Assigner \(y_i = 0\), si \(h_\theta(x_i) < 0.5\) ; \(y_i = 1\), si \(h_\theta(x_i) \geq 0.5\)
On trouve les valeurs optimales de \(\theta\) avec la descente de gradient.
Quelle fonction de perte devrait être utilisée et pourquoi ?
Remarques
Lors de la construction de modèles d’apprentissage automatique avec des bibliothèques comme scikit-learn ou keras, il faut sélectionner une fonction de perte ou accepter celle par défaut.
Initialement, la terminologie peut être déroutante, car des fonctions identiques peuvent être référencées par divers noms.
Notre objectif est de clarifier ces complexités.
Ce n’est en fait pas si compliqué !
Estimation des paramètres
La régression logistique est un modèle statistique.
Sa sortie est \(\hat{y} = P(y = 1 | x, \theta)\).
\(P(y = 0 | x, \theta) = 1 - \hat{y}\).
Suppose que les valeurs de \(y\) proviennent d’une distribution de Bernoulli.
\(\theta\) est généralement trouvé par l’estimation du maximum de vraisemblance.
Estimation des paramètres
L’estimation par maximum de vraisemblance (MLE) (Maximum Likelihood Estimation) est une méthode statistique utilisée pour estimer les paramètres d’un modèle probabiliste.
Elle identifie les valeurs des paramètres qui maximisent la fonction de vraisemblance, qui évalue à quel point le modèle décrit les données observées.
Fonction de vraisemblance
En supposant que les valeurs de \(y\) sont indépendantes et identiquement distribuées (i.i.d.), la fonction de vraisemblance est exprimée comme le produit des probabilités individuelles.
En d’autres termes, étant donné nos données, \(\{(x_i, y_i)\}_{i=1}^N\), la fonction de vraisemblance est donnée par cette équation. \[
\mathcal{L}(\theta) = \prod_{i=1}^{N} P(y_i \mid x_i, \theta)
\]
Les algorithmes des arbres de décision utilisent souvent l’entropie, une mesure issue de la théorie de l’information, pour évaluer la qualité des divisions ou des partitions dans les règles de décision.
L’entropie quantifie l’incertitude ou l’impureté associée aux résultats potentiels d’une variable aléatoire.
Entropie
L’entropie dans la théorie de l’information quantifie l’incertitude ou l’imprévisibilité des résultats possibles d’une variable aléatoire. Elle mesure la quantité moyenne d’information produite par une source de données stochastique et est généralement exprimée en bits pour les systèmes binaires. L’entropie \(H\) d’une variable aléatoire discrète \(X\) avec des résultats possibles \(\{x_1, x_2, \ldots, x_n\}\) et une fonction de masse de probabilité \(P(X)\) est donnée par :
\[
H(X) = -\sum_{i=1}^n P(x_i) \log_2 P(x_i)
\]
Entropie croisée
L’entropie croisée quantifie la différence entre deux distributions de probabilité, typiquement la distribution réelle et une distribution prédite.
\[
H(p, q) = -\sum_{i} p(x_i) \log q(x_i)
\] où \(p(x_i)\) est la distribution de probabilité réelle, et \(q(x_i)\) est la distribution de probabilité prédite.
Entropie croisée
Considérons \(y\) comme la distribution de probabilité réelle et \(\hat{y}\) comme la distribution de probabilité prédite.
L’entropie croisée quantifie la divergence entre ces deux distributions.
Entropie croisée
Considérons la fonction de perte de log-vraisemblance négative (negative log-likelihood) :
Cette expression illustre que la log-vraisemblance négative est optimisée en minimisant l’entropie croisée.
Exemple
Code
import matplotlib.pyplot as pltimport numpy as npnp.random.seed(42)# Générer un tableau de valeurs p allant juste au-dessus de 0 jusqu'à 1p_values = np.linspace(0.001, 1, 1000)# Calculer le logarithme naturel de chaque valeur pln_p_values =- np.log(p_values)# Tracer le graphiqueplt.figure(figsize=(5, 4))plt.plot(p_values, ln_p_values, label=r'$-\log(\hat{y})$', color='b')# Ajouter des étiquettes et un titreplt.xlabel(r'$\hat{y}$')plt.ylabel(r'J')plt.title(r'Graphique de $-\log(\hat{y})$ pour $\hat{y}$ de 0 à 1')plt.grid(True)plt.axhline(0, color='gray', lw=0.5) # Ajouter une ligne horizontale à y=0plt.axvline(0, color='gray', lw=0.5) # Ajouter une ligne verticale à x=0# Afficher le graphiqueplt.legend()plt.show()
Remarques
La perte d’entropie croisée est particulièrement bien adaptée aux tâches de classification probabilistes en raison de son alignement avec l’estimation du maximum de vraisemblance.
Dans la régression logistique, la perte d’entropie croisée préserve la convexité, contrastant avec la nature non convexe de l’erreur quadratique moyenne (MSE)1.
Remarques
Pour les problèmes de classification, la perte d’entropie croisée atteint souvent une convergence plus rapide comparée à la MSE, améliorant l’efficacité du modèle.
Dans les architectures d’apprentissage profond, la MSE peut exacerber le problème de gradient évanescent, une question que nous aborderons dans une discussion ultérieure.
Pourquoi ne pas utiliser la MSE comme fonction de perte ?
