Softmax, entropie croisée, régularisation
CSI 4506 - Automne 2025
Marcel Turcotte
Version: oct. 28, 2025 15h35
Préambule
Message du jour

Objectifs d’apprentissage
- Couche Softmax :
- Décrire sa fonctionnalité dans la conversion des logits en distributions de probabilités pour les tâches de classification.
- Perte d’Entropie Croisée :
- Expliquer son rôle dans la mesure de la dissimilarité entre les distributions de probabilités prédites et réelles.
- Techniques de Régularisation :
- Explorer des méthodes comme la régularisation L1, L2 et le dropout pour améliorer les capacités de généralisation des réseaux neuronaux.
Couche de sortie
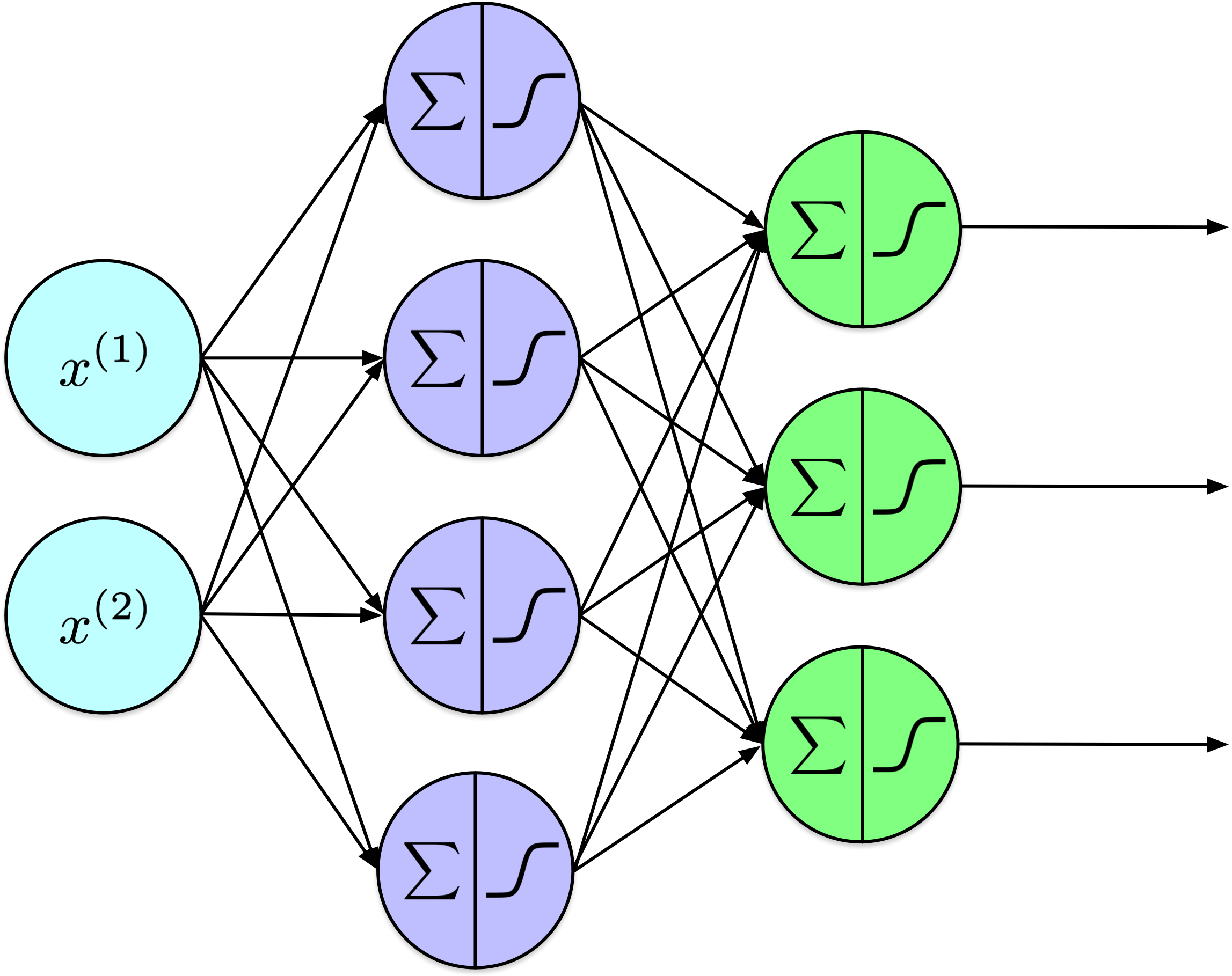
Couche de sortie : tâche de régression
- # de neurones de sortie :
- 1 par dimension
- Fonction d’activation de la couche de sortie :
- Aucune, ReLU/softplus si positif, sigmoid/tanh si borné
- Fonction de perte :
Couche de sortie : Multi-étiquette
Couche de sortie : tâche de classification
- # de neurones de sortie :
- 1 si binaire, 1 par classe si multiclasse ou multilabel.
