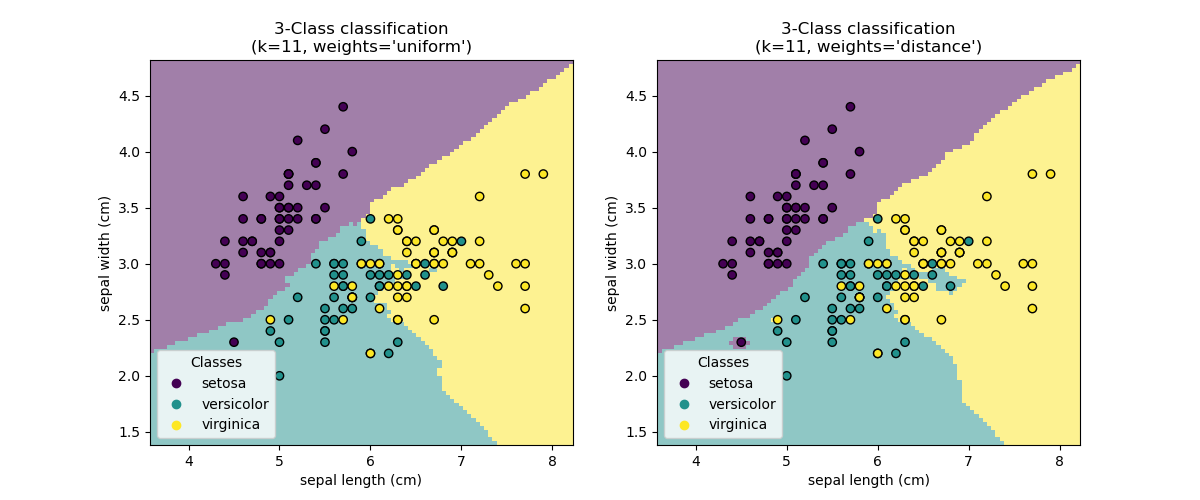
k-plus-proches voisins
Interprétable
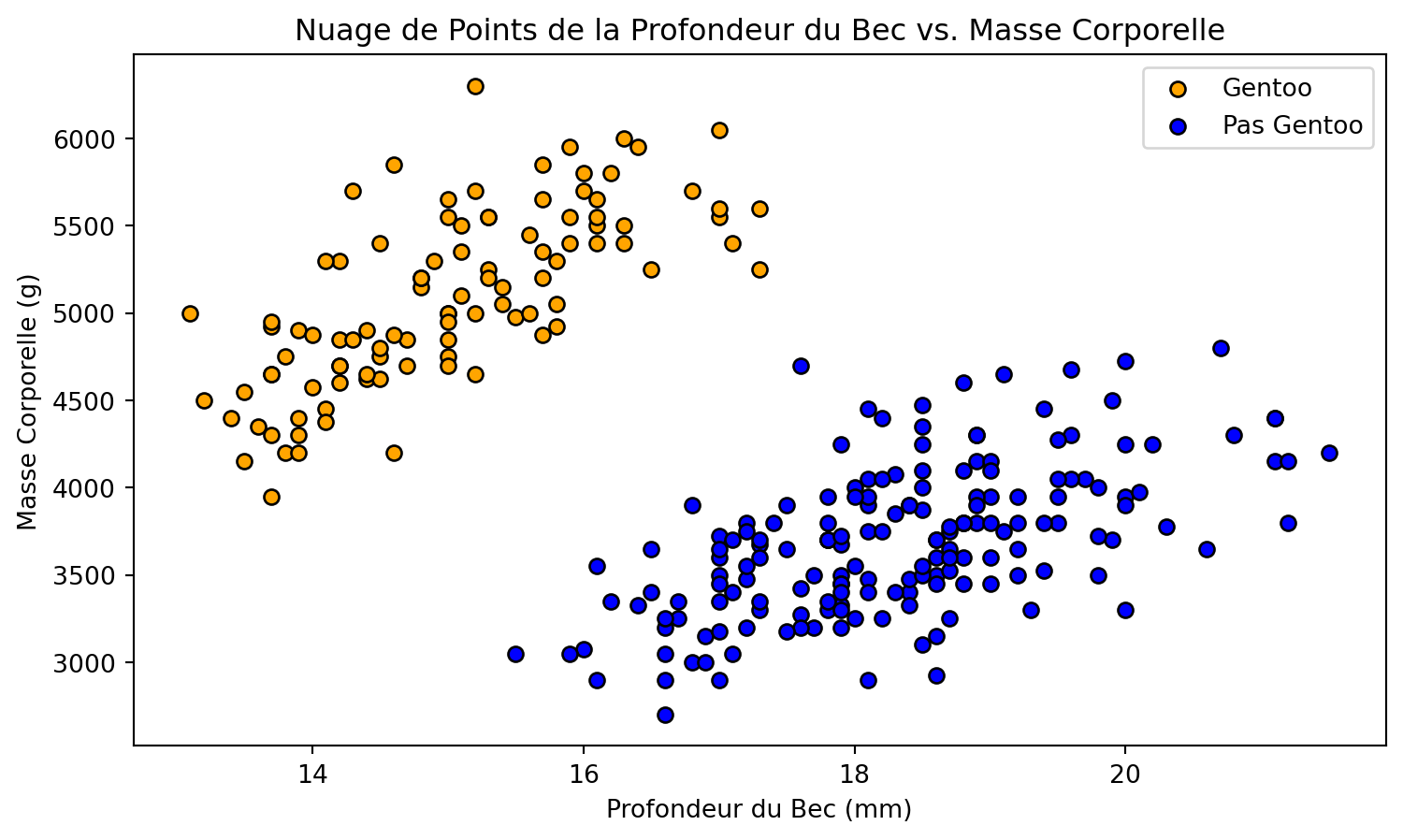
Manchots de Palmer
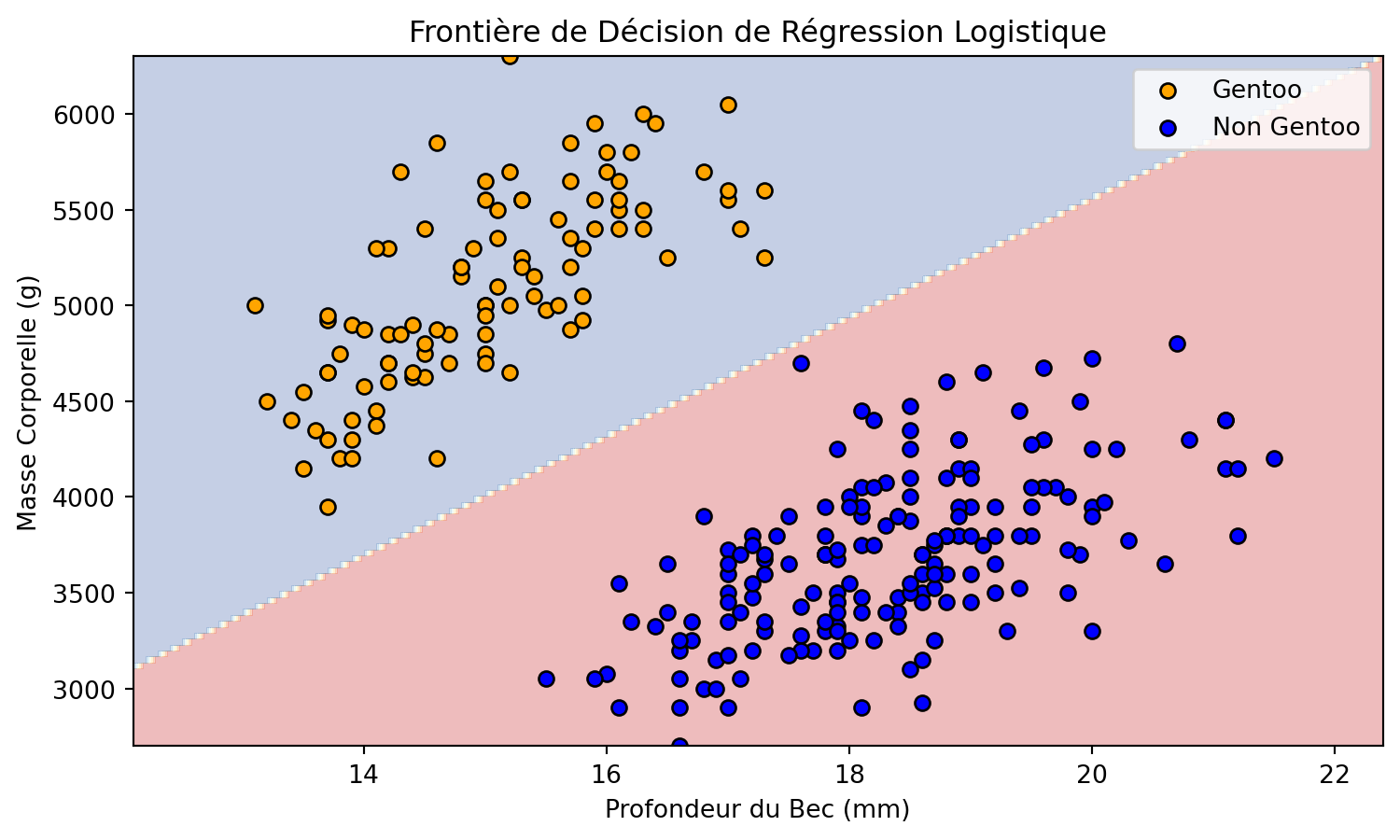
Frontière de décision
Frontière de décision
Frontière de décision simple