Le produit scalaire détermine l’angle \((\theta)\) entre les vecteurs.
Il quantifie combien un vecteur s’étend dans la direction d’un autre.
Sa valeur est zéro, si les vecteurs sont perpendiculaires\((\theta = 90^\circ)\).
Interprétation géométrique
La régression logistique utilise une combinaison linéaire des attributs d’entrée, \(\mathbf{w} \cdot \mathbf{x} + b\), comme argument pour la fonction sigmoïde (logistique).
Géométriquement, \(\mathbf{w}\) peut être vu comme un vecteur normal à un hyperplan dans l’espace des attributs, et tout point \(\mathbf{x}\) est projeté sur \(\mathbf{w}\) via le produit scalaire \(\mathbf{w} \cdot \mathbf{x}\).
Interprétation géométrique
La frontière de décision est là où cette combinaison linéaire est égale à zéro, c’est-à-dire \(\mathbf{w} \cdot \mathbf{x} + b = 0\).
Les points d’un côté de la frontière ont un produit scalaire positif et sont plus susceptibles d’être classés dans la classe positive (1).
Les points de l’autre côté ont un produit scalaire négatif et sont plus susceptibles d’être dans la classe opposée (0).
La fonction sigmoïde convertit simplement cette distance signée en une probabilité entre 0 et 1.
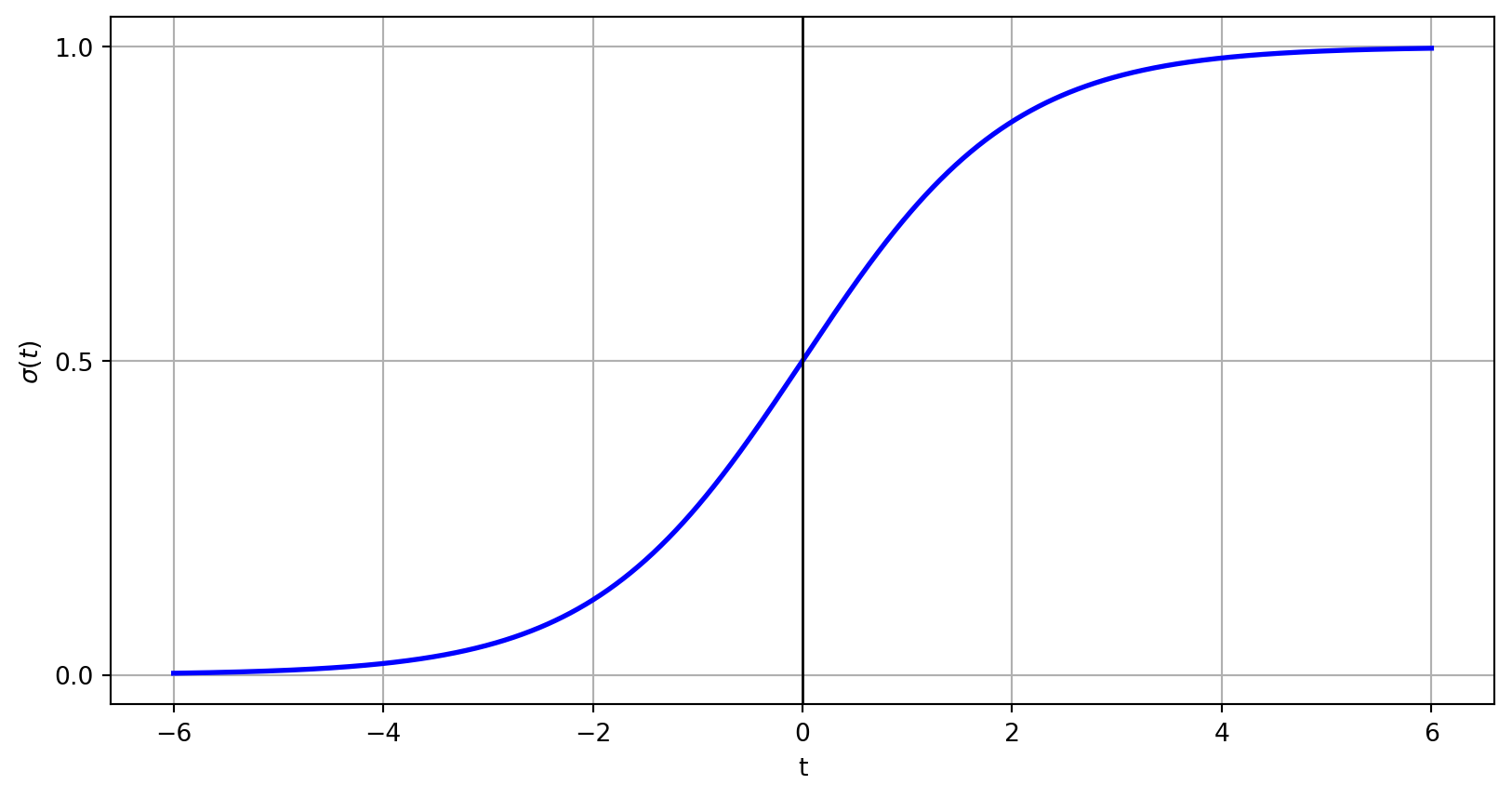
Fonction logistique
\[
\sigma(t) = \frac{1}{1+e^{-t}}
\]
Lorsque \(t \to \infty\), \(e^{-t} \to 0\), donc \(\sigma(t) \to 1\).