- Fonction d’activation de la couche de sortie :
- sigmoid si binaire ou multilabel, softmax si multiclasses.
- Fonction de perte :
- entropie croisée
Softmax
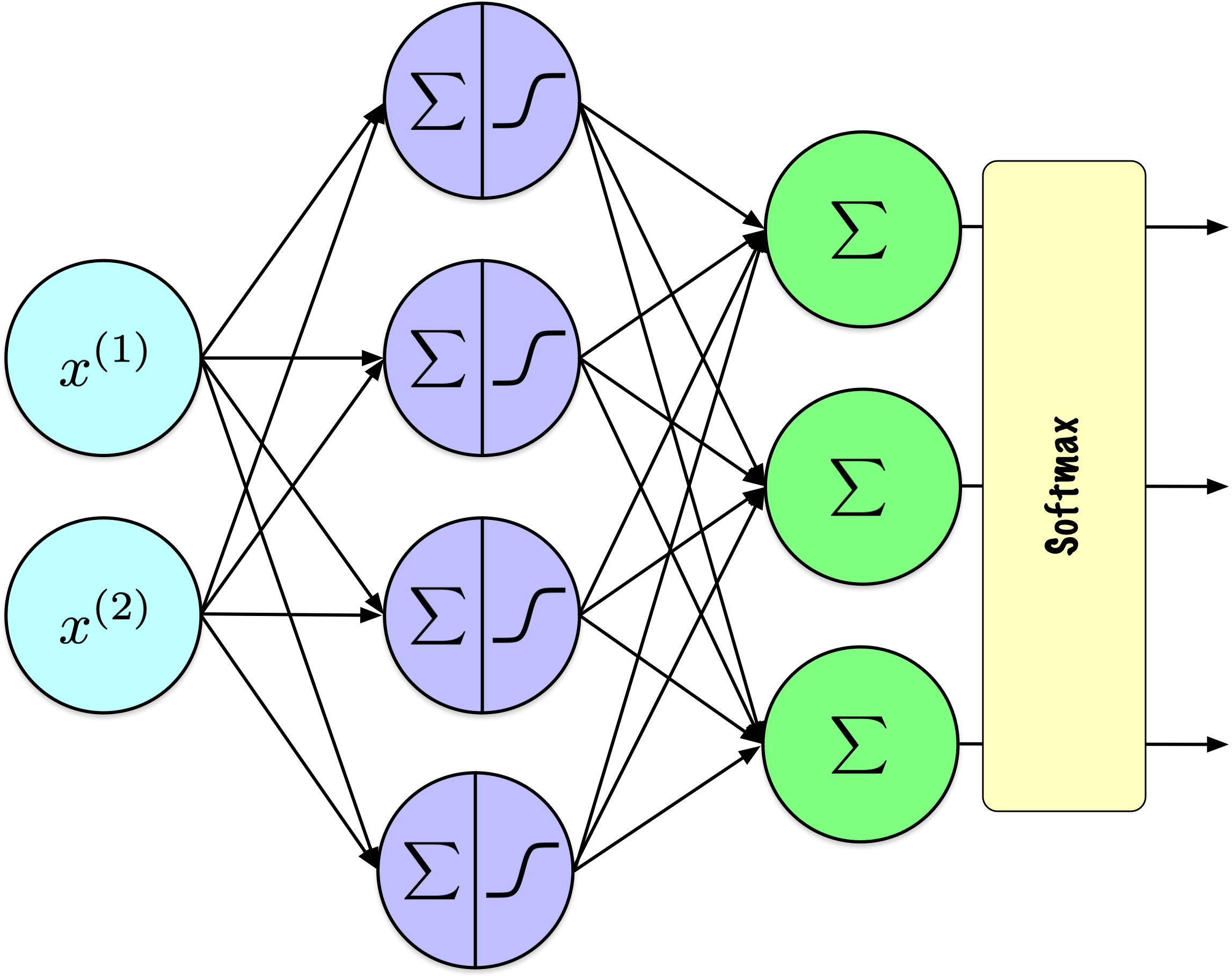
Softmax
La fonction softmax est une fonction d’activation utilisée dans les problèmes de classification multiclasses pour convertir un vecteur de scores bruts en probabilités qui totalisent 1.
