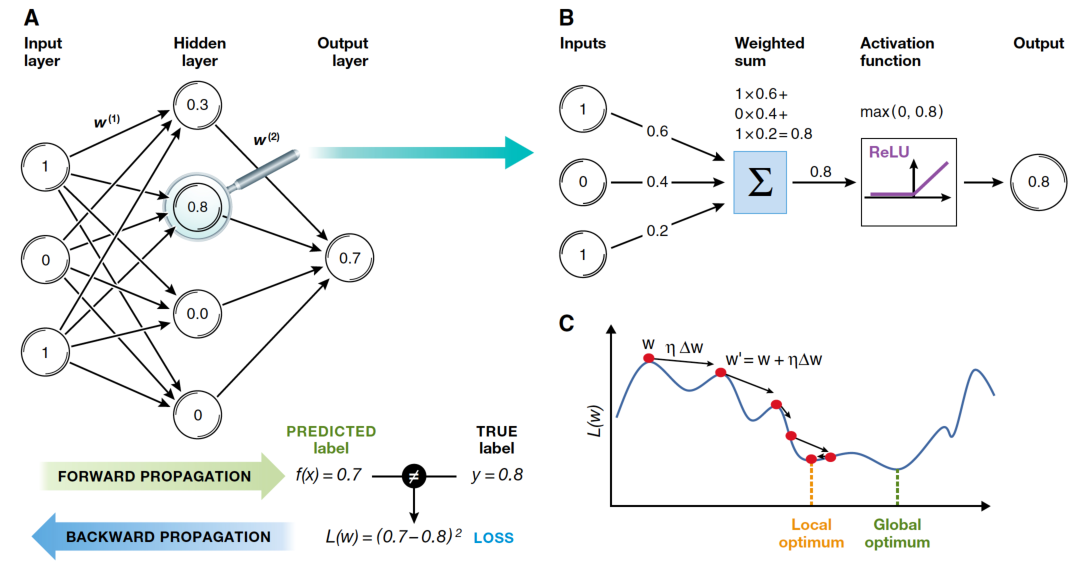
Entraîner un réseau de neurones artificiels (partie 2)
CSI 4106 - Automne 2025
Version: oct. 26, 2025 12h06
Message du Jour


Idée Conceptuelle
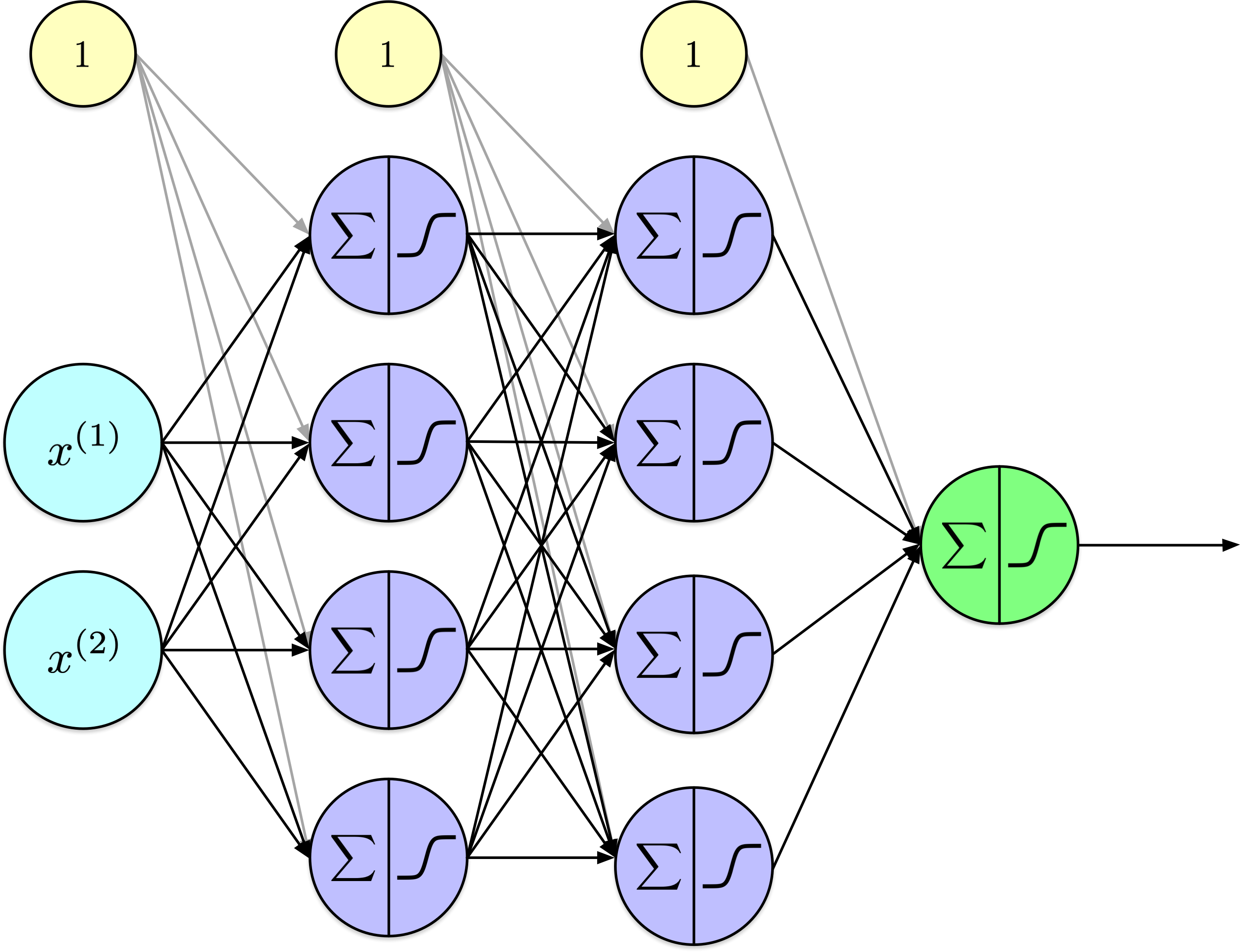
Idée Conceptuelle (suite)
Idée Conceptuelle (suite)
Application récursive
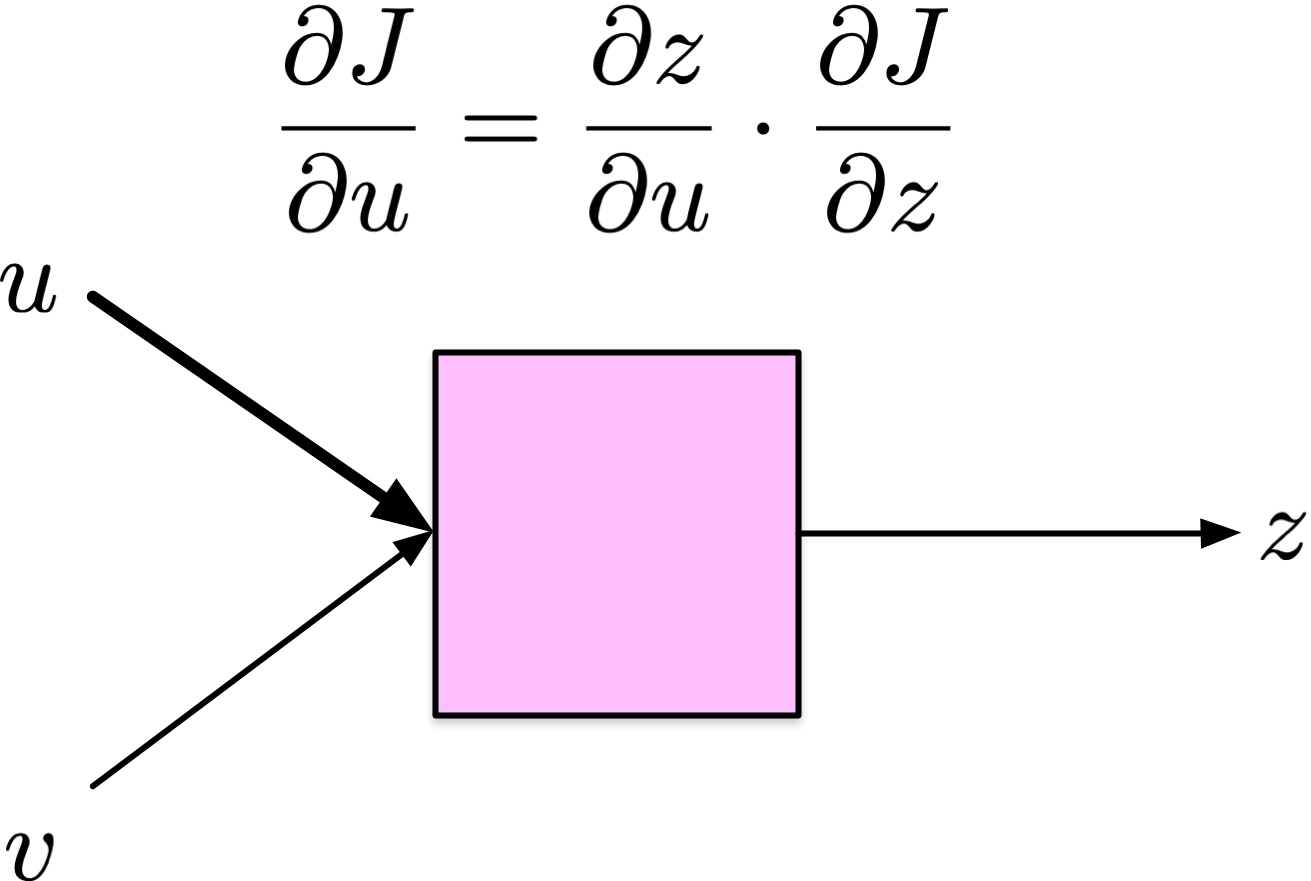
Graphe computationnel
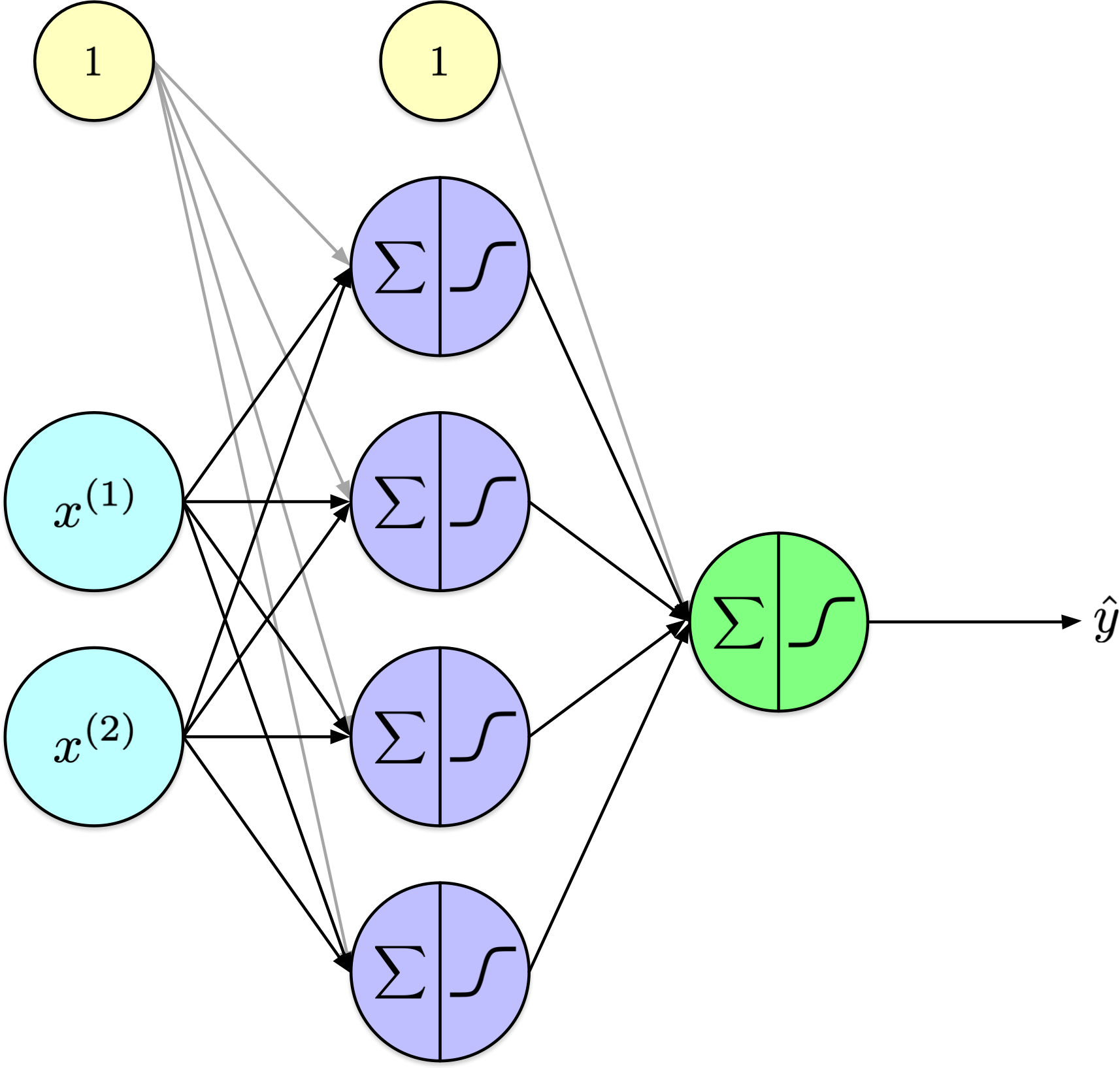
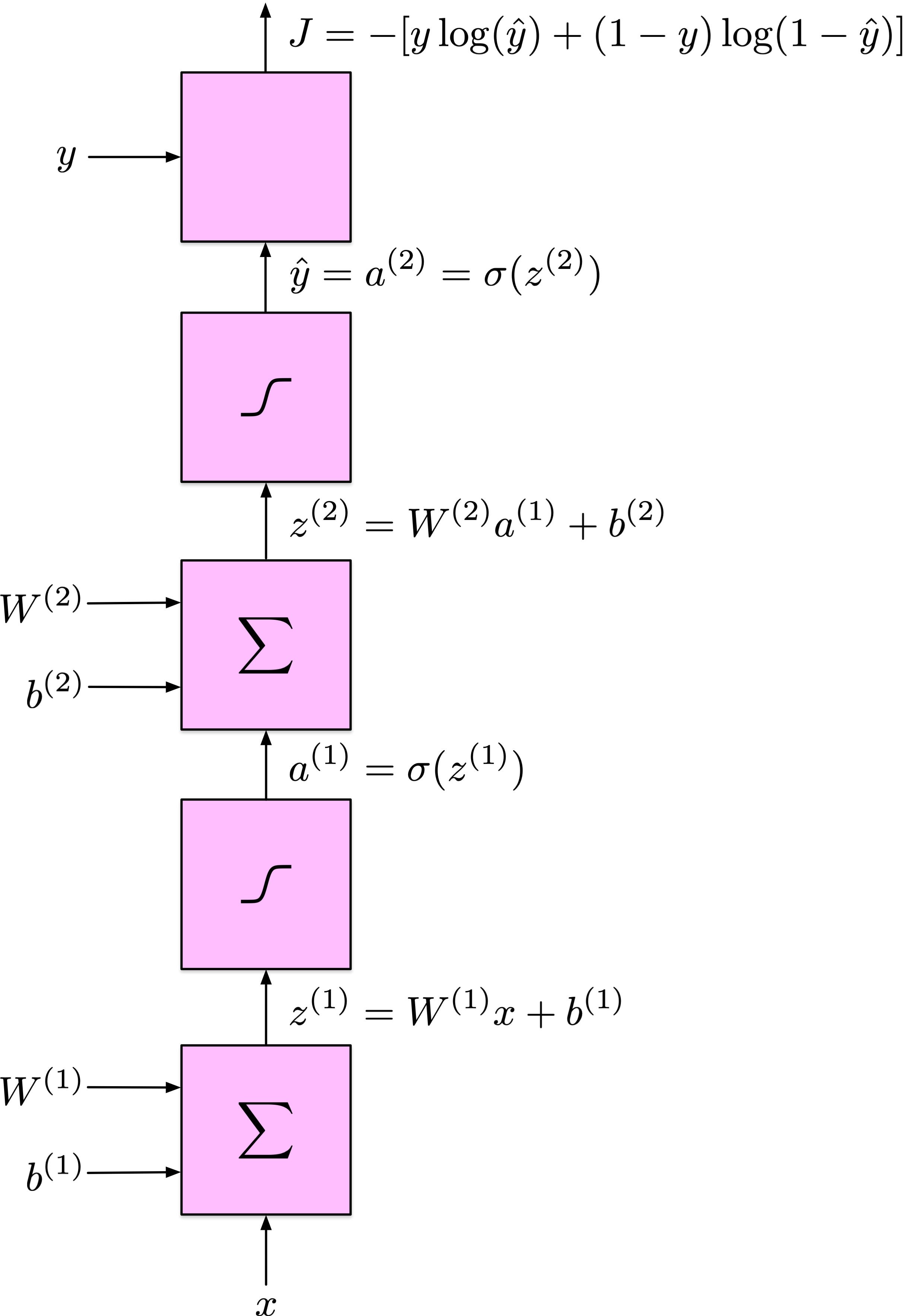
Entrée scalaire; un nœud caché
Soit
\[ J = -\Bigl[y \,\log(\hat y) + (1-y)\,\log(1-\hat y)\Bigr] \]
\[ \hat y = a_2 = \sigma(z_2), \quad z_2 = w_2 \cdot a_1 + b_2 \]
\[ a_1 = \sigma(z_1), \quad z_1 = w_1 \cdot x + b_1 \]
Dérivées
\[ \frac{\partial J}{\partial \hat{y}} \]
\[ \frac{\partial \hat{y}}{\partial z_2} \]