Lorsque \(t \to -\infty\), \(e^{-t} \to \infty\), ce qui fait que le dénominateur tend vers l’infini, donc \(\sigma(t) \to 0\).
Quand \(t = 0\), \(e^{-t} = 0\), ce qui donne un dénominateur de 2, donc \(\sigma(t) = 0.5\).
Code
# Fonction sigmoïdedef sigmoid(t):return1/ (1+ np.exp(-t))# Générer des valeurs de tt = np.linspace(-6, 6, 1000)# Calculer les valeurs de y pour la fonction sigmoïdesigma = sigmoid(t)# Créer une figurefig, ax = plt.subplots()ax.plot(t, sigma, color='blue', linewidth=2) # Garder la courbe opaque# Tracer l'axe vertical à x = 0ax.axvline(x=0, color='black', linewidth=1)# Ajouter des étiquettes sur l'axe verticalax.set_yticks([0, 0.5, 1.0])# Ajouter des étiquettes aux axesax.set_xlabel('t')ax.set_ylabel(r'$\sigma(t)$')plt.grid(True)plt.show()
Pourquoi e ?
\[
\sigma(t) = \frac{1}{1+e^{-t}}
\]
Au lieu de \(e\), nous aurions pu utiliser une autre constante, disons 2.
Simplicité de la dérivée : Pour la fonction logistique \(\sigma(x) = \tfrac{1}{1 + e^{-x}}\), la dérivée se simplifie à \(\sigma'(x) = \sigma(x)(1 - \sigma(x))\). Cette forme élégante apparaît parce que la base exponentielle \(e\) a la propriété unique que \(\tfrac{d}{dx} e^x = e^x\), évitant une constante multiplicative supplémentaire.
Code
import mathdef logistic(x, e):"""Calcule une fonction logistique modifiée utilisant b au lieu de e."""return1/ (1+ np.power(e, -x))# Définir une plage de valeurs pour x.x = np.linspace(-6, 6, 400)# Graphique 1 : Variation de e.plt.figure(figsize=(8, 6))e_values = [2, math.e, 4, 8, 16] # différentes valeurs de pentefor e in e_values: plt.plot(x, logistic(x, e), label=f'e = {e}')plt.title('Effet de la variation de e')plt.xlabel('x')plt.ylabel(r'$\frac{1}{1+e^{-x}}$')plt.legend()plt.grid(True)
