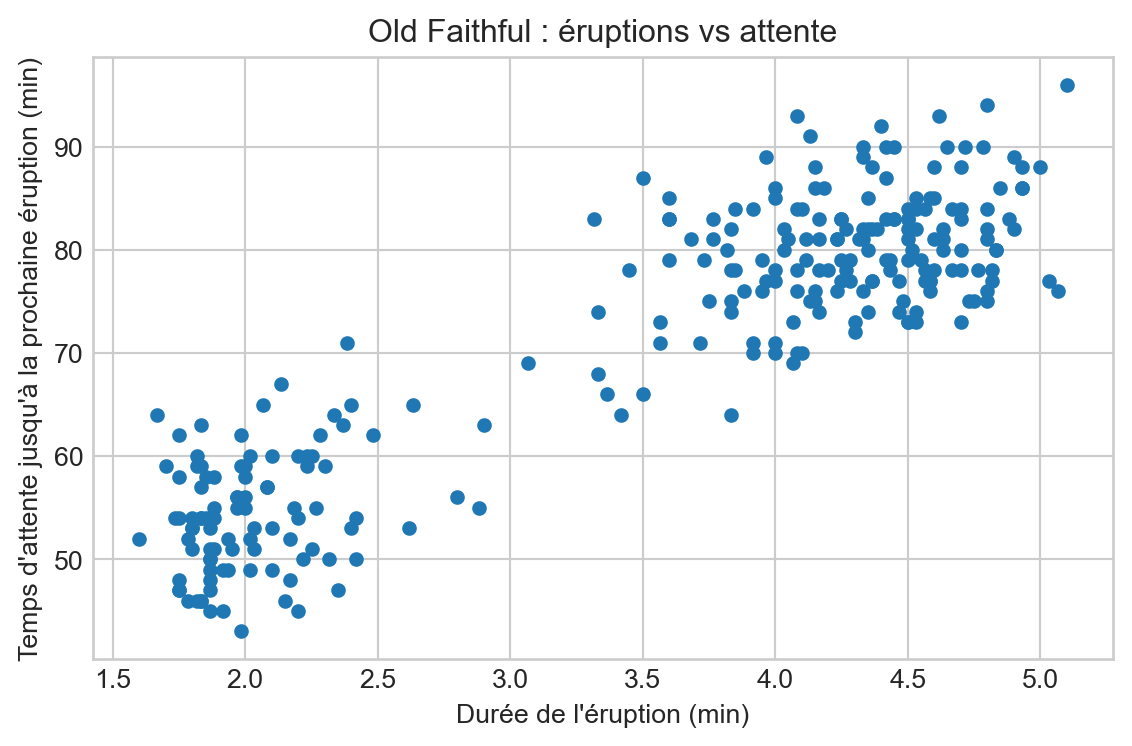
import pandas as pd
WOLFRAM_CSV = "https://raw.githubusercontent.com/turcotte/csi4106-f25/refs/heads/main/datasets/old_faithful_eruptions/Sample-Data-Old-Faithful-Eruptions.csv"
df = pd.read_csv(WOLFRAM_CSV)
# Renommer les colonnes
df = df.rename(columns={"Duration": "eruptions", "WaitingTime": "waiting"})
print(df.shape)
df.head(6)Régression linéaire et descente de gradient
CSI 4506 - automne 2025
Version: sept. 15, 2025 08h43
Message du jour

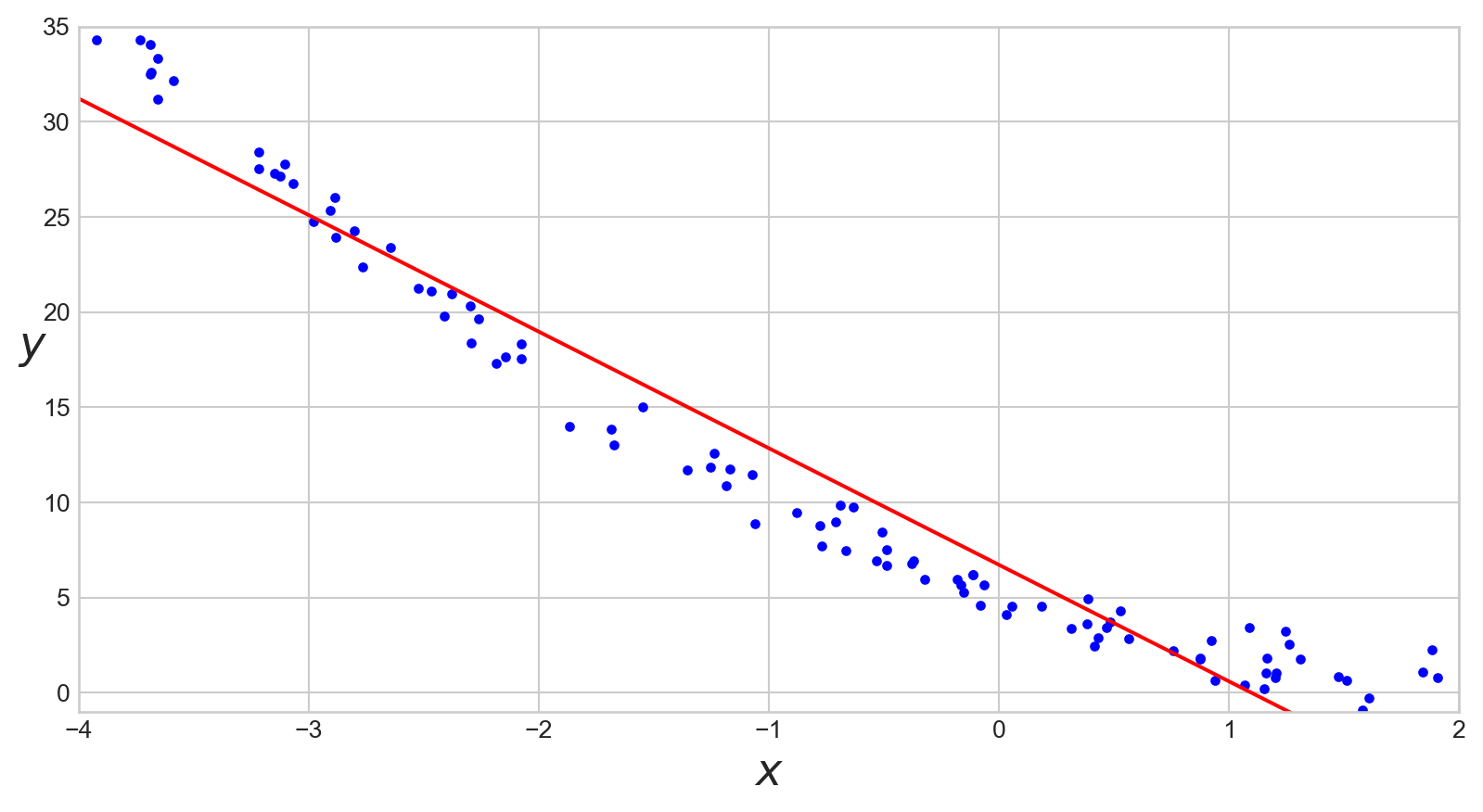
Visualisation Rapide
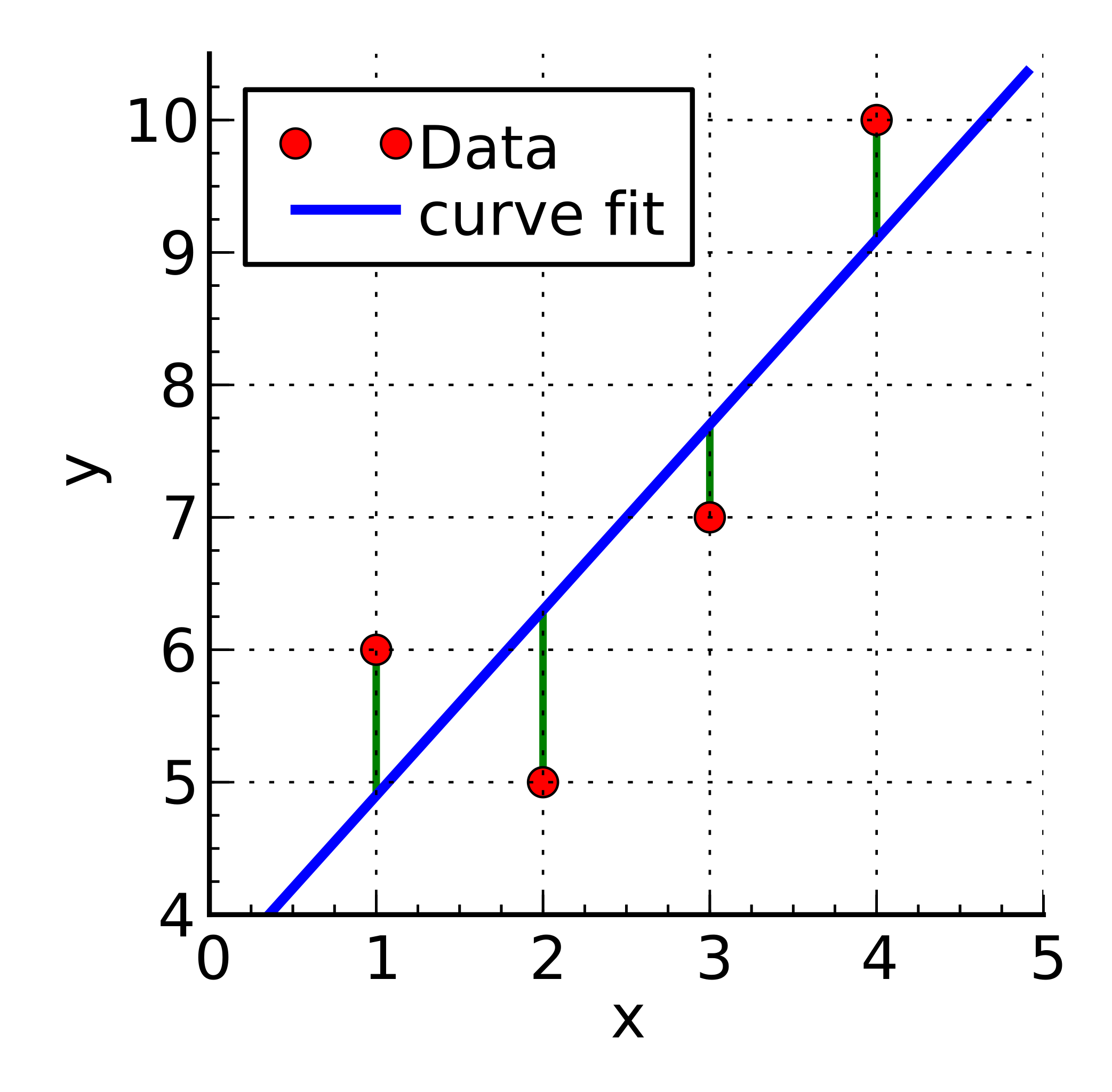