\[ \frac{\partial z_2}{\partial w_2}, \quad \frac{\partial z_2}{\partial b_2}, \quad \frac{\partial z_2}{\partial a_1}, \]
\[ \frac{\partial a_1}{\partial z_1}, \]
\[ \frac{\partial z_1}{\partial w_1}, \quad \frac{\partial z_1}{\partial b_1}, \quad \frac{\partial z_1}{\partial x}, \]
Dérivées
Dérivée de la perte par rapport à \(\hat{y}\) :
\[ \frac{\partial J}{\partial \hat{y}} = -\left(\frac{y}{\hat{y}}-\frac{1-y}{1-\hat{y}}\right) \]
Dérivées
Dérivée de \(\hat{y}\) par rapport à \(z_2\):
\[ \frac{\partial \hat{y}}{\partial z_2}=\sigma^{\prime}\left(z_2\right)=\hat{y}(1-\hat{y}) \]
Dérivées
Dérivée \(z_2 = w_2 a_1 + b_2\):
\[ \frac{\partial z_2}{\partial w_2}=a_1, \quad \frac{\partial z_2}{\partial b_2}=1, \quad \frac{\partial z_2}{\partial a_1}=w_2 \]
Dérivées
Dérivée \(a_1 = \sigma(z_1)\) :
\[ \frac{\partial a_1}{\partial z_1}=\sigma^{\prime}\left(z_1\right)=a_1\left(1-a_1\right) \]