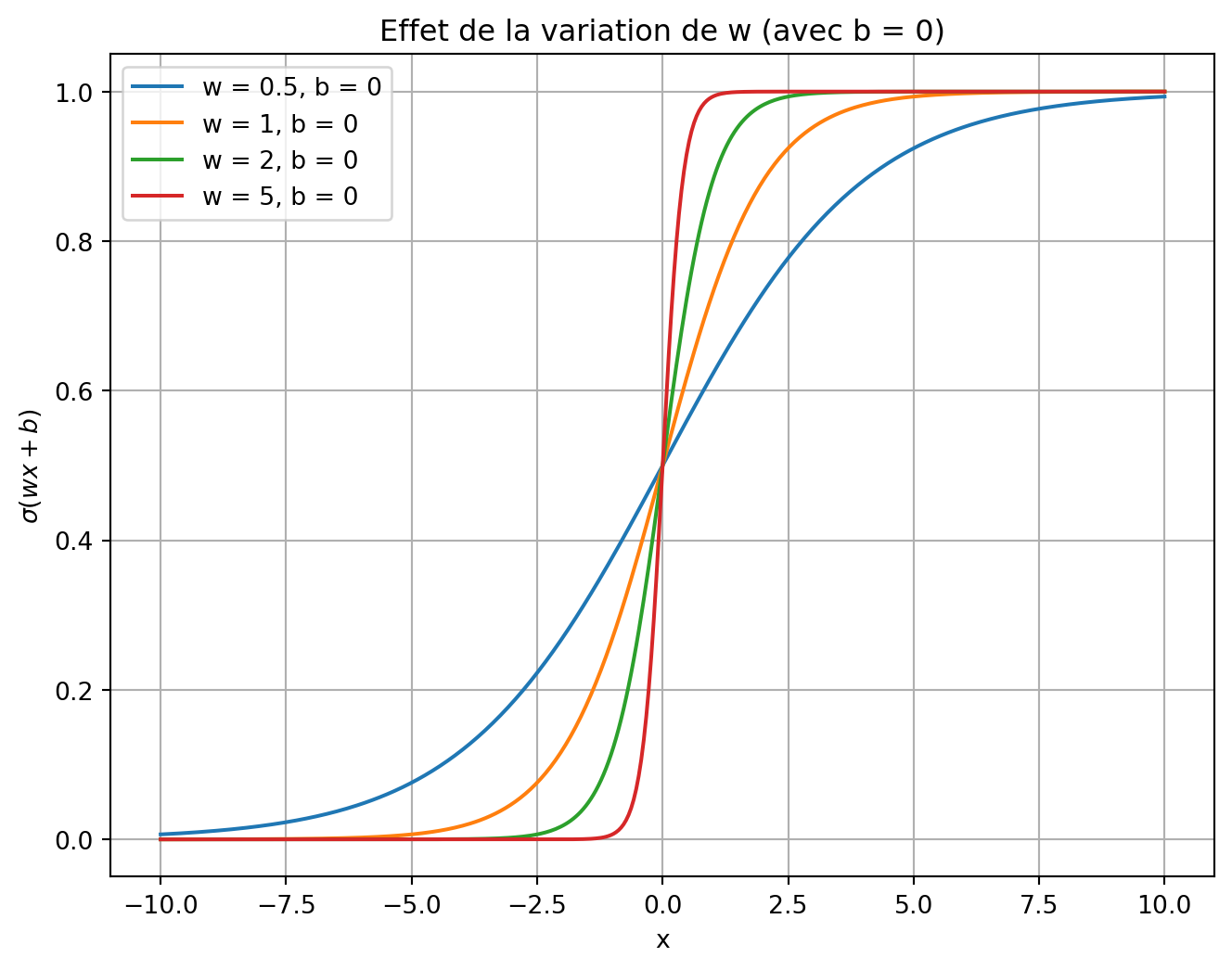
Variation de w
\[
\sigma(wx + b)
\]
Code
def logistic(x, w, b):"""Calcule la fonction logistique avec les paramètres w et b."""return1/ (1+ np.exp(-(w * x + b)))# Définir un intervalle pour les valeurs de x.x = np.linspace(-10, 10, 400)# Graphique 1 : Variation de w (pente) avec b fixé à 0.plt.figure(figsize=(8, 6))w_values = [0.5, 1, 2, 5] # différentes valeurs de penteb =0# biais fixefor w in w_values: plt.plot(x, logistic(x, w, b), label=f'w = {w}, b = {b}')plt.title('Effet de la variation de w (avec b = 0)')plt.xlabel('x')plt.ylabel(r'$\sigma(wx+b)$')plt.legend()plt.grid(True)plt.show()
Variation de b
\[
\sigma(wx + b)
\]
Code
# Graphique 2 : Variation de b (décalage horizontal) avec w fixé à 1.plt.figure(figsize=(8, 6))w =1# pente fixeb_values = [-5, -2, 0, 2, 5] # différentes valeurs de biaisfor b in b_values: plt.plot(x, logistic(x, w, b), label=f'w = {w}, b = {b}')plt.title('Effet de la variation de b (avec w = 1)')plt.xlabel('x')plt.ylabel(r'$\sigma(wx+b)$')plt.legend()plt.grid(True)plt.show()
Implémentation
Génération de données
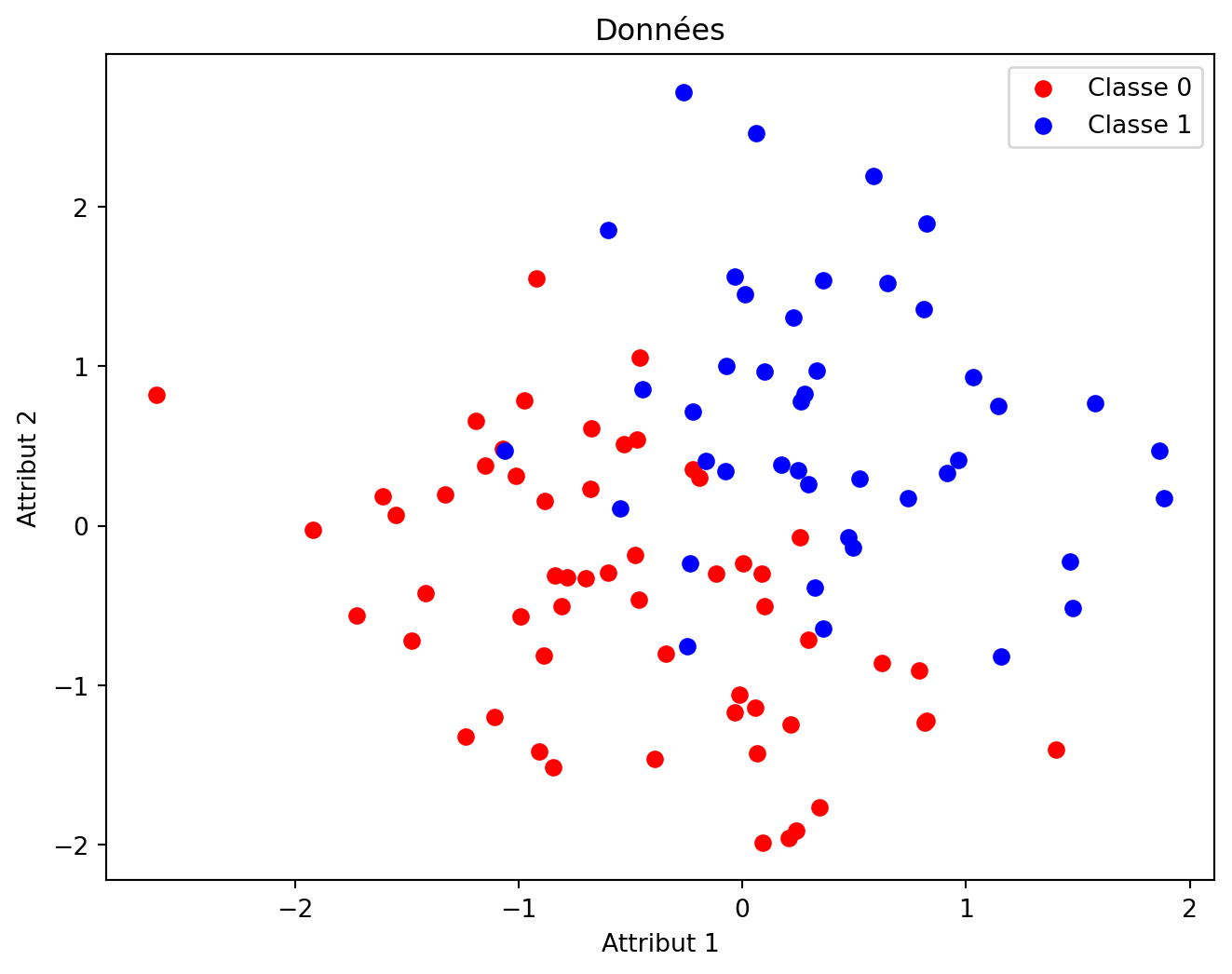
# Générer des données synthétiques pour un problème de classification binairem =100# nombre d'exemplesd =2# nombre d'attributsX = np.random.randn(m, d)# Définir les étiquettes en utilisant une frontière de décision linéaire avec un peu de bruit :noise =0.5* np.random.randn(m)y = (X[:, 0] + X[:, 1] + noise >0).astype(int)
Visualisation
Code
# Visualiser la frontière de décision avec les points de donnéesplt.figure(figsize=(8, 6))plt.scatter(X[y ==0][:, 0], X[y ==0][:, 1], color='red', label='Classe 0')plt.scatter(X[y ==1][:, 0], X[y ==1][:, 1], color='blue', label='Classe 1')plt.xlabel("Attribut 1")plt.ylabel("Attribut 2")plt.title("Données")plt.legend()plt.show()
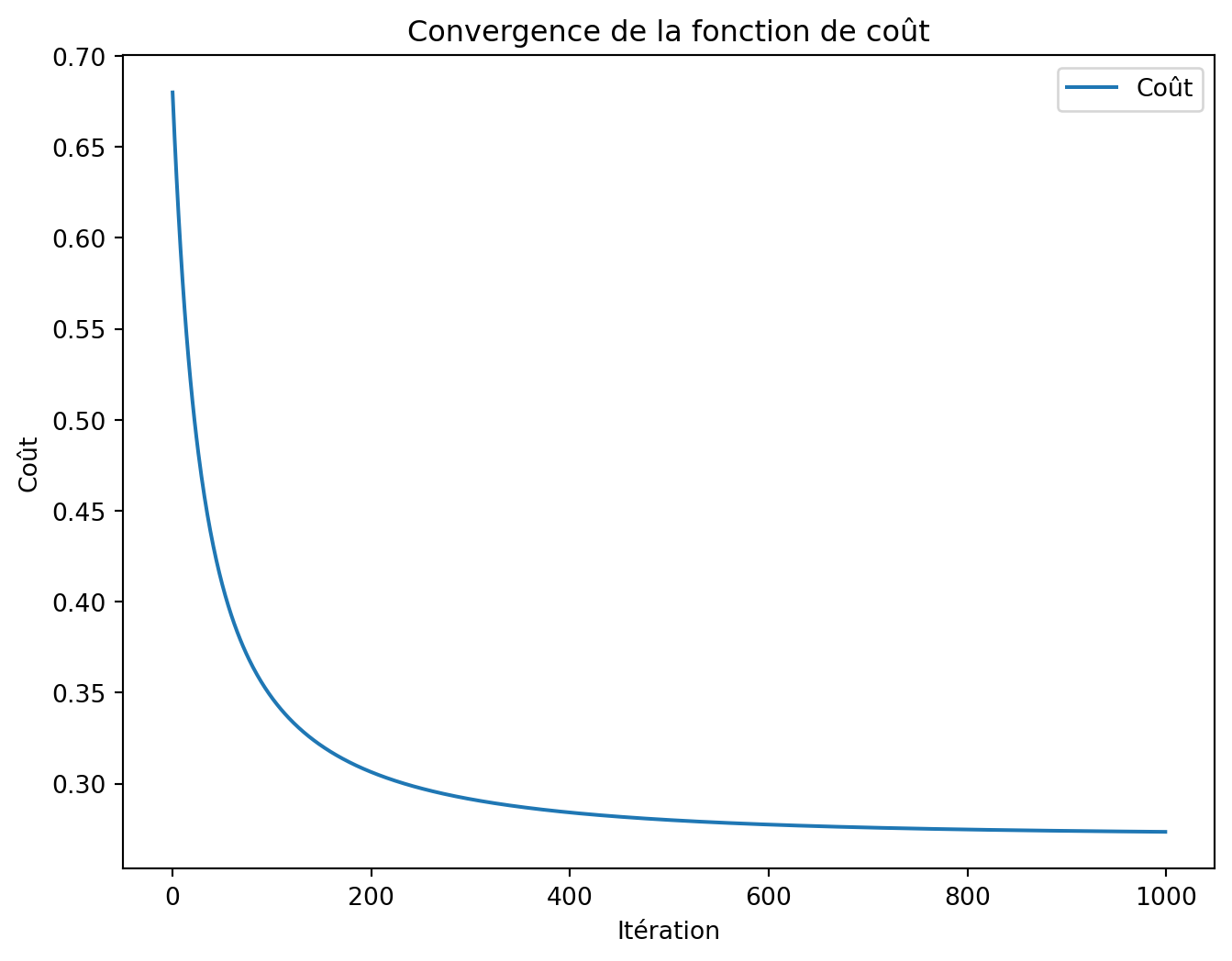