Minimisation de l’EQM (RMSE)
Visualisation
Code
import numpy as np
# Disperser les données
plt.figure(figsize=(6,4))
plt.scatter(X, y, color="steelblue", s=30, alpha=0.7, label="données")
# Tracer la ligne ajustée
x_line = np.linspace(0, X.max(), 100).reshape(-1, 1)
y_line = sgd.predict(x_line)
plt.plot(x_line, y_line, color="red", linewidth=2, label="ligne ajustée")
plt.xlabel("Durée de l'éruption (min)")
plt.ylabel("Temps d'attente jusqu'à la prochaine éruption (min)")
plt.title("Old Faithful : Régression linéaire via SGD")
plt.legend()
plt.tight_layout()
plt.show()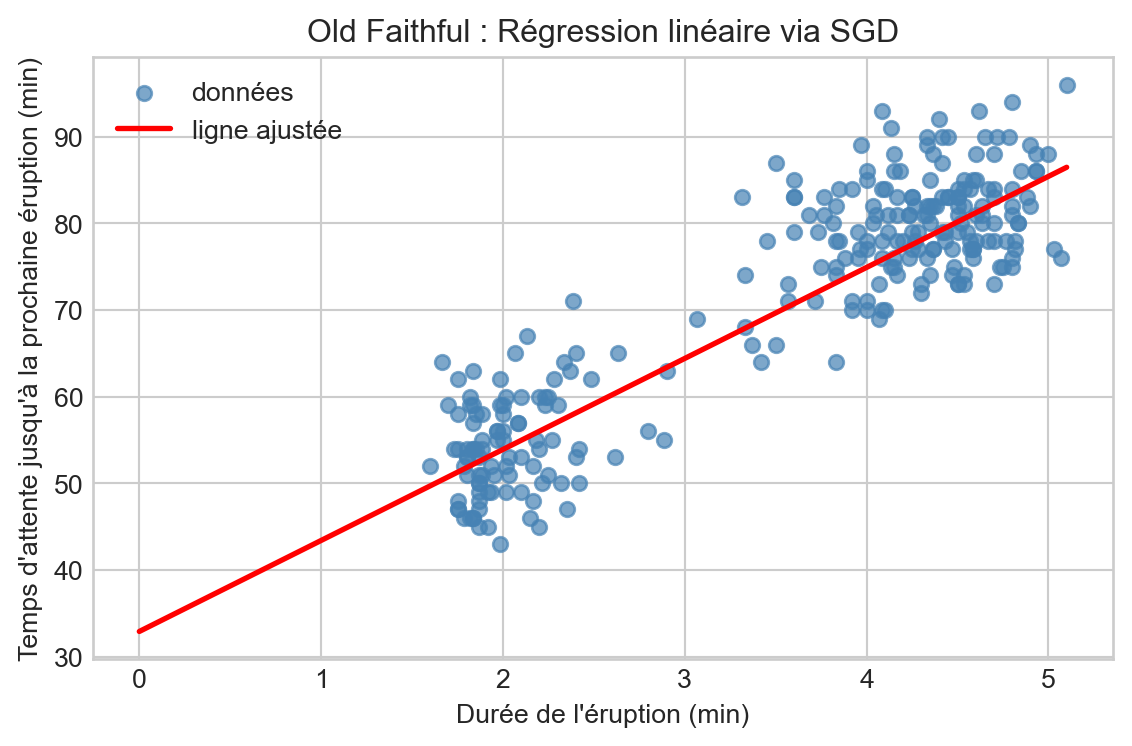
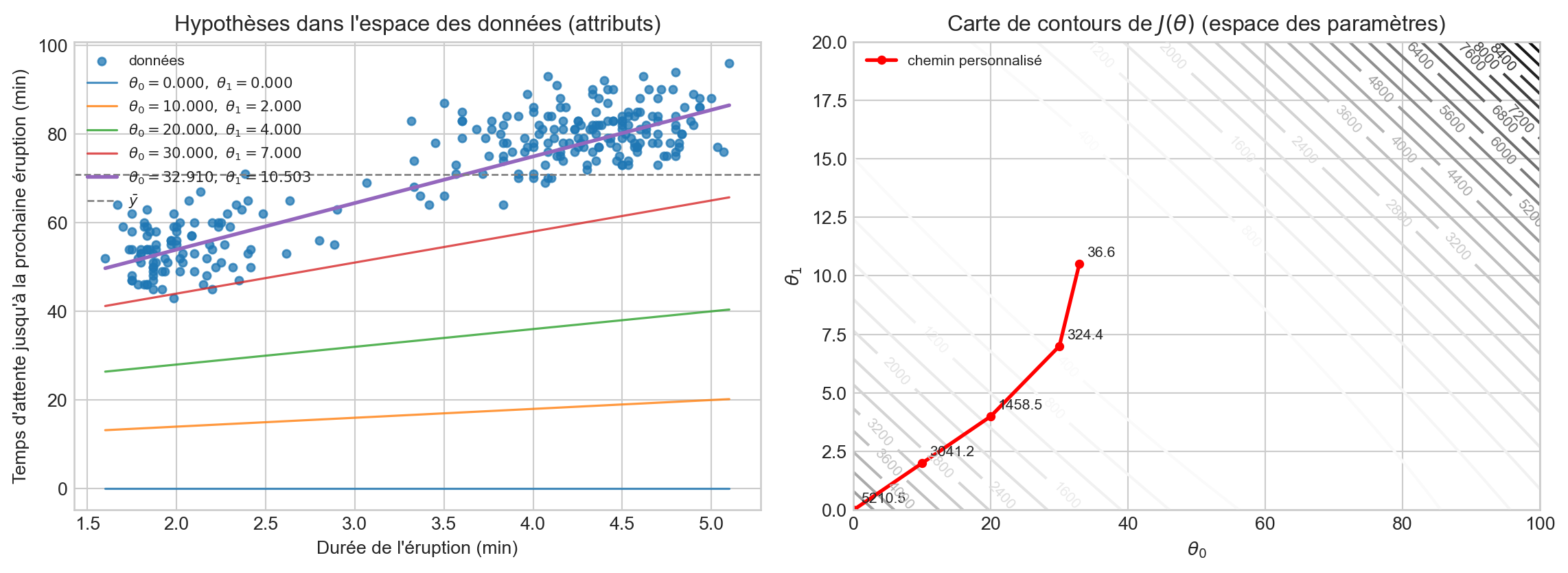
Hypothèses vs paramètres
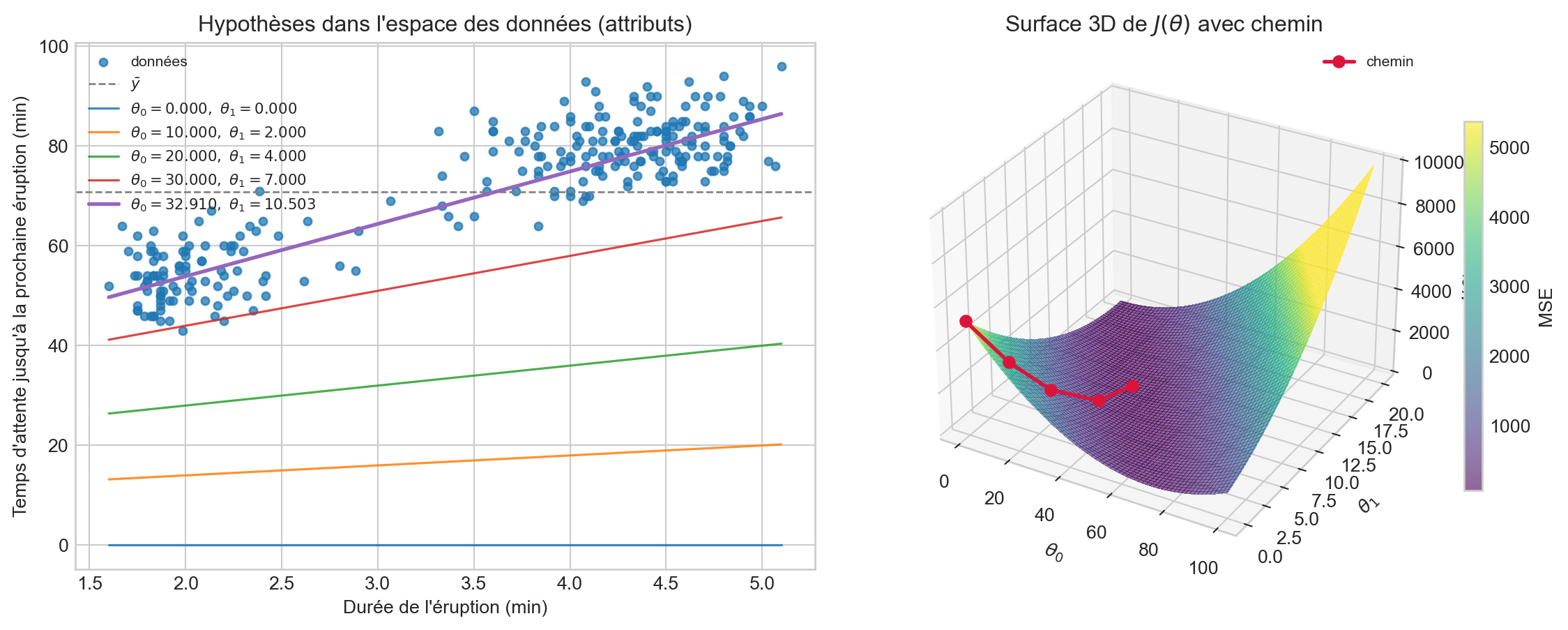
Hypothèses vs paramètres
Dérivée
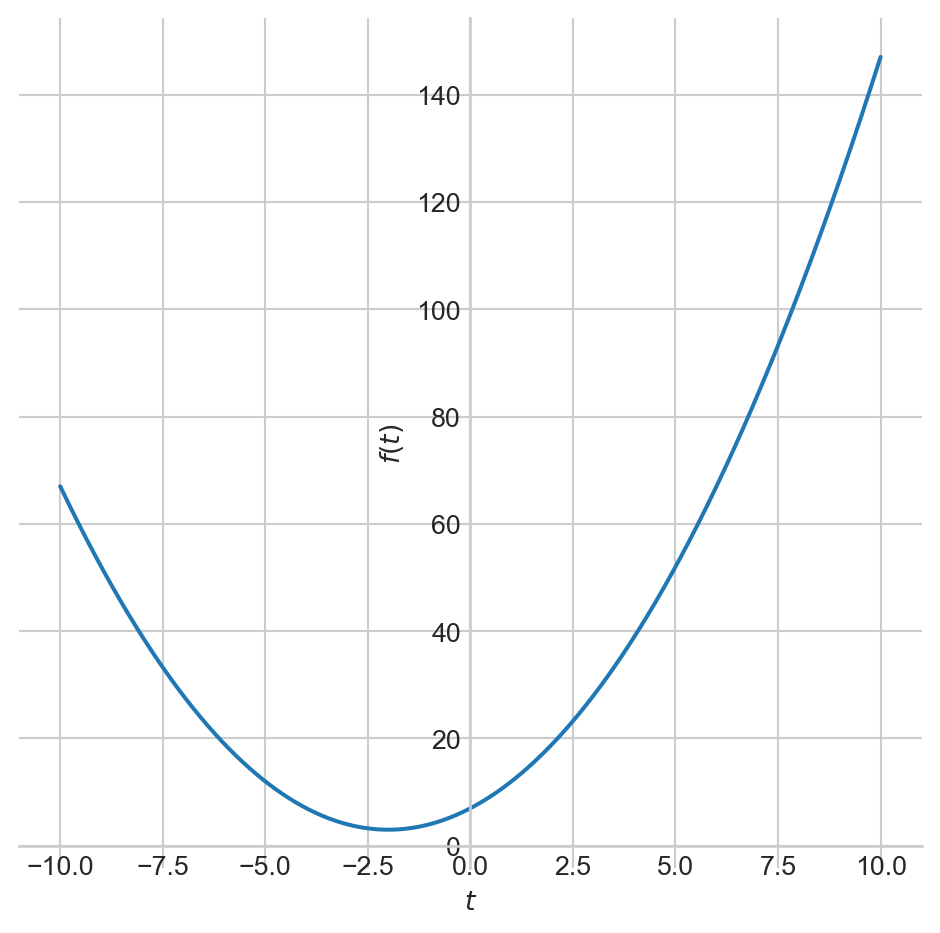
- Nous commencerons par une fonction à une variable.
- Considérez cela comme notre fonction de perte, que nous visons à minimiser; pour réduire la disparité moyenne entre les valeurs attendues et les valeurs prédites.
- J’utilise le symbol \(t\) pour la variable afin d’éviter toute confusion avec les attributs des exemples de notre jeu de données.