(a) données d’entraînement, (b) courbe quadratique, et (c) fonction linéaire.
Attribution : (Geurts, Irrthum, et Wehenkel 2009)
Frontière de décision complexe
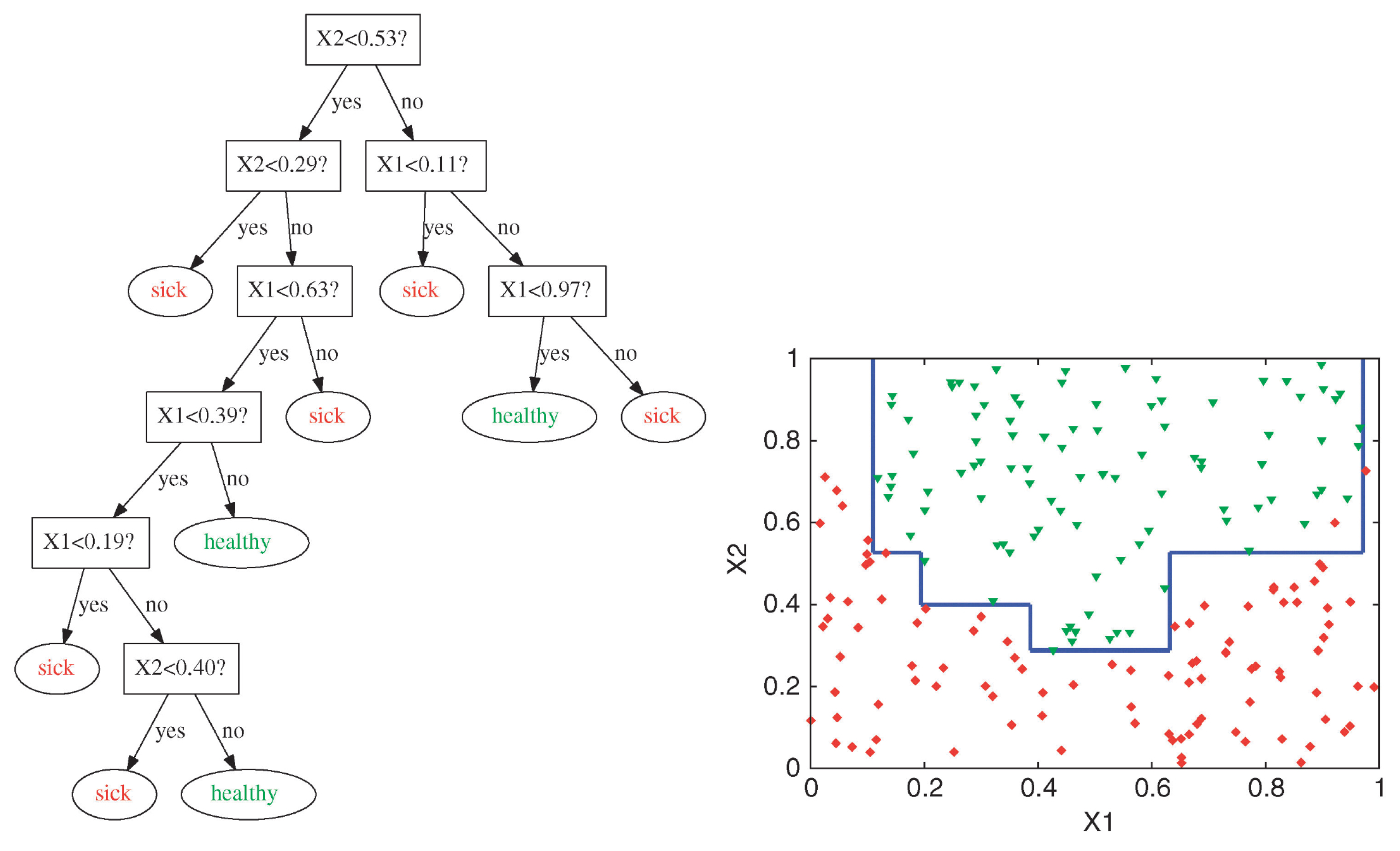
Les arbres de décision sont capables de générer des frontières de décision irrégulières et non linéaires.