Fonction de coût
# Fonction Sigmoïdedef sigmoid(z):return1/ (1+ np.exp(-z))# Fonction de coût : entropie croisée binairedef cost_function(theta, X, y): m =len(y) h = sigmoid(X.dot(theta)) epsilon =1e-5# éviter log(0) coût =-(1/m) * np.sum(y * np.log(h + epsilon) + (1- y) * np.log(1- h + epsilon))return coût# Gradient de la fonction de coûtdef gradient(theta, X, y): m =len(y) h = sigmoid(X.dot(theta)) grad = (1/m) * X.T.dot(h - y)return grad
Régression logistique
# Entraînement de la régression logistique par descente de gradientdef logistic_regression(X, y, learning_rate=0.1, iterations=1000): m, n = X.shape theta = np.zeros(n) historique_des_coûts = []for i inrange(iterations): theta -= learning_rate * gradient(theta, X, y) historique_des_coûts.append(cost_function(theta, X, y))return theta, historique_des_coûts
Entraînement
# Ajouter le terme d'interception (biais)X_avec_interception = np.hstack([np.ones((m, 1)), X])# Entraîner le modèle de régression logistiquetheta, cost_history = logistic_regression(X_avec_interception, y, learning_rate=0.1, iterations=1000)print("Theta optimisé :", theta)
plt.figure(figsize=(8, 6))plt.plot(cost_history, label="Coût")plt.xlabel("Itération")plt.ylabel("Coût")plt.title("Convergence de la fonction de coût")plt.legend()plt.show()
# Fonction de prédiction : retourne les étiquettes de classe et les probabilités pour de nouvelles donnéesdef predict(theta, X, threshold=0.5): probs = sigmoid(X.dot(theta))return (probs >= threshold).astype(int), probs
Prédictions