Dérivée
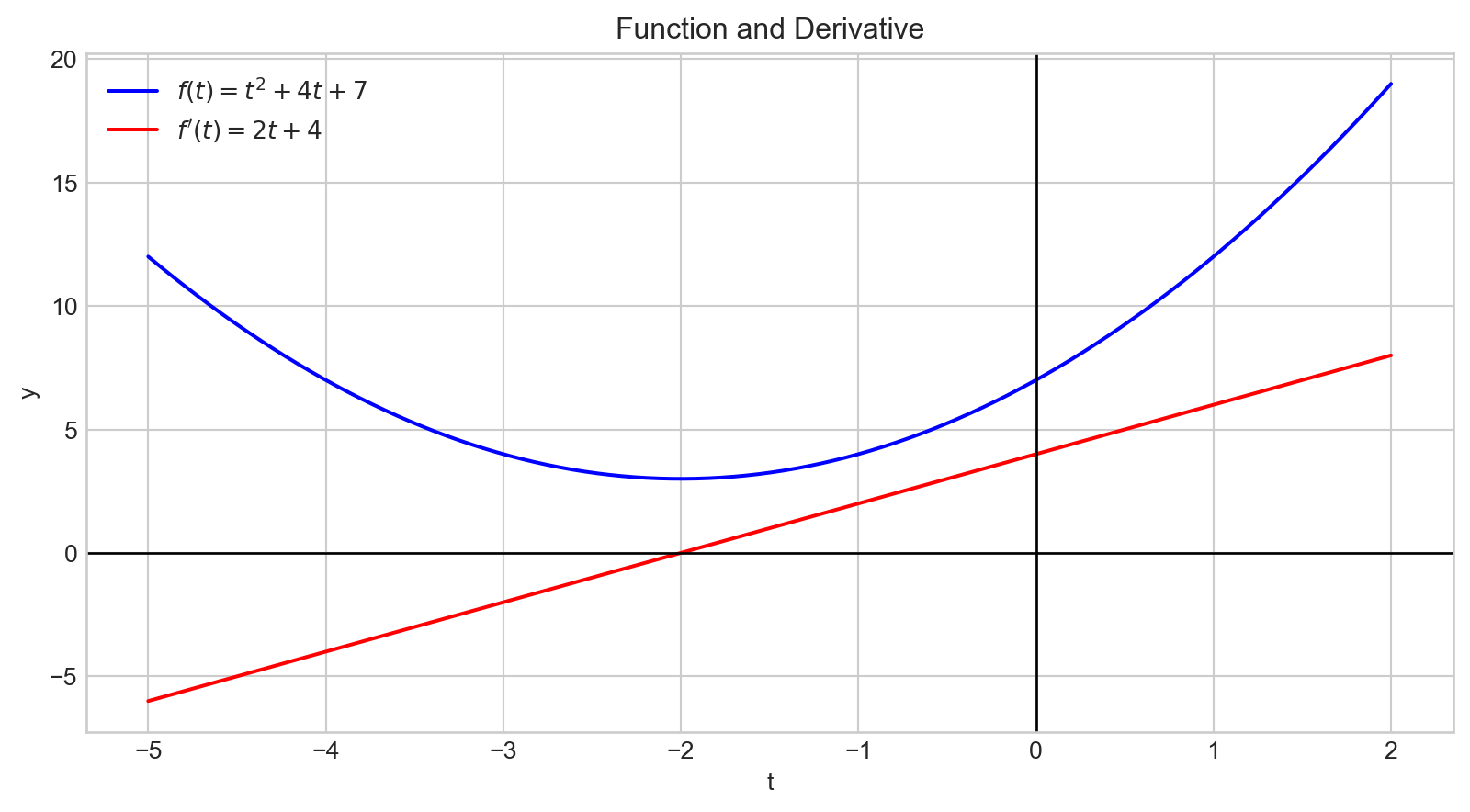
Le graphe de la dérivée, \(f^{'}(t)\), est représenté en rouge.
La dérivée indique comment les changements dans l’entrée affectent la sortie, \(f(t)\).
La magnitude de la dérivée en \(t = -2\) est \(0\).
Ce point correspond au minimum de notre fonction.
Dérivée
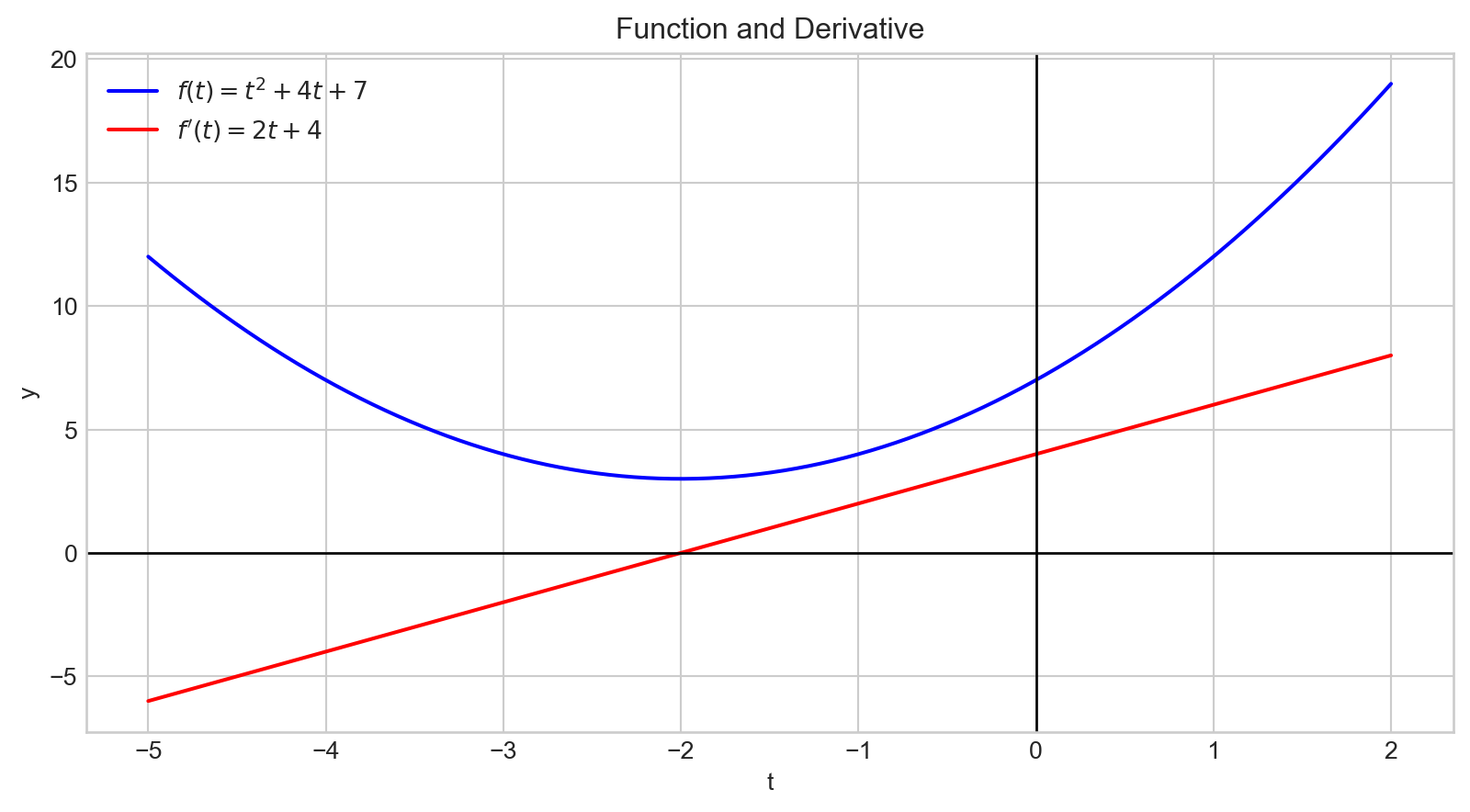
Lorsqu’elle est évaluée en un point spécifique, la dérivée indique la pente de la ligne tangente au graphe de la fonction à ce point.
À \(t= -2\), la pente de la ligne tangente est de 0.