Dérivées
Dérivée \(z_1 = w_1 x + b_1\) :
\[ \frac{\partial z_1}{\partial w_1}=x, \quad \frac{\partial z_1}{\partial b_1}=1, \quad \frac{\partial z_1}{\partial x} = w_1 \]
Dérivées combinées
Pour \(w_2\) :
\[ \frac{\partial J}{\partial w_2}=\frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z_2} \cdot \frac{\partial z_2}{\partial w_2}=\left[-\left(\frac{y}{\hat{y}}-\frac{1-y}{1-\hat{y}}\right)\right] \cdot(\hat{y}(1-\hat{y})) \cdot a_1 \]
Se simplifie en :
\[ \frac{\partial J}{\partial w_2}=(\hat{y}-y) a_1 \]
Dérivées combinées
Pour \(b_2\) :
\[ \frac{\partial J}{\partial b_2}=\frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z_2} \cdot \frac{\partial z_2}{\partial b_2}=(\hat{y}-y) \cdot 1=\hat{y}-y \]
Dérivées combinées
Pour \(w_1\) :
\[ \frac{\partial J}{\partial w_1}=\frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z_2} \cdot \frac{\partial z_2}{\partial a_1} \cdot \frac{\partial a_1}{\partial z_1} \cdot \frac{\partial z_1}{\partial w_1} \]
Substituer :
\[ =\left[-\left(\frac{y}{\hat{y}}-\frac{1-y}{1-\hat{y}}\right)\right] \cdot(\hat{y}(1-\hat{y})) \cdot w_2 \cdot\left(a_1\left(1-a_1\right)\right) \cdot x \]
Se simplifie à :
\[ \frac{\partial J}{\partial w_1}=(\hat{y}-y) w_2\left(a_1\left(1-a_1\right)\right) x \]
Dérivées combinées
Pour \(b_1\) :
\[ \frac{\partial J}{\partial b_1}=\frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z_2} \cdot \frac{\partial z_2}{\partial a_1} \cdot \frac{\partial a_1}{\partial z_1} \cdot \frac{\partial z_1}{\partial b_1} \]
Substituer :
\[ =(\hat{y}-y) w_2\left(a_1\left(1-a_1\right)\right) \cdot 1 \]
Se simplifie à :