Attribution : ibidem.
Indice de Gini
Code
def gini_index(p):
"""Calculer l'indice de Gini."""
return 1 - (p**2 + (1 - p)**2)
# Valeurs de probabilité pour la classe 1
p_values = np.linspace(0, 1, 100)
# Calculer l'indice de Gini pour chaque probabilité
gini_values = [gini_index(p) for p in p_values]
# Tracer l'indice de Gini
plt.figure(figsize=(8, 6))
plt.plot(p_values, gini_values, label='Indice de Gini', color='b')
plt.title('Indice de Gini pour une Classification Binaire')
plt.xlabel('Probabilité de la Classe 1 (p)')
plt.ylabel('Indice de Gini')
plt.grid(True)
plt.legend()
plt.show()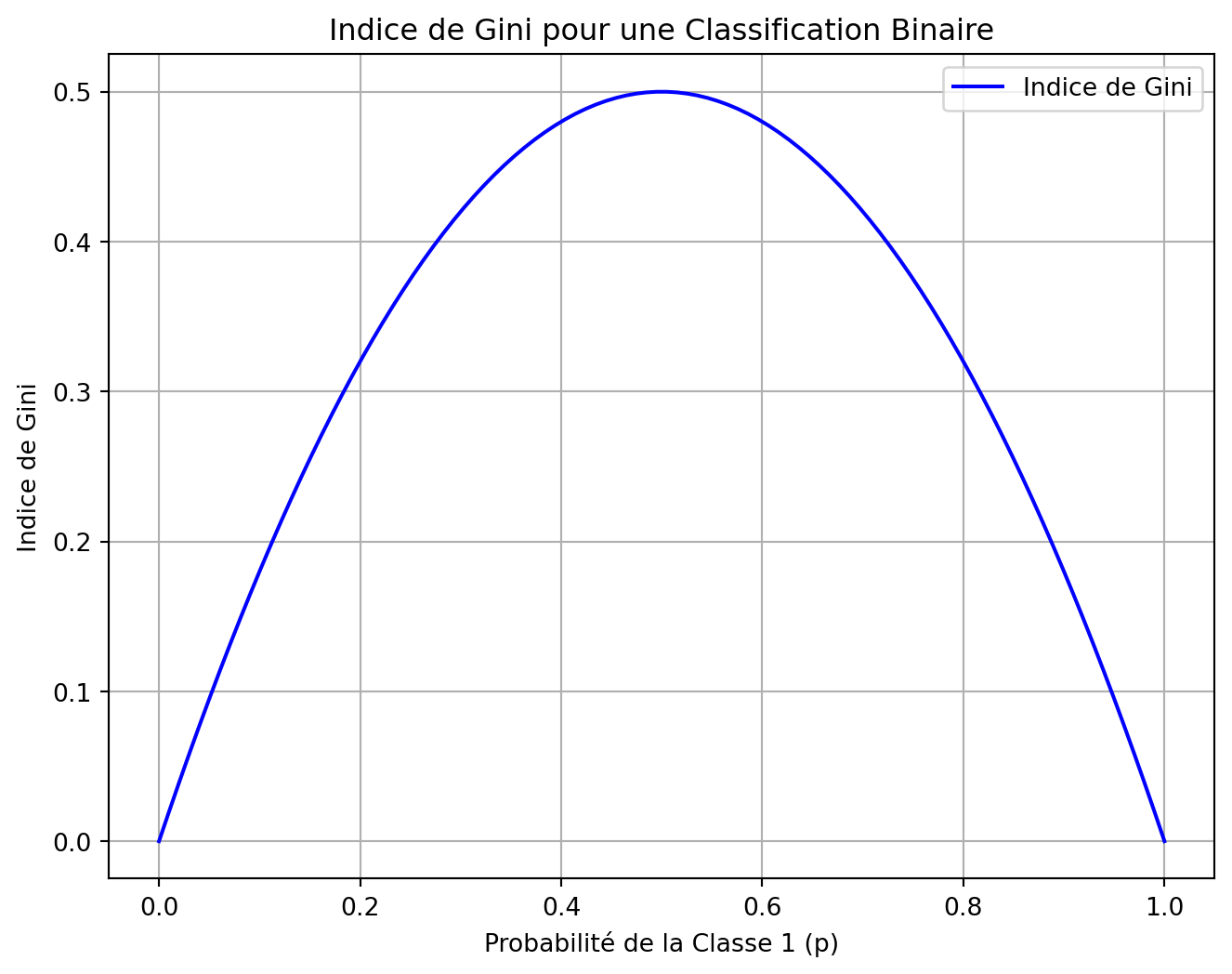
Jeu de données Iris
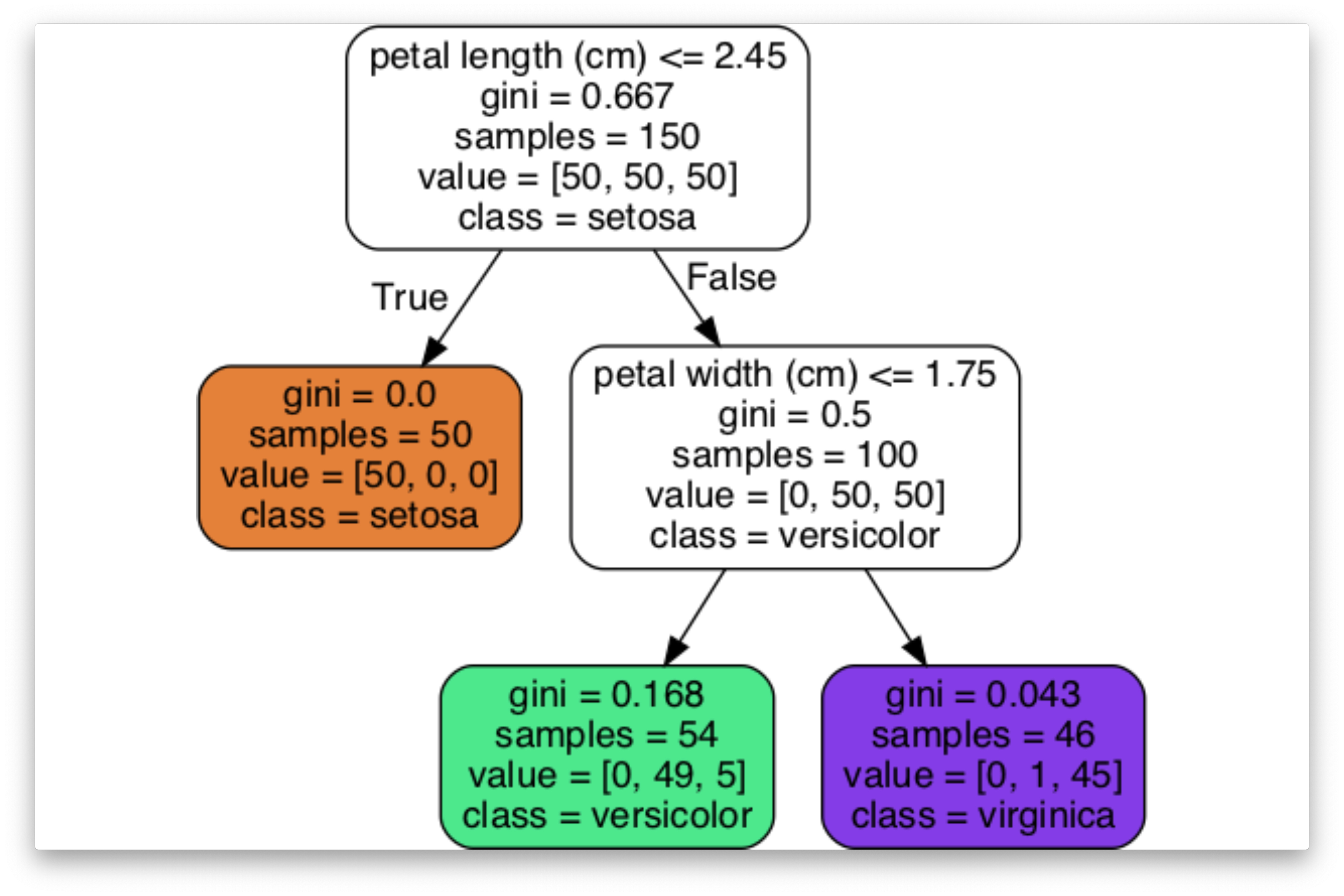
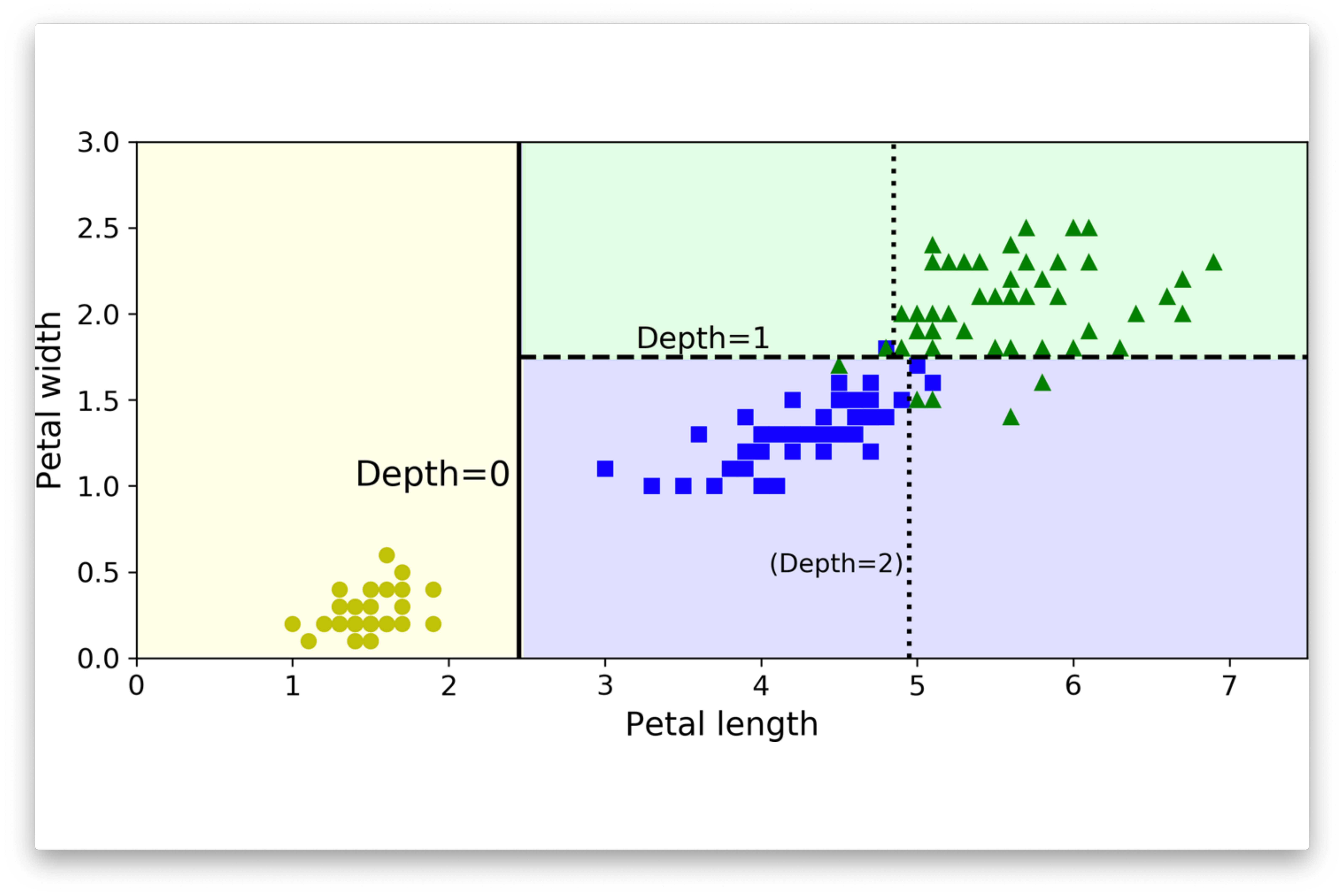
Arbres de grande taille
Petits changements dans l’ensemble de données