Dérivée
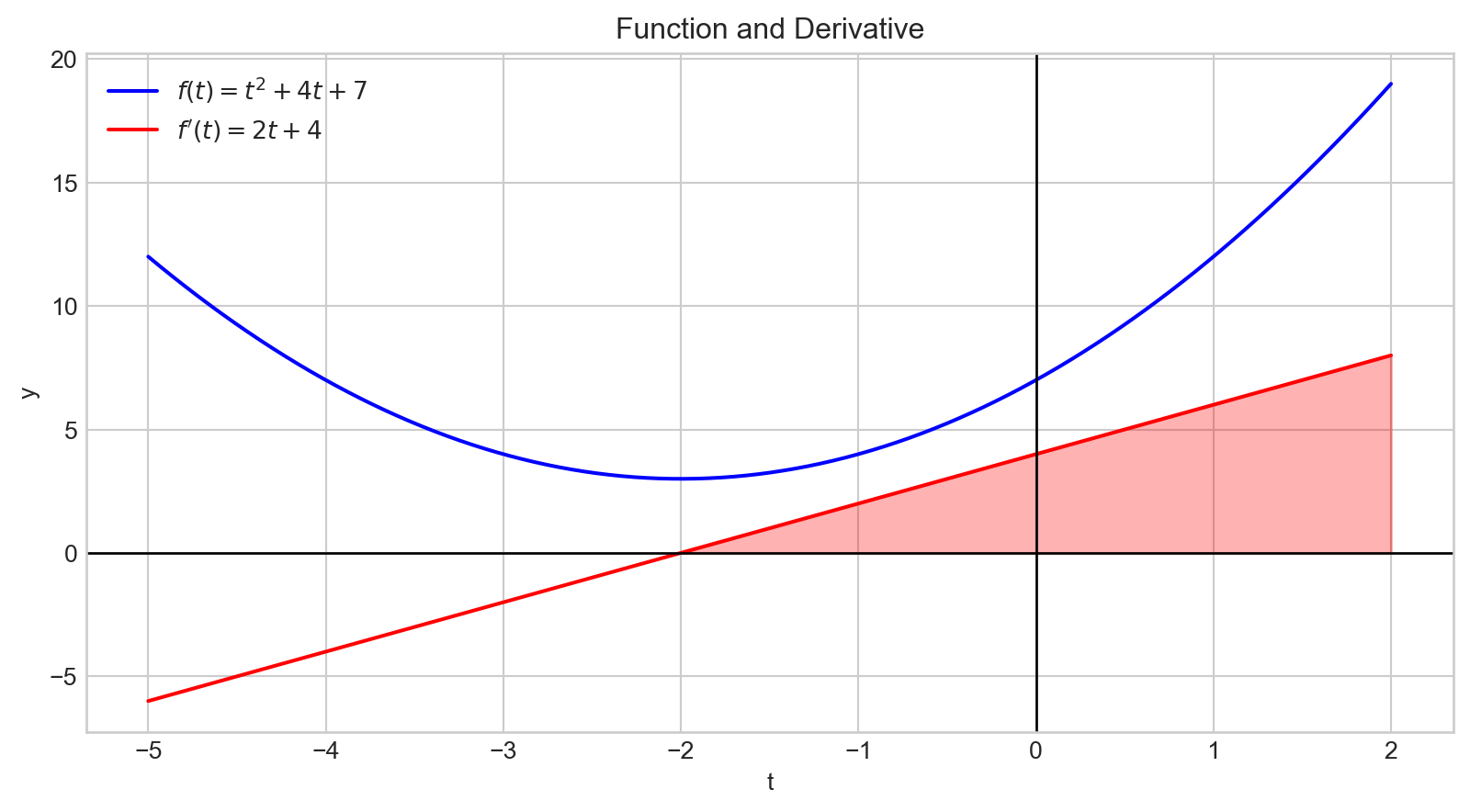
Une dérivée positive indique qu’augmenter la variable d’entrée entraînera une augmentation de la valeur de sortie.
De plus, la magnitude de la dérivée quantifie la rapidité du changement de la sortie.
Dérivée
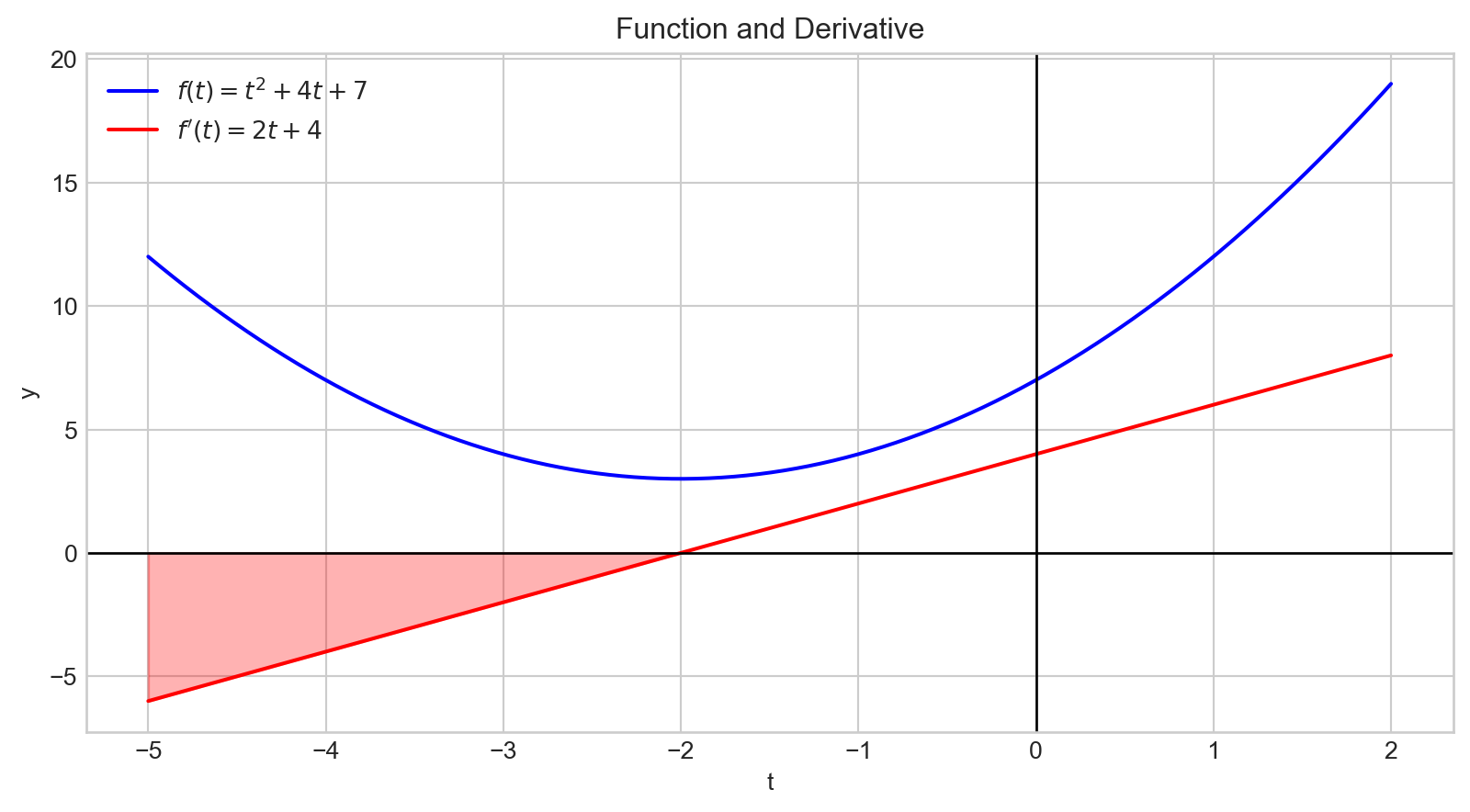
Une dérivée négative indique qu’augmenter la variable d’entrée entraînera une diminution de la valeur de sortie.
De plus, la magnitude de la dérivée quantifie la rapidité du changement de la sortie.