\[ \frac{\partial J}{\partial b_1}=(\hat{y}-y) w_2\left(a_1\left(1-a_1\right)\right) \]
Dérivées clés
\[ \begin{align} \frac{\partial J}{\partial w_2} & = (\hat{y}-y) a_1 \\ \frac{\partial J}{\partial b_2} & = \hat{y}-y \\ \frac{\partial J}{\partial w_1} & = (\hat{y}-y) w_2\left(a_1\left(1-a_1\right)\right) x \\ \frac{\partial J}{\partial b_1} & = (\hat{y}-y) w_2\left(a_1\left(1-a_1\right)\right) \\ \end{align} \]
Dérivées clés
\[ \begin{align} \frac{\partial J}{\partial w_2} & = \frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z_2} \cdot \frac{\partial z_2}{\partial w_2}\\ \frac{\partial J}{\partial b_2} & = \frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z_2} \cdot \frac{\partial z_2}{\partial b_2}\\ \frac{\partial J}{\partial w_1} & = \frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z_2} \cdot \frac{\partial z_2}{\partial a_1} \cdot \frac{\partial a_1}{\partial z_1} \cdot \frac{\partial z_1}{\partial w_1}\\ \frac{\partial J}{\partial b_1} & = \frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z_2} \cdot \frac{\partial z_2}{\partial a_1} \cdot \frac{\partial a_1}{\partial z_1} \cdot \frac{\partial z_1}{\partial b_1}\\ \end{align} \]
Dérivées clés
Soit \[ \begin{align} \delta_1 & = \frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z_2} \\ \delta_2 & = \delta_1 \cdot \frac{\partial z_2}{\partial a_1} \cdot \frac{\partial a_1}{\partial z_1} \end{align} \]
Réécrire \[ \begin{align} \frac{\partial J}{\partial w_2} & = \delta_1 \cdot \frac{\partial z_2}{\partial w_2}\\ \frac{\partial J}{\partial b_2} & = \delta_1 \cdot \frac{\partial z_2}{\partial b_2}\\ \frac{\partial J}{\partial