Seed: 4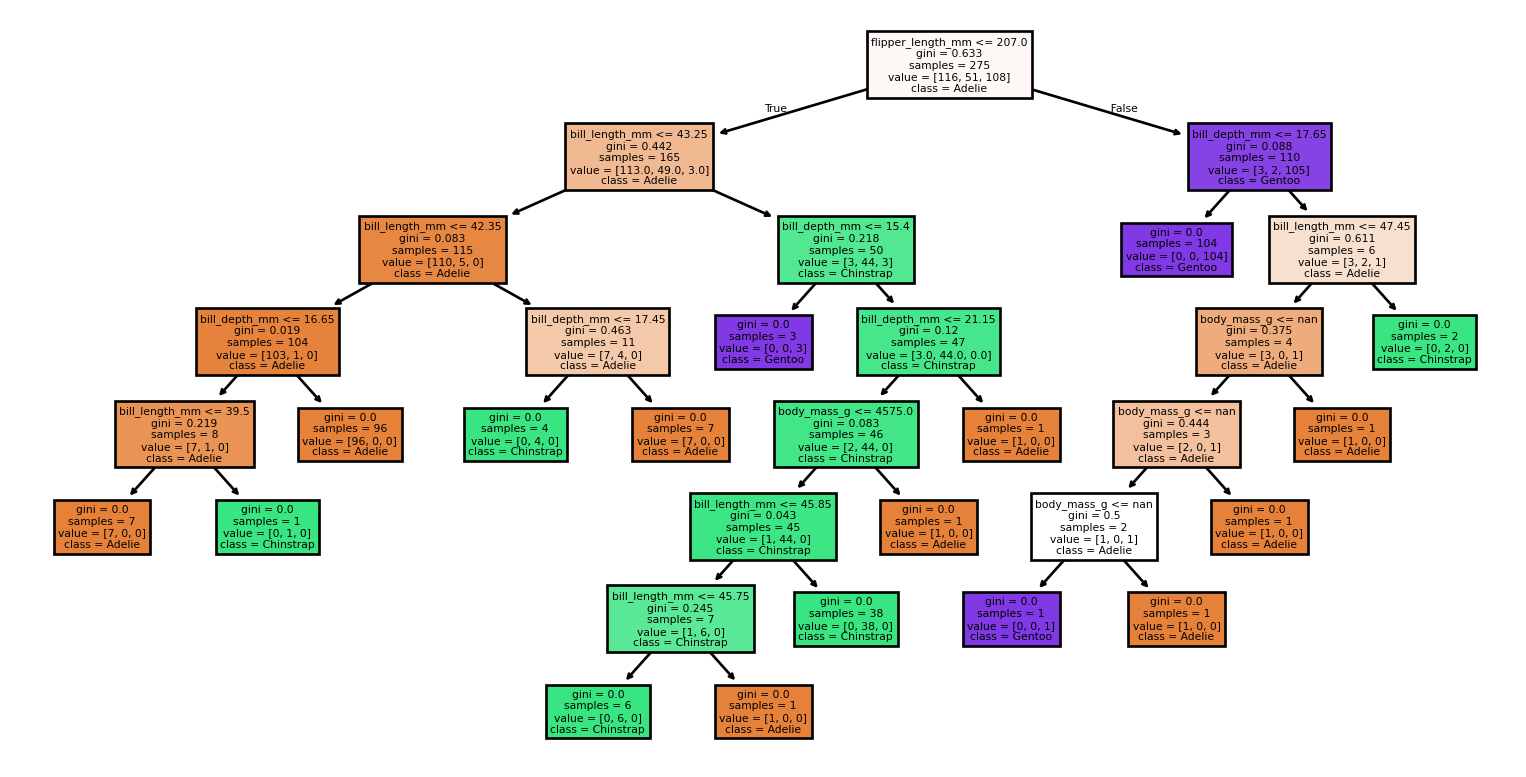
Accuracy: 0.99
Rapport de Classification:
precision recall f1-score support
Adelie 1.00 0.97 0.99 36
Chinstrap 0.94 1.00 0.97 17
Gentoo 1.00 1.00 1.00 16
accuracy 0.99 69
macro avg 0.98 0.99 0.99 69
weighted avg 0.99 0.99 0.99 69
Seed: 7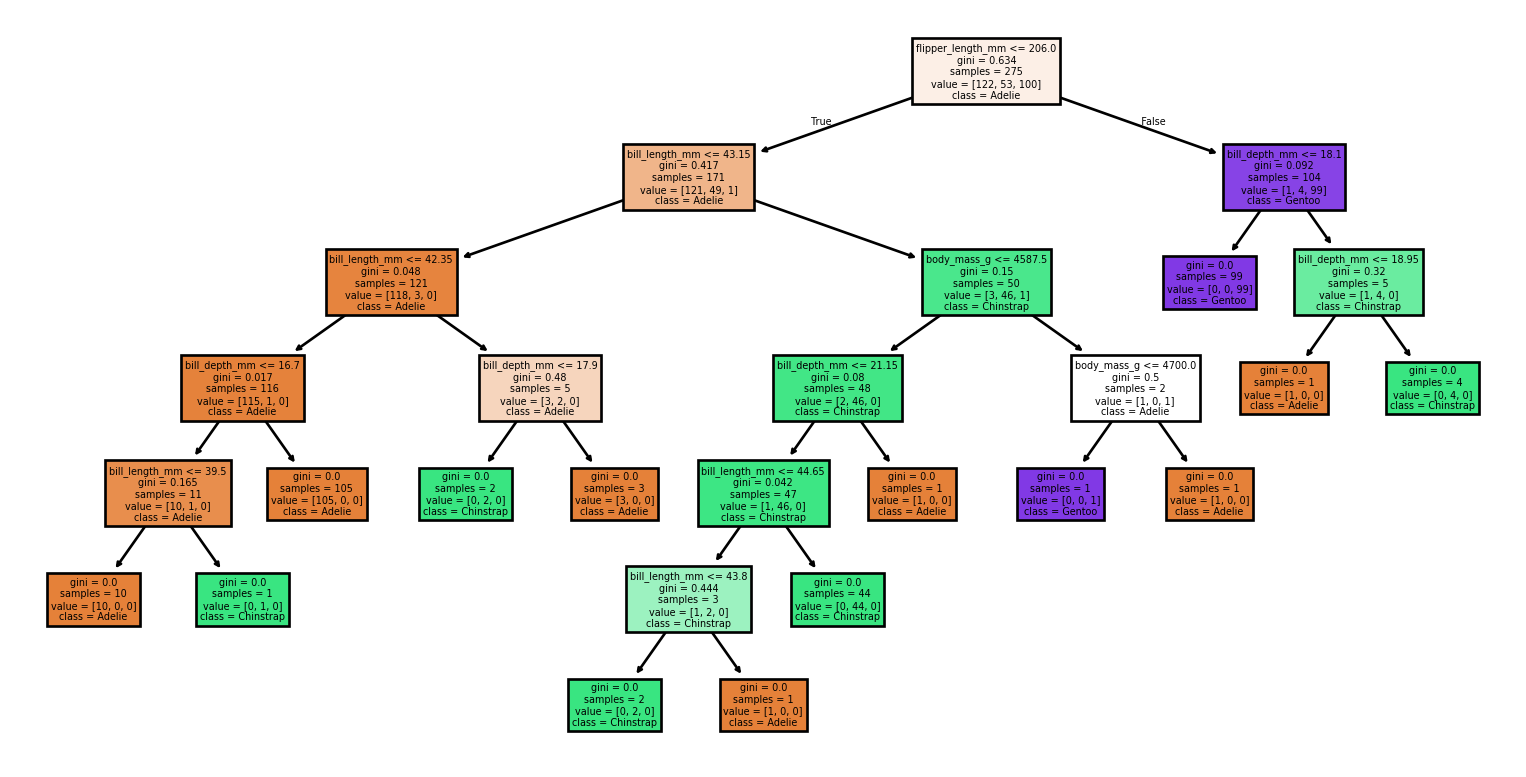
Accuracy: 0.91
Rapport de Classification:
precision recall f1-score support
Adelie 0.96 0.83 0.89 30