Étant donné un vecteur \(\mathbf{z} = [z_1, z_2, \ldots, z_n]\) :
\[ \sigma(\mathbf{z})_i = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}} \]
où \(\sigma(\mathbf{z})_i\) est la probabilité de la classe \(i\), et \(n\) est le nombre de classes.
Softmax
| \(z_1\) | \(z_2\) | \(z_3\) | \(\sigma(z_1)\) | \(\sigma(z_2)\) | \(\sigma(z_3)\) | \(\sum\) |
|---|---|---|---|---|---|---|
| 1.47 | -0.39 | 0.22 | 0.69 | 0.11 | 0.20 | 1.00 |
| 5.00 | 6.00 | 4.00 | 0.24 | 0.67 | 0.09 | 1.00 |
| 0.90 | 0.80 | 1.10 | 0.32 | 0.29 | 0.39 | 1.00 |
| -2.00 | 2.00 | -3.00 | 0.02 | 0.98 | 0.01 | 1.00 |
Softmax
Fonction de perte d’entropie croisée
L’entropie croisée dans une tâche de classification multiclasses pour un exemple :
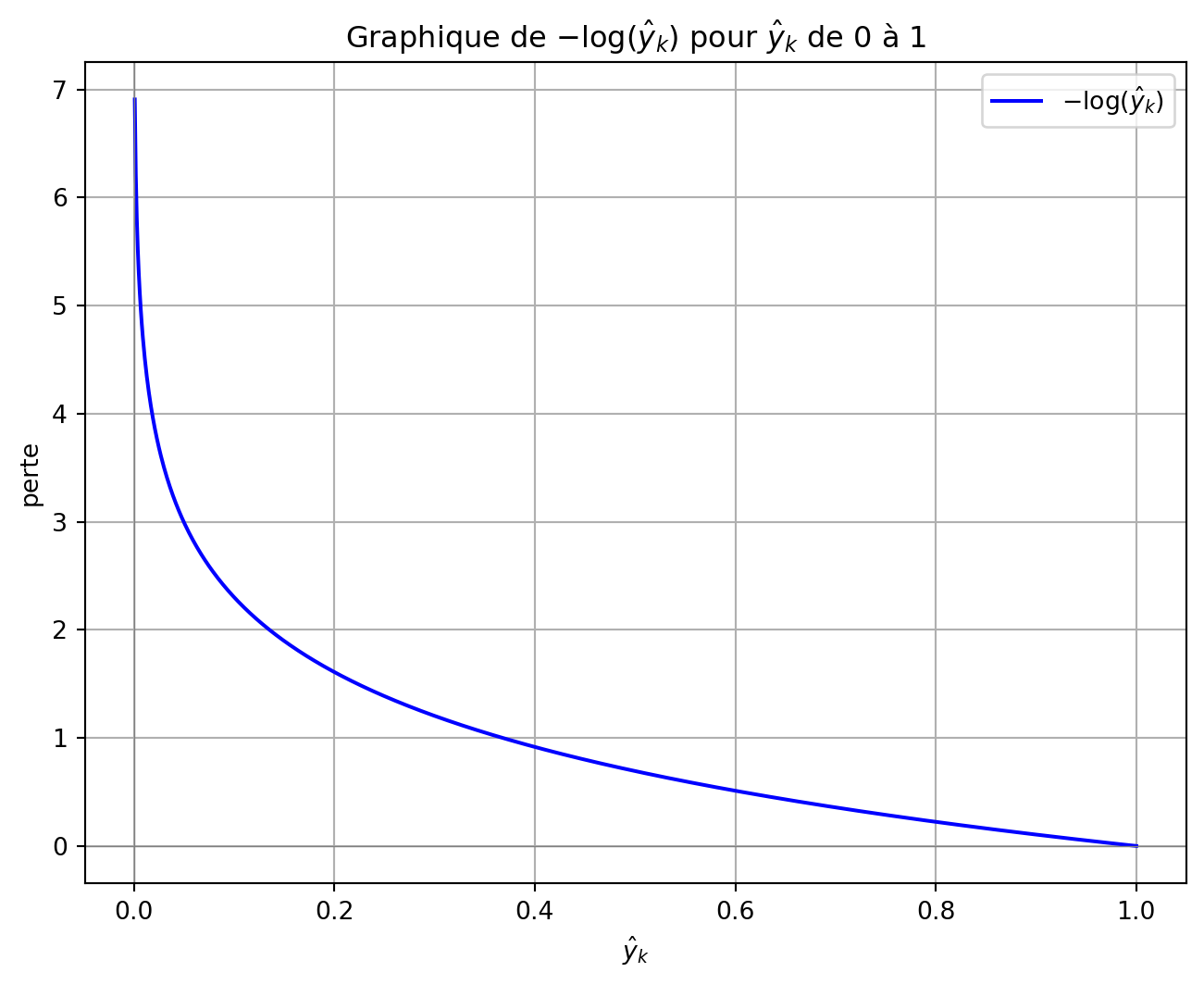
\[ J(W) = -\sum_{k=1}^{K} y_k \log(\hat{y}_k) \]
Où :
- \(K\) est le nombre de classes.
- \(y_k\) est la distribution réelle pour la classe \(k\).
- \(\hat{y}_k\) est la probabilité prédite de la classe \(k\) par le modèle.
Fonction de perte d’entropie croisée
- Problème de classification : 3 classes
- Versicolour, Setosa, Virginica.
- Encodage one-hot :
- Setosa = \([0, 1, 0]\).
- Sorties Softmax & Perte :
- \([0.22,\mathbf{0.7}, 0.08]\) : Perte = \(-\log(0.7) = 0.3567\).
- \([0.7, \mathbf{0.22}, 0.08]\) : Perte = \(-\log(0.22) = 1.5141\).
- \([0.7, \mathbf{0.08}, 0.22]\) : Perte = \(-\log(0.08) = 2.5257\).
Cas : un exemple
Cas : ensemble de données
Pour un ensemble de données avec \(N\) exemples, la perte moyenne d’entropie croisée sur tous les exemples est calculée comme suit :