# Les nouveaux exemples doivent inclure le terme d'interception.# Exemple négatif (probablement classe 0) : Choisir un point loin dans le quadrant négatif.example_neg = np.array([1, -3, -3])# Exemple positif (probablement classe 1) : Choisir un point loin dans le quadrant positif.example_pos = np.array([1, 3, 3])# Près de la frontière de décision : Choisir x1 = 0 et calculer x2 à partir de l'équation de la frontière de décision.x1_near =0x2_near =-(theta[0] + theta[1] * x1_near) / theta[2]example_near = np.array([1, x1_near, x2_near])
Prédictions (suite)
# Combiner les exemples en un seul tableau pour la prédiction.new_examples = np.vstack([example_neg, example_pos, example_near])labels, probabilities = predict(theta, new_examples)print("\nPrédictions sur de nouveaux exemples:")print("Exemple négatif {} -> Prédiction : {} (Probabilité : {:.4f})".format(example_neg[1:], labels[0], probabilities[0]))print("Exemple positif {} -> Prédiction : {} (Probabilité : {:.4f})".format(example_pos[1:], labels[1], probabilities[1]))print("Exemple près de la frontière {} -> Prédiction : {} (Probabilité : {:.4f})".format(example_near[1:], labels[2], probabilities[2]))
Prédictions sur de nouveaux exemples:
Exemple négatif [-3 -3] -> Prédiction : 0 (Probabilité : 0.0000)
Exemple positif [3 3] -> Prédiction : 1 (Probabilité : 1.0000)
Exemple près de la frontière [0. 0.11760374] -> Prédiction : 1 (Probabilité : 0.5000)
Visualisation du vecteur de poids
Lors du cours précédent, nous avons établi que la régression logistique détermine un vecteur de poids qui est orthogonal à la frontière de décision.
Inversement, la frontière de décision elle-même est orthogonale au vecteur de poids, qui est dérivé par l’optimisation par descente de gradient.