w_1} & = \delta_2 \cdot \frac{\partial z_1}{\partial w_1}\\ \frac{\partial J}{\partial b_1} & = \delta_2 \cdot \frac{\partial z_1}{\partial b_1}\\ \end{align} \]
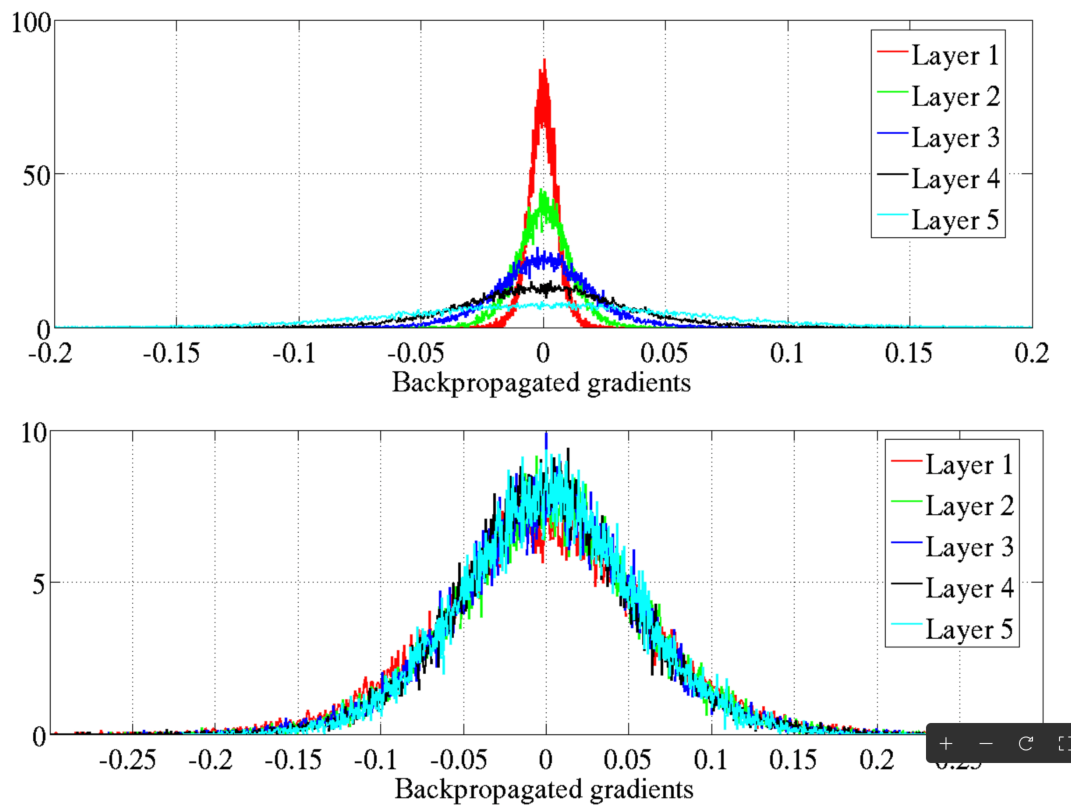
Glorot et Bengio
Figure 6
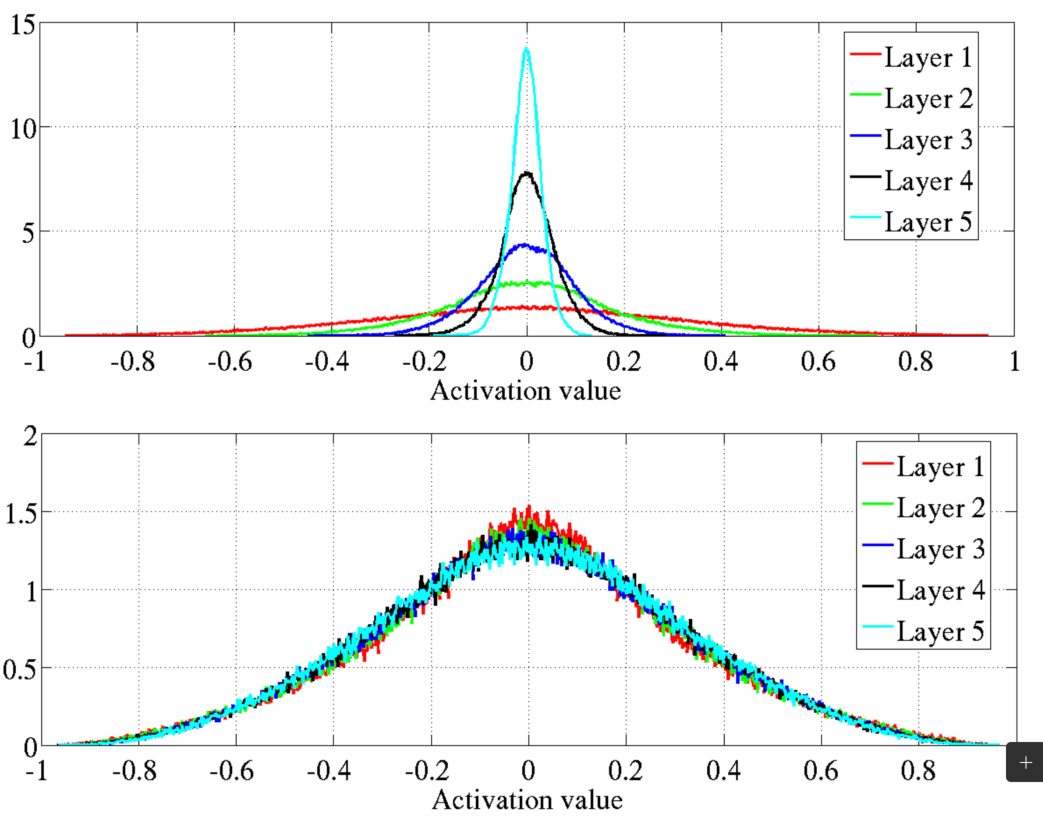
Figure 7
Fonction d’Activation : Leaky ReLU
Afficher le code
import numpy as np
import matplotlib.pyplot as plt
# Définir la fonction Leaky ReLU
def leaky_relu(x, alpha=0.21):
return np.where(x > 0, x, alpha * x)
# Définir la dérivée de la fonction Leaky ReLU
def leaky_relu_derivative(x, alpha=0.2):
return np.where(x > 0, 1, alpha)
# Générer une gamme de valeurs d'entrée
x_values = np.linspace(-4, 4, 400)
# Calculer le Leaky ReLU et sa dérivée
leaky_relu_values = leaky_relu(x_values)
leaky_relu_derivative_values = leaky_relu_derivative(x_values)