Descente de gradient - une variable
Code
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
# Définir la variable et la fonction
t = sp.symbols('t')
f = t**2 + 4*t + 7
# Calculer la dérivée
f_prime = sp.diff(f, t)
# Lambdifier les fonctions pour le traçage numérique
f_func = sp.lambdify(t, f, "numpy")
f_prime_func = sp.lambdify(t, f_prime, "numpy")
# Générer des valeurs de t pour le traçage
t_vals = np.linspace(-5, 2, 400)
# Obtenir des valeurs y pour la fonction et sa dérivée
f_vals = f_func(t_vals)
f_prime_vals = f_prime_func(t_vals)
# Tracer la fonction et sa dérivée
plt.plot(t_vals, f_vals, label=r'$J$', color='blue')
plt.plot(t_vals, f_prime_vals, label=r"$\frac {\partial}{\partial \theta_j}J(\theta)$", color='red')
# Ajouter des étiquettes et une légende
plt.axhline(0, color='black',linewidth=1)
plt.axvline(0, color='black',linewidth=1)
plt.title('Fonction et Dérivée')
plt.xlabel(r'$\theta_j$')
plt.ylabel(r'$J$')
plt.legend()
# Afficher le graphique
plt.grid(True)
plt.show()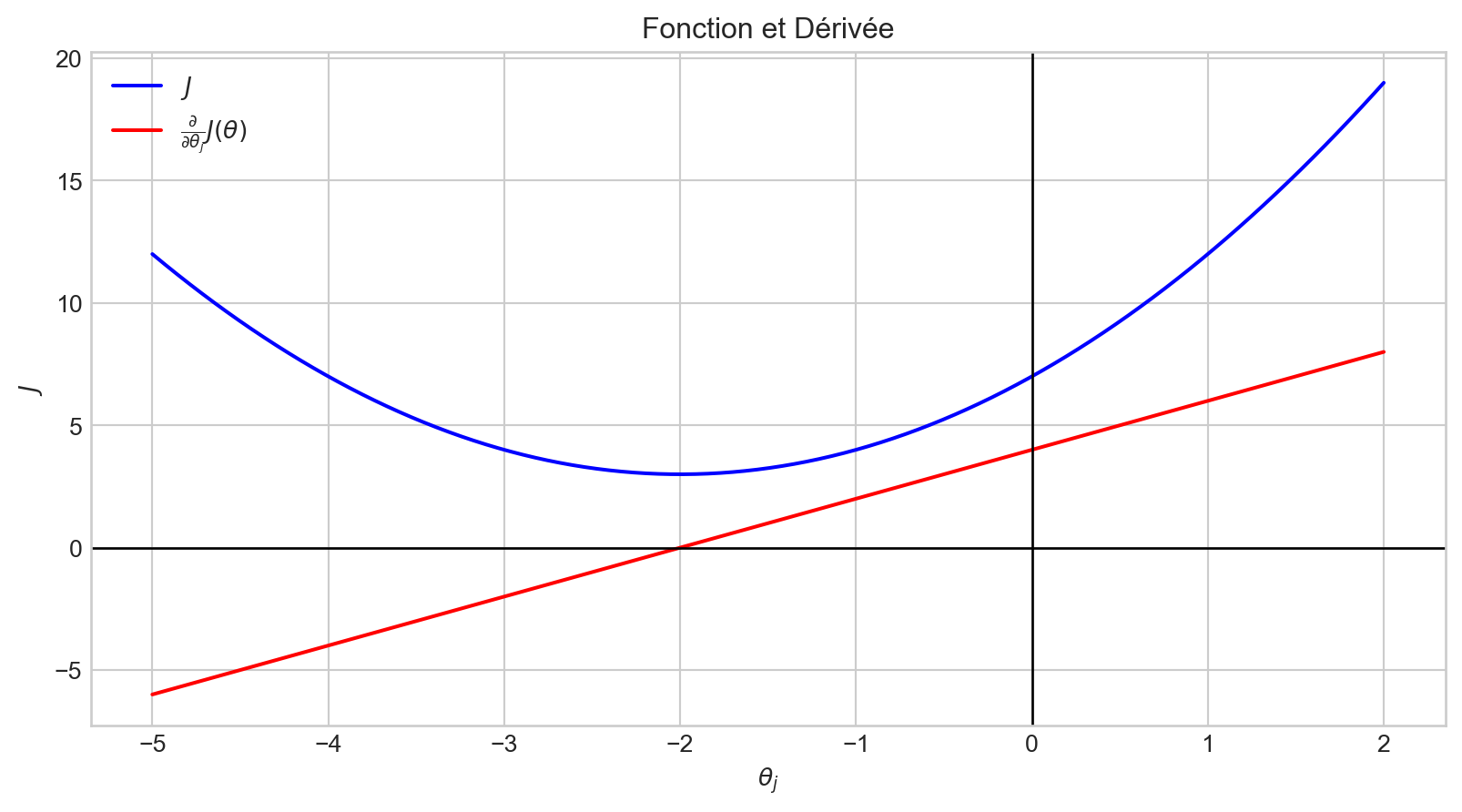
Lorsque la valeur de \(\theta_j\) est dans l’intervalle \([- \inf, -2)\), \(\frac {\partial}{\partial \theta_j}J(\theta)\) a une valeur négative.
Par conséquent, \(- \alpha \frac {\partial}{\partial \theta_j}J(\theta)\) est positif.
En conséquence, la valeur de \(\theta_j\) est augmentée.
Descente de gradient - une variable
Code
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
# Définir la variable et la fonction
t = sp.symbols('t')
f = t**2 + 4*t + 7
# Calculer la dérivée
f_prime = sp.diff(f, t)
# Lambdifier les fonctions pour le tracé numérique
f_func = sp.lambdify(t, f, "numpy")
f_prime_func = sp.lambdify(t, f_prime, "numpy")
# Générer les valeurs de t pour le traçage
t_vals = np.linspace(-5, 2, 400)
# Obtenir les valeurs y pour la fonction et sa dérivée
f_vals = f_func(t_vals)
f_prime_vals = f_prime_func(t_vals)
# Tracer la fonction et sa dérivée
plt.plot(t_vals, f_vals, label=r'$J$', color='blue')
plt.plot(t_vals, f_prime_vals, label=r"$\frac {\partial}{\partial \theta_j}J(\theta)$", color='red')
# Ajouter des étiquettes et une légende
plt.axhline(0, color='black',linewidth=1)