Visualisation du vecteur de poids
Code
# Tracer la frontière de décision et les points de donnéesplt.figure(figsize=(8, 6))plt.scatter(X[y ==0][:, 0], X[y ==0][:, 1], color='red', label='Classe 0')plt.scatter(X[y ==1][:, 0], X[y ==1][:, 1], color='blue', label='Classe 1')# Frontière de décision : theta0 + theta1*x1 + theta2*x2 = 0x_vals = np.array([min(X[:, 0]) -1, max(X[:, 0]) +1])y_vals =-(theta[0] + theta[1] * x_vals) / theta[2]plt.plot(x_vals, y_vals, label='Frontière de décision', color='green')# --- Dessiner le vecteur normal ---# Le vecteur normal est (theta[1], theta[2]).# Choisir un point de référence sur la frontière de décision. Ici, nous utilisons x1 = 0 :x_ref =0y_ref =-theta[0] / theta[2] # quand x1=0, theta0 + theta2*x2=0 => x2=-theta0/theta2# Créer le vecteur normal à partir de (theta[1], theta[2]).normal = np.array([theta[1], theta[2]])# Normaliser et ajuster pour l'affichagenormal_norm = np.linalg.norm(normal)if normal_norm !=0: normal_unit = normal / normal_normelse: normal_unit = normalscale =2# ajuster l'échelle selon les besoinsnormal_display = normal_unit * scale# Dessiner une flèche en commençant au point de référenceplt.arrow(x_ref, y_ref, normal_display[0], normal_display[1], head_width=0.1, head_length=0.2, fc='black', ec='black')plt.text(x_ref + normal_display[0]*1.1, y_ref + normal_display[1]*1.1, r'$(\theta_1, \theta_2)$', color='black', fontsize=12)plt.xlabel("Attribut 1")plt.ylabel("Attribut 2")plt.title("Frontière de cécision de la régression logistique et vecteur normal")plt.legend()plt.gca().set_aspect('equal', adjustable='box')plt.ylim(-3, 3)plt.show()
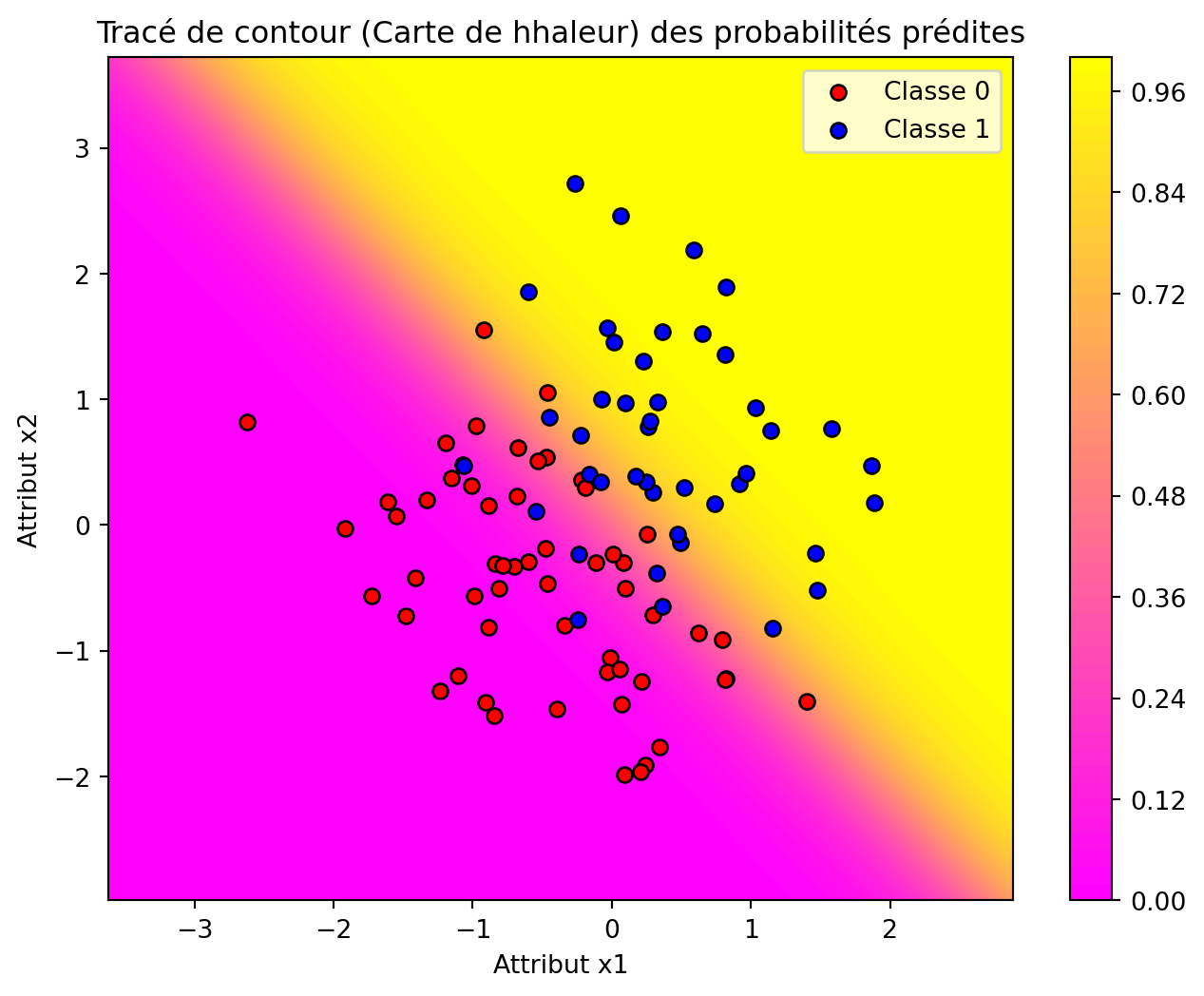
Près de la frontière de décision
Code