# Créer le graphique
plt.figure(figsize=(5, 3))
# Tracer le Leaky ReLU
plt.subplot(1, 2, 1)
plt.plot(x_values, leaky_relu_values, label='Leaky ReLU', color='blue')
plt.title('Fonction d\'Activation Leaky ReLU')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.grid(True)
plt.axhline(0, color='black',linewidth=0.5)
plt.axvline(0, color='black',linewidth=0.5)
plt.legend()
# Tracer la dérivée du Leaky ReLU
plt.subplot(1, 2, 2)
plt.plot(x_values, leaky_relu_derivative_values, label='Dérivée de Leaky ReLU', color='red')
plt.title('Dérivée de Leaky ReLU')
plt.xlabel('x')
plt.ylabel("f'(x)")
plt.grid(True)
plt.axhline(0, color='black',linewidth=0.5)
plt.axvline(0, color='black',linewidth=0.5)
plt.legend()
# Afficher les graphiques
plt.tight_layout()
plt.show()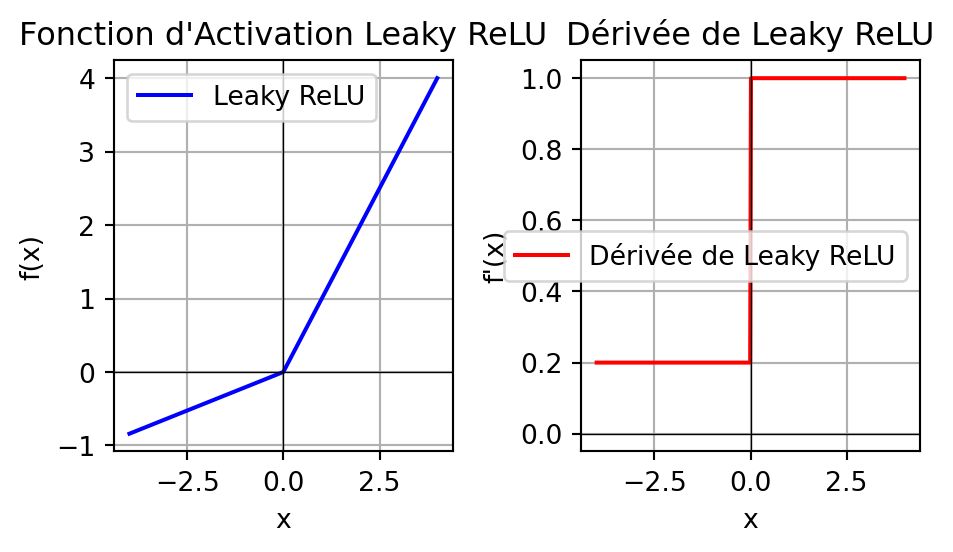
Résumé