plt.axvline(0, color='black',linewidth=1)
plt.title('Fonction et Dérivée')
plt.xlabel(r'$\theta_j$')
plt.ylabel(r'$J$')
plt.legend()
# Afficher le graphique
plt.grid(True)
plt.show()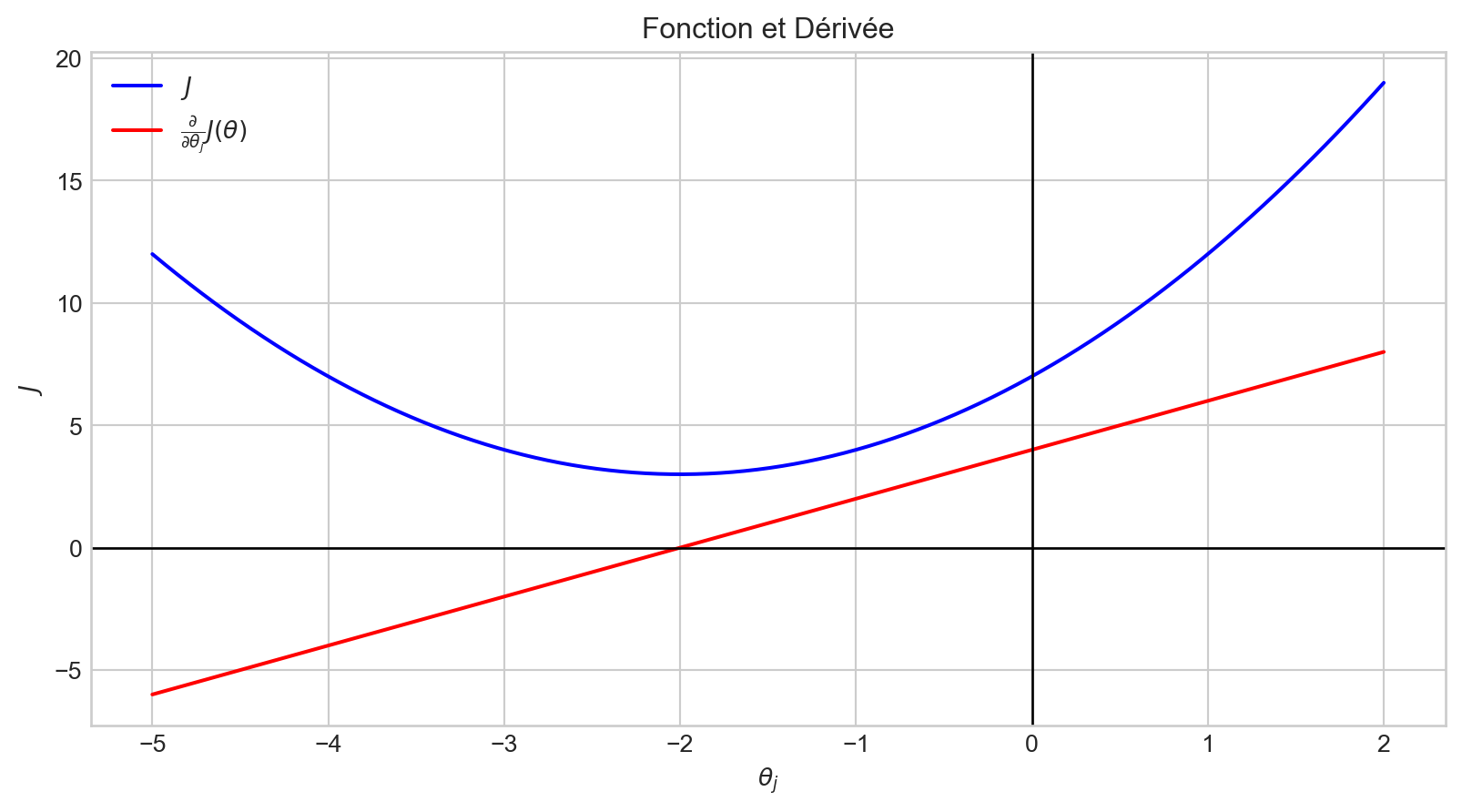
Lorsque la valeur de \(\theta_j\) est dans l’intervalle \((-2, \infty]\), \(\frac {\partial}{\partial \theta_j}J(\theta)\) a une valeur positive.
Par conséquent, \(- \alpha \frac {\partial}{\partial \theta_j}J(\theta)\) est négatif.
En conséquence, la valeur de \(\theta_j\) est diminuée.
Local vs global

Convergence
Code
# 1. Définir la variable symbolique et la fonction
x = sp.Symbol('x', real=True)
f_expr = 2*x**3 + 4*x**2 - 5*x + 1
# 2. Calculer la dérivée de f
f_prime_expr = sp.diff(f_expr, x)
# 3. Convertir les expressions symboliques en fonctions Python
f = sp.lambdify(x, f_expr, 'numpy')
f_prime = sp.lambdify(x, f_prime_expr, 'numpy')
# 4. Générer une plage de valeurs x
x_vals = np.linspace(-4, 2, 1000)
# 5. Calculer f et f' sur cette plage
y_vals = f(x_vals)
y_prime_vals = f_prime(x_vals)
# 6. Préparer les chaînes LaTeX pour la légende
f_label = rf'$f(x) = {sp.latex(f_expr)}$'
f_prime_label = rf'$f^\prime(x) = {sp.latex(f_prime_expr)}$'
# 7. Tracer f et f', avec les équations dans la légende
plt.figure(figsize=(8, 4))
plt.plot(x_vals, y_vals, label=f_label)
plt.plot(x_vals, y_prime_vals, label=f_prime_label)
# 8. Colorier la région entre l'axe x et f'(x) pour tout le domaine
plt.fill_between(x_vals, y_prime_vals, 0, color='gray', alpha=0.2, interpolate=True,
label='Région entre 0 et f\'(x)')
# 9. Ajouter une ligne de référence, des étiquettes, une légende, etc.
plt.axhline(0, color='black', linewidth=0.5)
plt.title(rf'Fonction et sa dérivée avec ombrage pour $f^\prime(x)$')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid(True)
plt.show()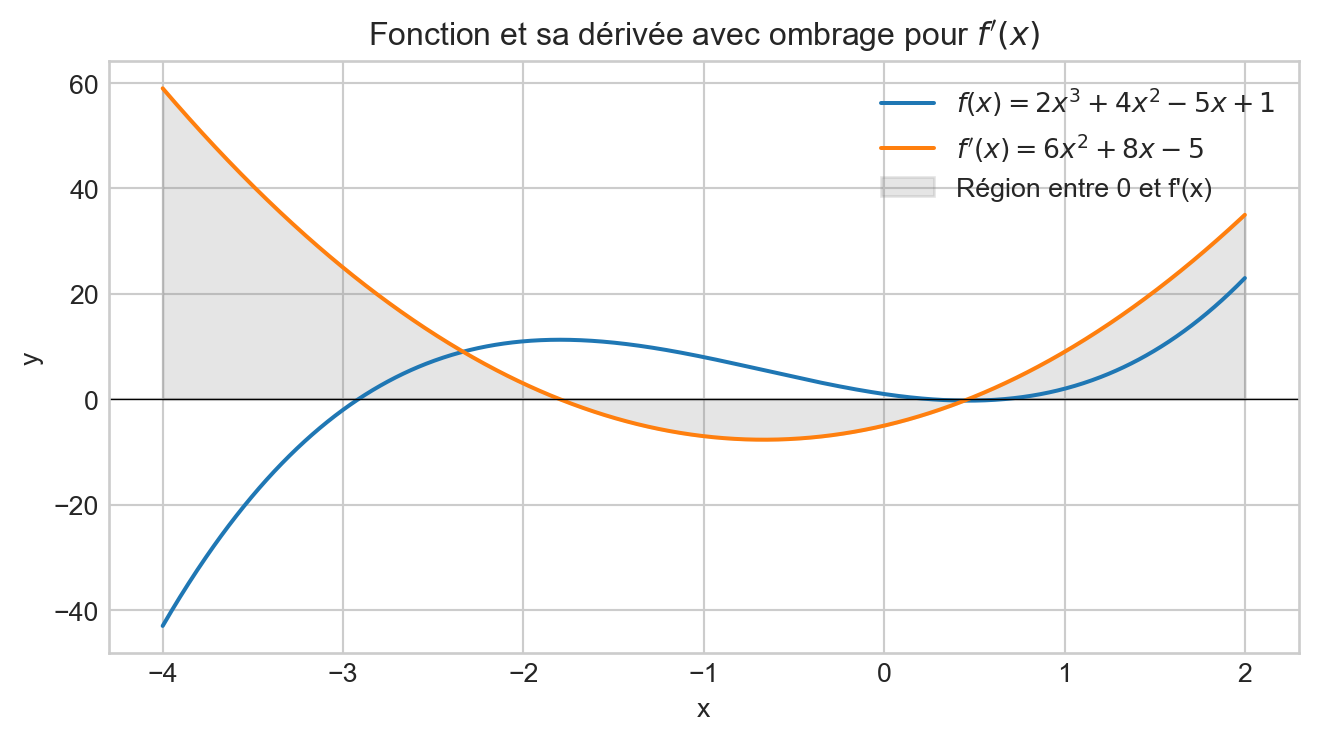
Taux d’apprentissage
- Petits pas, des valeurs faibles pour \(\alpha\), feront que l’algorithme convergera lentement.
- Grands pas peuvent amener l’algorithme à diverger.
- Remarquez comment l’algorithme ralentit naturellement en approchant d’un minimum.