Chinstrap 0.83 1.00 0.91 15
Gentoo 0.92 0.96 0.94 24
accuracy 0.91 69
macro avg 0.90 0.93 0.91 69
weighted avg 0.92 0.91 0.91 69
Seed: 90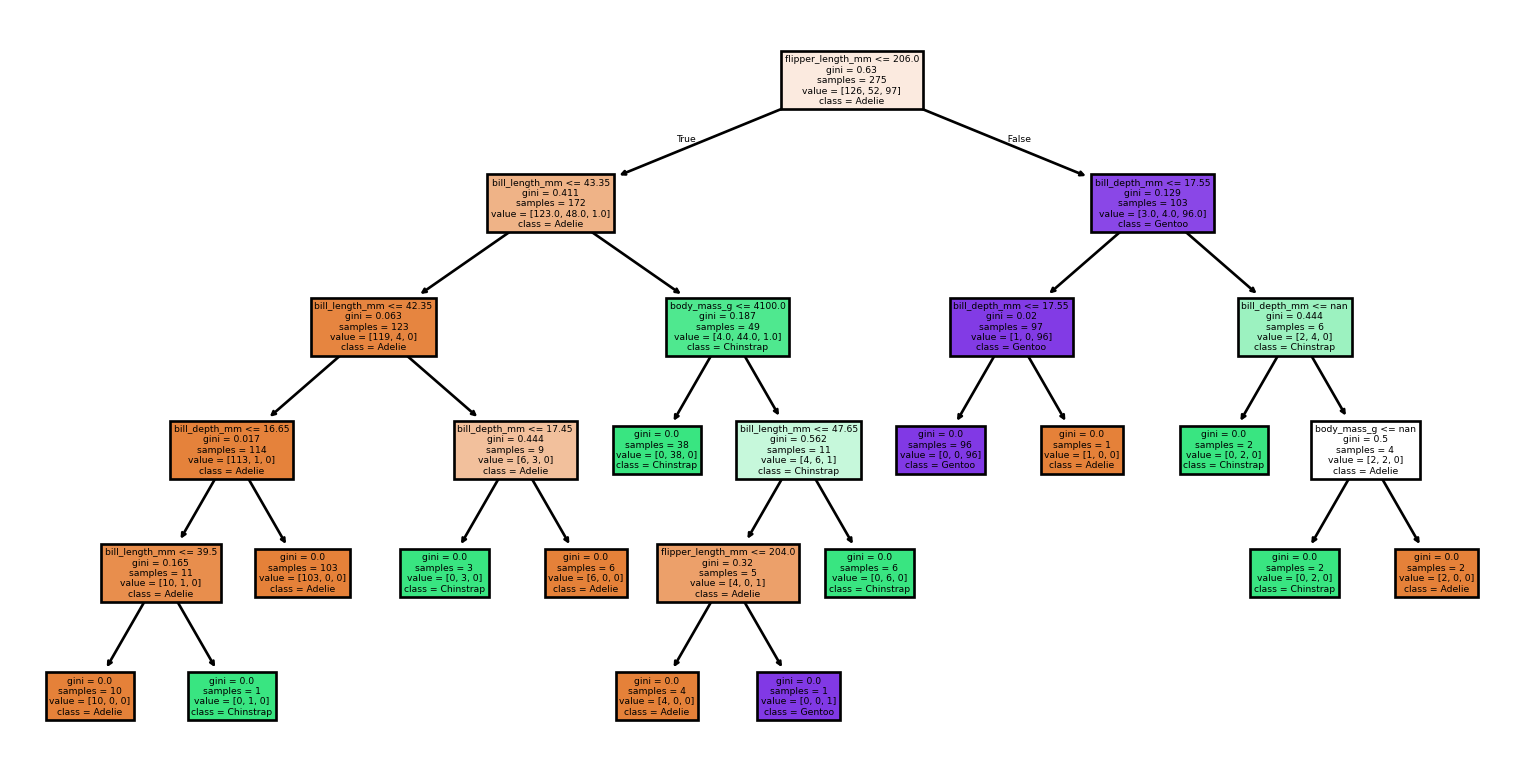
Accuracy: 0.94
Rapport de Classification:
precision recall f1-score support
Adelie 0.90 1.00 0.95 26
Chinstrap 0.93 0.88 0.90 16
Gentoo 1.00 0.93 0.96 27
accuracy 0.94 69
macro avg 0.94 0.93 0.94 69
weighted avg 0.95 0.94 0.94 69