# --- Configuration de la Visualisation ---# Créer une grille sur l'espace des attributsx1_range = np.linspace(X[:, 0].min()-1, X[:, 0].max()+1, 100)x2_range = np.linspace(X[:, 1].min()-1, X[:, 1].max()+1, 100)xx1, xx2 = np.meshgrid(x1_range, x2_range)# Construire l'entrée de la grille (avec interception) pour les prédictionsgrid = np.c_[np.ones(xx1.ravel().shape), xx1.ravel(), xx2.ravel()]# Calculer les probabilités prédites sur la grilleprobs = sigmoid(grid.dot(theta)).reshape(xx1.shape)# --- Approche 2 : Tracé de contour 2D (Carte de chaleur) ---plt.figure(figsize=(8, 6))contour = plt.contourf(xx1, xx2, probs, cmap='spring', levels=50)plt.colorbar(contour)plt.xlabel('Attribut x1')plt.ylabel('Attribut x2')plt.title('Tracé de contour (Carte de hhaleur) des probabilités prédites')# Superposer les données d'entraînementplt.scatter(X[y ==0][:, 0], X[y ==0][:, 1], color='red', edgecolor='k', label='Classe 0')plt.scatter(X[y ==1][:, 0], X[y ==1][:, 1], color='blue', edgecolor='k', label='Classe 1')plt.legend()plt.show()
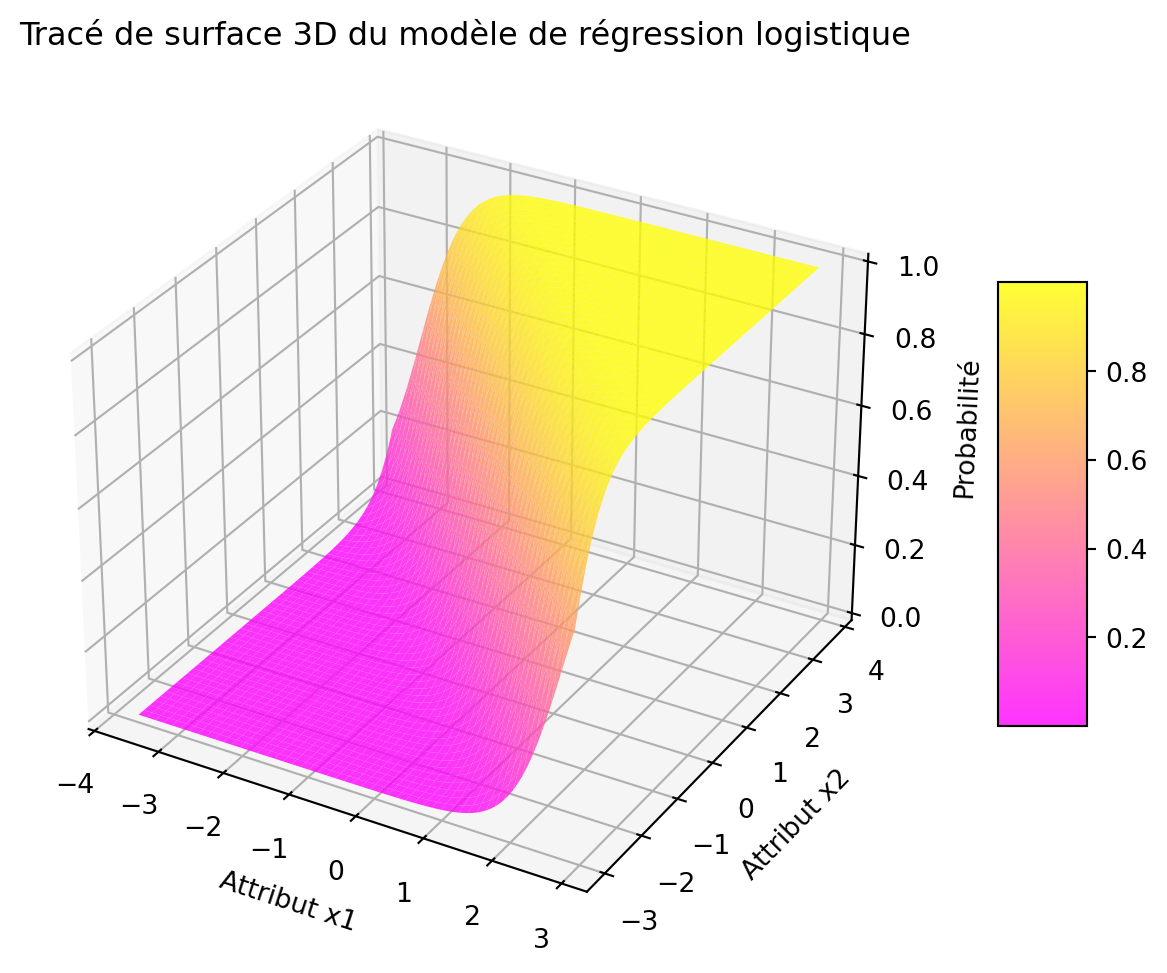
Près de la frontière de décision
Code
# --- Approche 1 : Tracé de Surface 3D ---fig = plt.figure(figsize=(12, 6))ax = fig.add_subplot(111, projection='3d')surface = ax.plot_surface(xx1, xx2, probs, cmap='spring', alpha=0.8)ax.set_xlabel('Attribut x1')ax.set_ylabel('Attribut x2')ax.set_zlabel('Probabilité')ax.set_title('Tracé de surface 3D du modèle de régression logistique')fig.colorbar(surface, shrink=0.5, aspect=5)plt.show()
Prologue
Résumé
Dans cette présentation, nous avons :
Dérivé les formulations de la vraisemblance et de la log-vraisemblance négative.
Illustré l’interprétation géométrique des frontières de décision et des vecteurs de poids.
Implémenté la régression logistique avec la descente de gradient et visualisé les résultats.
Prochain cours
Mesures de performance et évaluation croisée
Références
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.