Taux d’apprentissage
Code
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x**2
def grad_f(x):
return 2*x
# Estimation initiale, taux d'apprentissage et nombre d'étapes de descente de gradient
x_current = 2.0
learning_rate = 1.1 # Trop grand => divergence
num_iterations = 5 # Nous ferons cinq mises à jour
# Stocker chaque valeur de x dans une liste (trajectoire) pour l'affichage
trajectory = [x_current]
# Effectuer la descente de gradient
for _ in range(num_iterations):
g = grad_f(x_current)
x_current = x_current - learning_rate * g
trajectory.append(x_current)
# Préparer les données pour l'affichage
x_vals = np.linspace(-5, 5, 1000)
y_vals = f(x_vals)
# Tracer la fonction f(x)
plt.figure(figsize=(6, 5))
plt.plot(x_vals, y_vals, label=r"$f(x) = x^2$")
plt.axhline(0, color='black', linewidth=0.5)
# Tracer la trajectoire, en étiquetant chaque itération
for i, x_t in enumerate(trajectory):
y_t = f(x_t)
# Tracer le point
plt.plot(x_t, y_t, 'ro')
# Étiqueter le numéro d'itération
plt.text(x_t, y_t, f" {i}", color='red')
# Connecter les points consécutifs
if i > 0:
x_prev = trajectory[i - 1]
y_prev = f(x_prev)
plt.plot([x_prev, x_t], [y_prev, y_t], 'r--')
# Finitions
plt.title("Divergence de la descente de gradient avec un grand taux d'apprentissage")
plt.xlabel("x")
plt.ylabel("f(x)")
plt.legend()
plt.grid(True)
plt.show()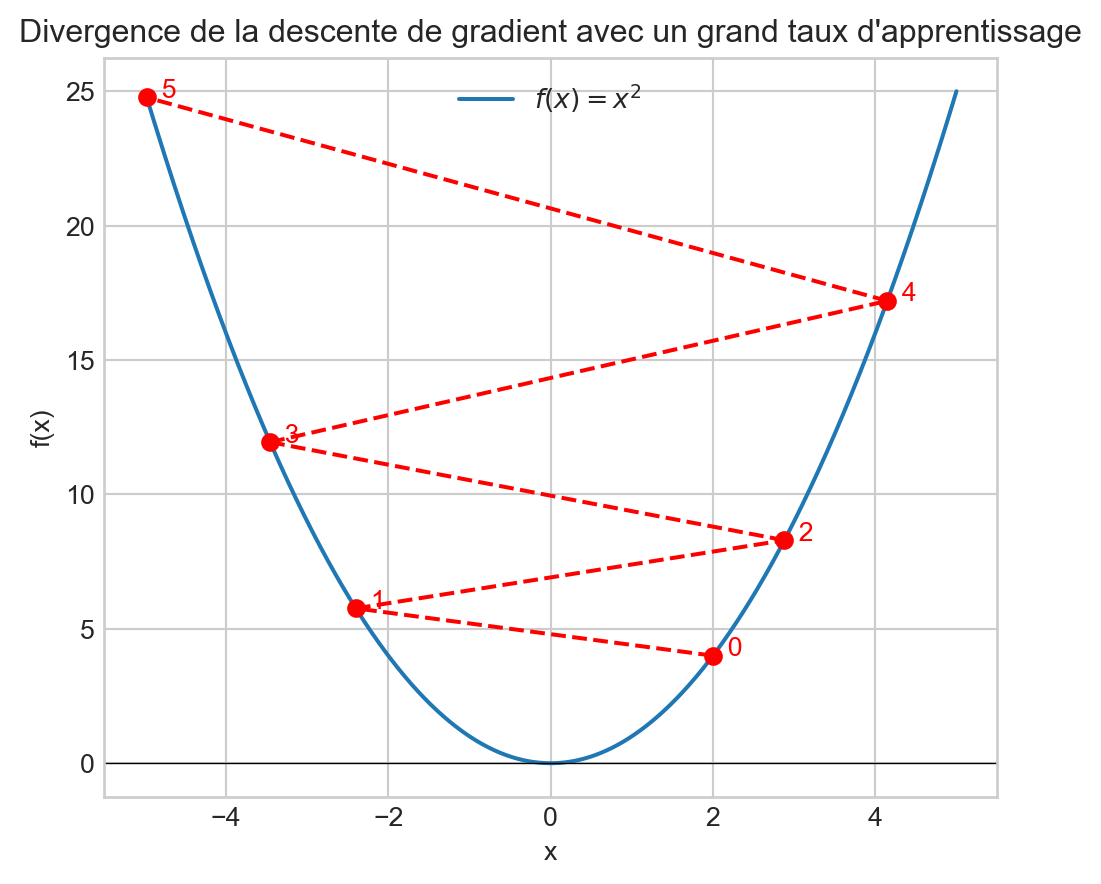
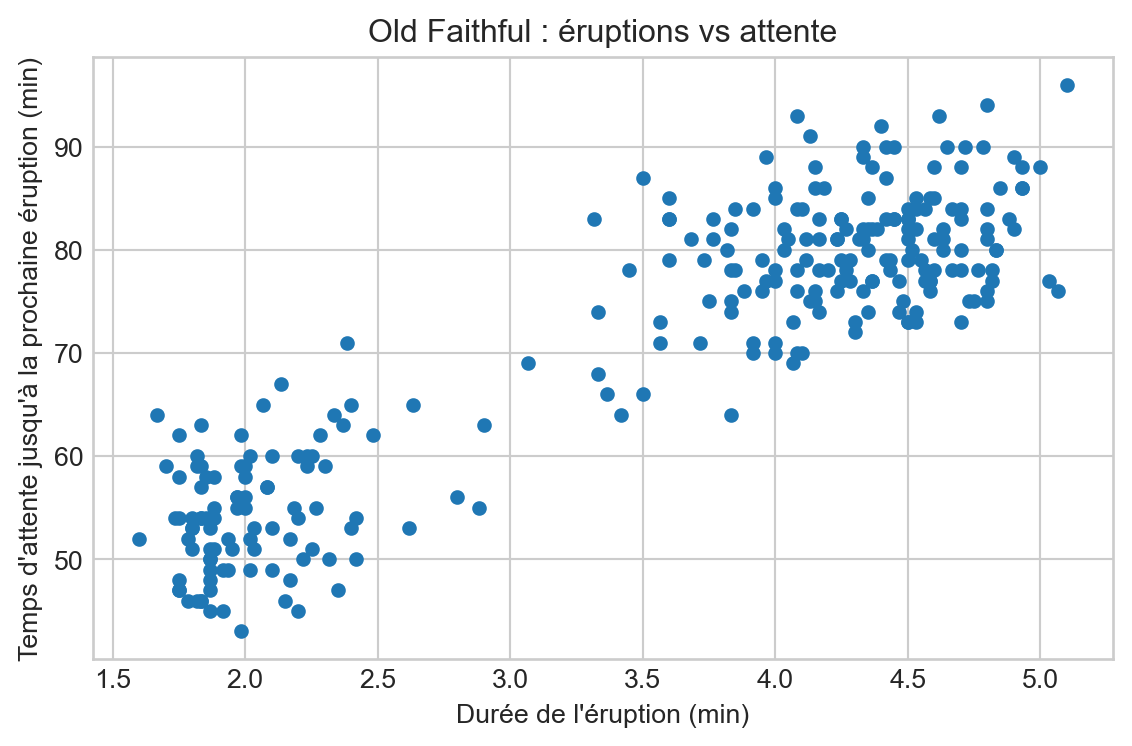
Visualisation rapide
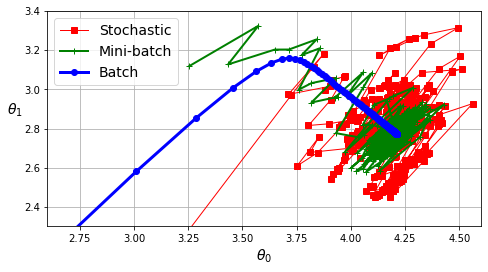
Stochastique, mini-lots, lot
Andrew Ng

- Gradient Descent (Math)
(11:30 m) - Intuition
(11:51 m) - Linear Regression
(10:20 m) - ML-005 | Stanford | Andrew Ng
(19 videos)
Régression linéaire