Seed: 96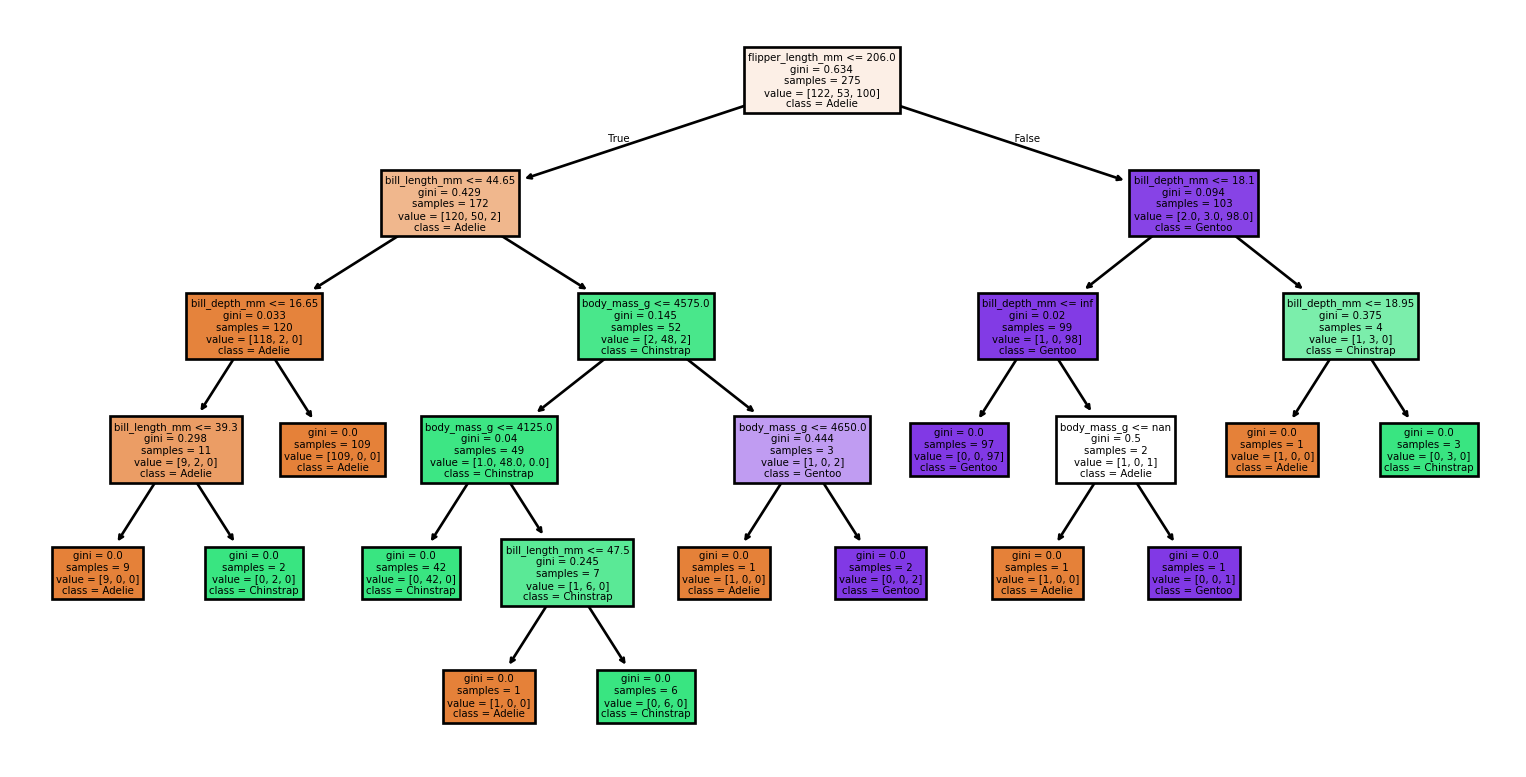
Accuracy: 0.90
Rapport de Classification:
precision recall f1-score support
Adelie 0.83 0.97 0.89 30
Chinstrap 1.00 0.67 0.80 15
Gentoo 0.96 0.96 0.96 24
accuracy 0.90 69
macro avg 0.93 0.86 0.88 69
weighted avg 0.91 0.90 0.90 69
Seed: 99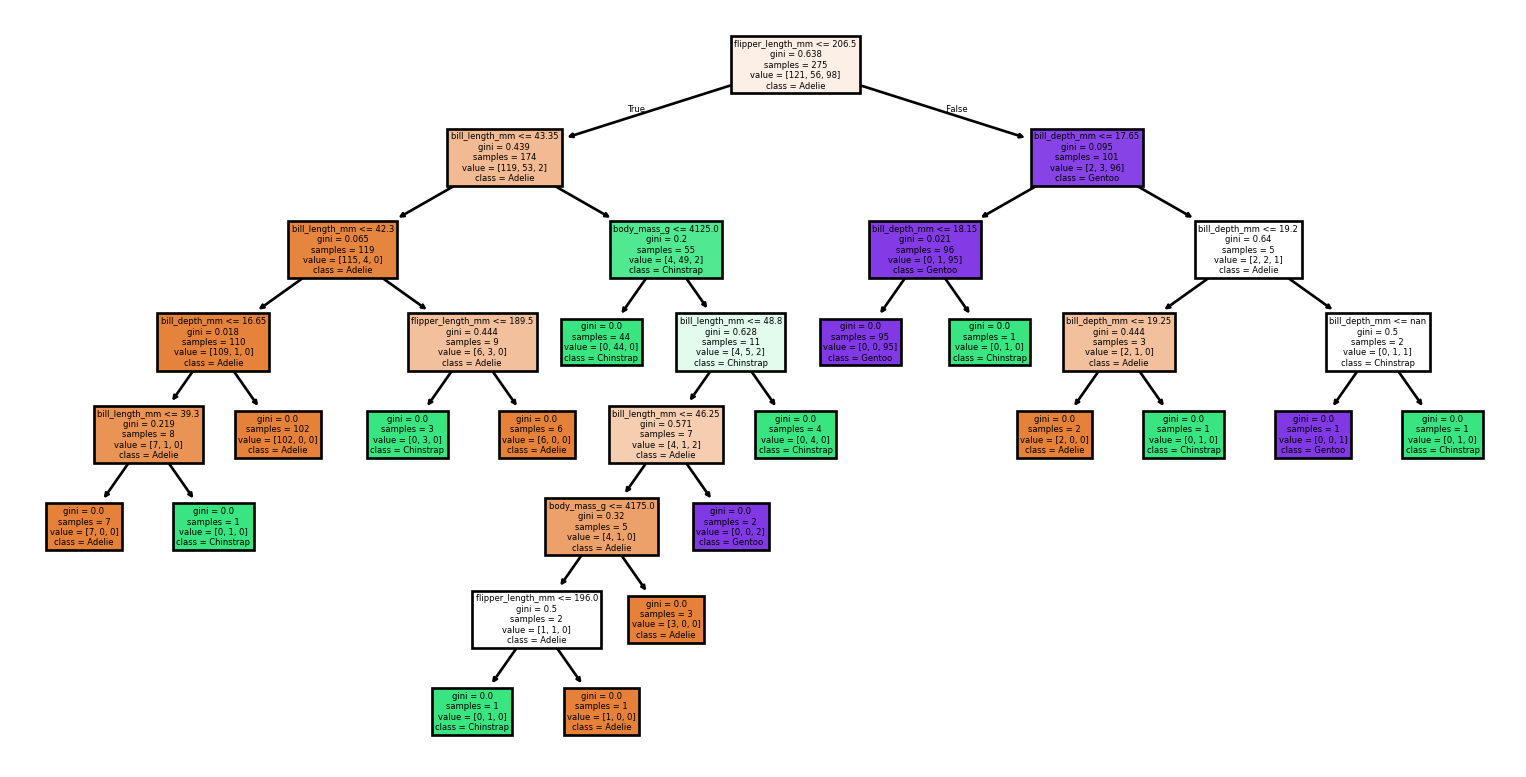
Accuracy: 1.00
Rapport de Classification:
precision recall f1-score support
Adelie 1.00 1.00 1.00 31