\[ L = -\frac{1}{N} \sum_{i=1}^{N} \sum_{k=1}^{K} y_{i,k} \log(\hat{y}_{i,k}) \]
Où :
- \(i\) est l’index des exemples dans l’ensemble de données.
- \(y_{i,k}\) et \(\hat{y}_{i,k}\) sont respectivement les valeurs réelles et les probabilités prédites pour la classe \(k\) de l’exemple \(i\).
Régularisation
Définition
La régularisation regroupe un ensemble de techniques visant à améliorer la capacité de généralisation d’un modèle en atténuant le surapprentissage. En décourageant une complexité excessive du modèle, ces méthodes améliorent la robustesse et la performance du modèle sur des données non vues.
Ajout de termes de pénalité à la perte
En optimisation numérique, il est courant d’ajouter des termes supplémentaires à la fonction objectif afin de dissuader certaines caractéristiques indésirables du modèle.
Pour un problème de minimisation, le processus d’optimisation vise à éviter des coûts élevés associés à ces termes de pénalité.
Fonction de perte
Prenons la fonction de perte de l’erreur absolue moyenne :
\[ \mathrm{MAE}(X,W) = \frac{1}{N} \sum_{i=1}^{N} | h_W(x_i) - y_i | \]
Où :
- \(W\) sont les poids de notre réseau.
- \(h_W(x_i)\) est la sortie du réseau pour l’exemple \(i\).
- \(y_i\) est la vraie étiquette pour l’exemple \(i\).
Terme(s) de pénalité
Un ou plusieurs termes peuvent être ajoutés à la perte :
\[ \mathrm{MAE}(X,W) = \frac{1}{N} \sum_{i=1}^{N} | h_W(x_i) - y_i | + \mathrm{pénalité} \]
Norme
Une norme assigne une longueur non négative à un vecteur.