Chinstrap 1.00 1.00 1.00 12
Gentoo 1.00 1.00 1.00 26
accuracy 1.00 69
macro avg 1.00 1.00 1.00 69
weighted avg 1.00 1.00 1.00 69
Seed: 2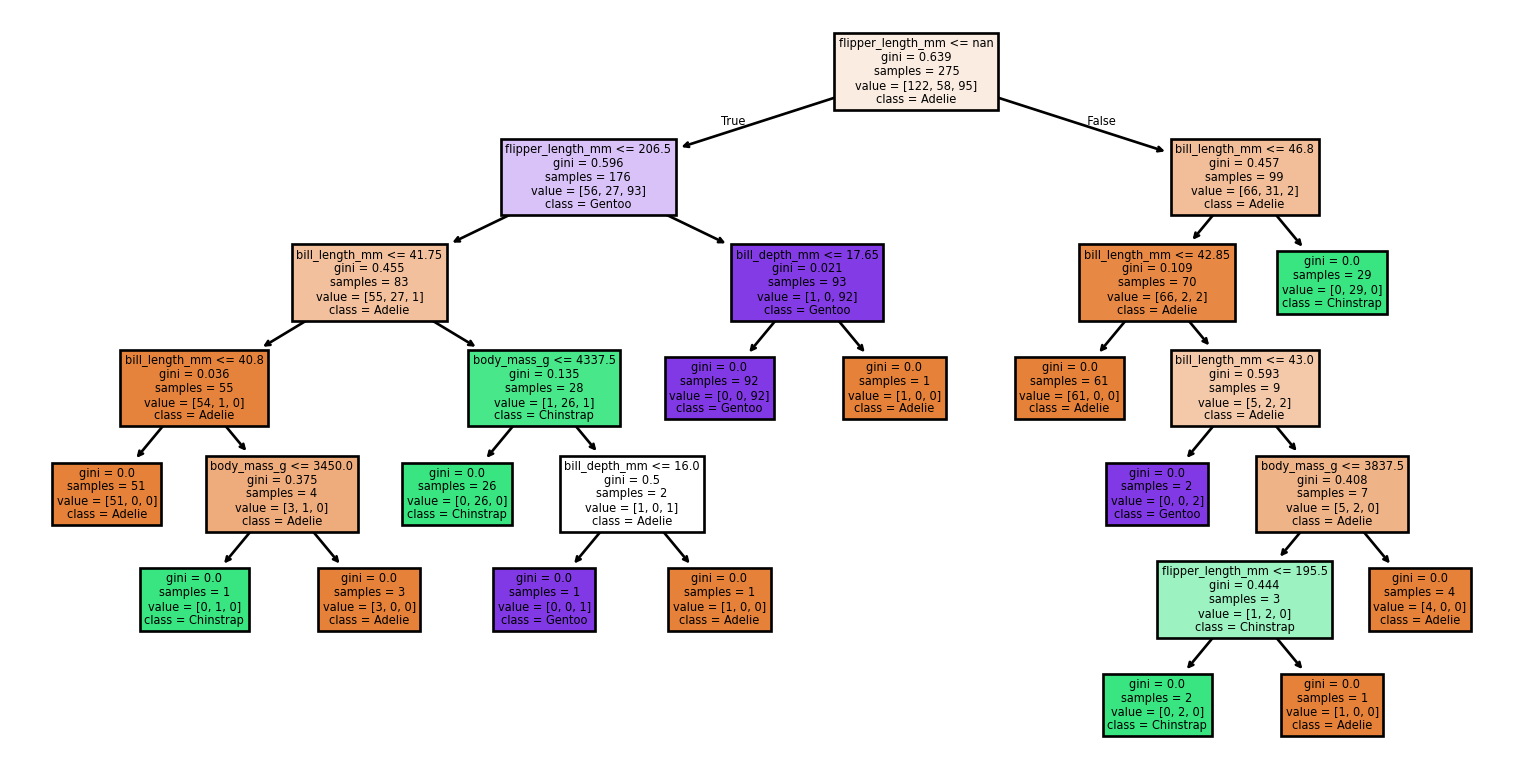
Accuracy: 0.55
Rapport de Classification:
precision recall f1-score support
Adelie 0.62 0.97 0.75 30
Chinstrap 0.43 0.90 0.58 10
Gentoo 0.00 0.00 0.00 29
accuracy 0.55 69
macro avg 0.35 0.62 0.44 69
weighted avg 0.33 0.55 0.41 69