La norme \(\ell_p\) d’un vecteur \(\mathbf{z} = [z_1, z_2, \ldots, z_n]\) est définie comme suit :
\[ \|\mathbf{z}\|_p = \left( \sum_{i=1}^{n} |z_i|^p \right)^{1/p} \]
Normes \(\ell_1\) et \(\ell_2\)
La norme \(\ell_1\) (norme de Manhattan) est :
\[ \|\mathbf{z}\|_1 = \sum_{i=1}^{n} |z_i| \]
La norme \(\ell_2\) (norme euclidienne) est :
\[ \|\mathbf{z}\|_2 = \sqrt{\sum_{i=1}^{n} z_i^2} \]
Régularisation \(l_1\) et \(l_2\)
Ci-dessous, \(\alpha\) et \(\beta\) déterminent le degré de régularisation appliqué ; fixer ces valeurs à zéro désactive effectivement le terme de régularisation.
\[ \mathrm{MAE}(X,W) = \frac{1}{N} \sum_{i=1}^{N} | h_W(x_i) - y_i | + \alpha \ell_1 + \beta \ell_2 \]
Recommandations
- Régularisation \(\ell_1\) :
- Encourage la parcimonie, mettant à zéro beaucoup de poids.
- Utile pour la sélection d’attributs en réduisant la dépendance à certains attributs.
- Régularisation \(\ell_2\) :
- Encourage des poids petits et répartis pour la stabilité.
- Idéal lorsque toutes les attributs contribuent et que la réduction de la complexité est primordiale.
Exemple Keras
Dropout
Le dropout est une technique de régularisation dans les réseaux neuronaux où des neurones sélectionnés aléatoirement sont ignorés pendant l’entraînement, réduisant ainsi le surapprentissage en empêchant la co-adaptation des attributs.
Dropout
Lors de chaque étape d’entraînement, chaque neurone dans une couche de dropout a une probabilité \(p\) d’être exclu du calcul, des valeurs typiques de \(p\) allant de 10 % à 50 %.
Bien que cela puisse sembler contre-intuitif, cette approche empêche le réseau de dépendre de neurones spécifiques, favorisant ainsi la distribution des représentations apprises sur plusieurs neurones.
Dropout
Le dropout est l’une des méthodes de régularisation les plus populaires et les plus efficaces pour réduire le surapprentissage.
L’amélioration typique des performances est modeste, généralement autour de 1 à 2 %.
Keras
import keras
from keras.models import Sequential
from keras.layers import InputLayer, Dropout, Flatten, Dense
model = tf.keras.Sequential([
InputLayer(shape=[28, 28]),
Flatten(),
Dropout(rate=0.2),
Dense(300, activation="relu"),
Dropout(rate=0.2),
Dense(100, activation="relu"),
Dropout(rate=0.2),
Dense(10, activation="softmax")
])Définition
L’arrêt anticipé (early stopping) est une technique de régularisation qui interrompt l’entraînement dès que la performance du modèle sur un ensemble de validation commence à se dégrader, empêchant ainsi le surapprentissage en s’arrêtant avant que le modèle n’apprenne le bruit.
Early Stopping
Prologue
Résumé
- Fonctions de perte :
- Tâches de régression : Erreur quadratique moyenne (MSE).
- Tâches de classification : Perte d’entropie croisée avec activation softmax pour les sorties multiclasses.
- Techniques de régularisation :
- Régularisation L1 et L2 : Ajouter des termes de pénalité à la perte pour décourager les poids élevés.
- Dropout : Désactiver aléatoirement des neurones pendant l’entraînement pour éviter le surapprentissage.
- Early Stopping : Interrompre l’entraînement lorsque la performance de validation se dégrade.
Prochain cours
- Nous introduirons les réseaux convolutifs.
Références
Géron, Aurélien. 2022. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 3ᵉ éd. O’Reilly Media, Inc.
Hinton, Geoffrey E., Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, et Ruslan Salakhutdinov. 2012. « Improving neural networks by preventing co-adaptation of feature detectors ». CoRR abs/1207.0580. http://arxiv.org/abs/1207.0580.
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.
Marcel Turcotte
École de science informatique et de génie électrique (SIGE)
Université d’Ottawa