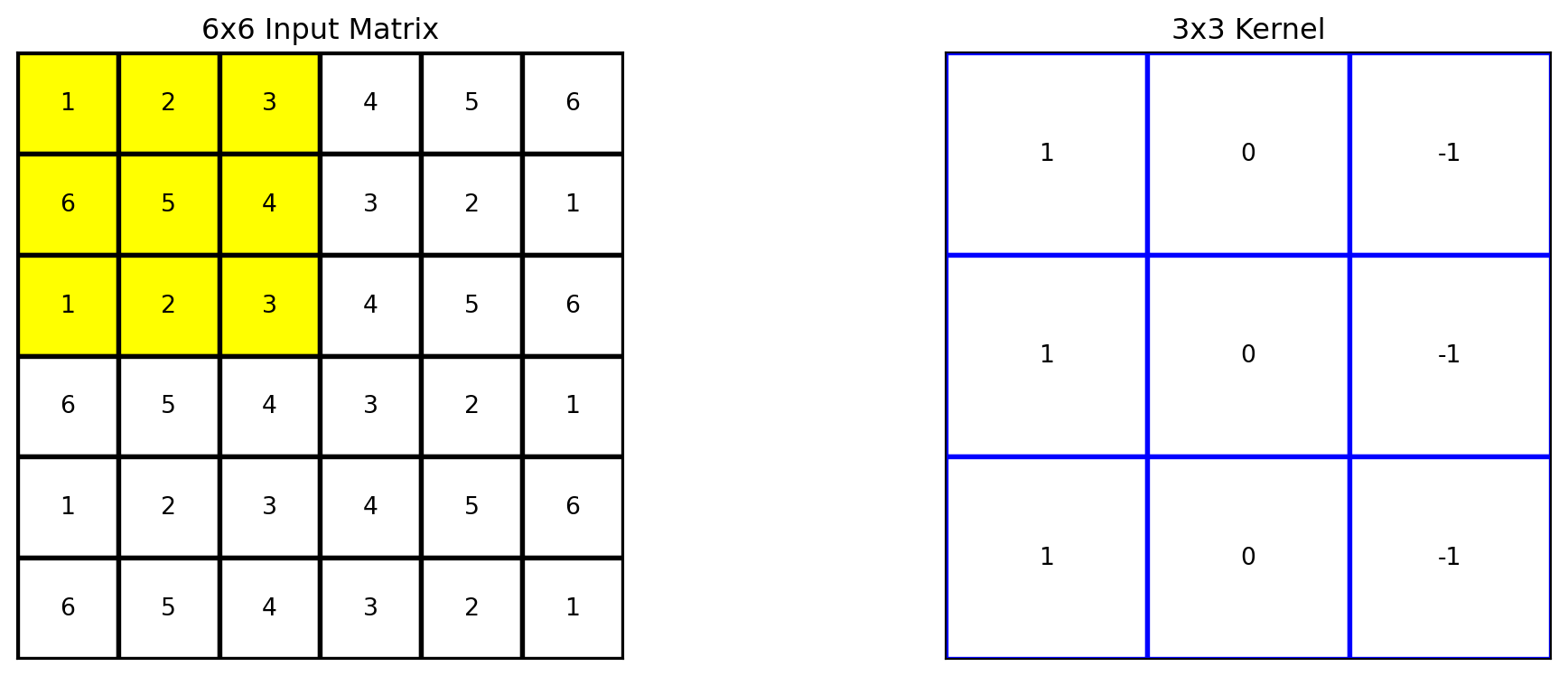
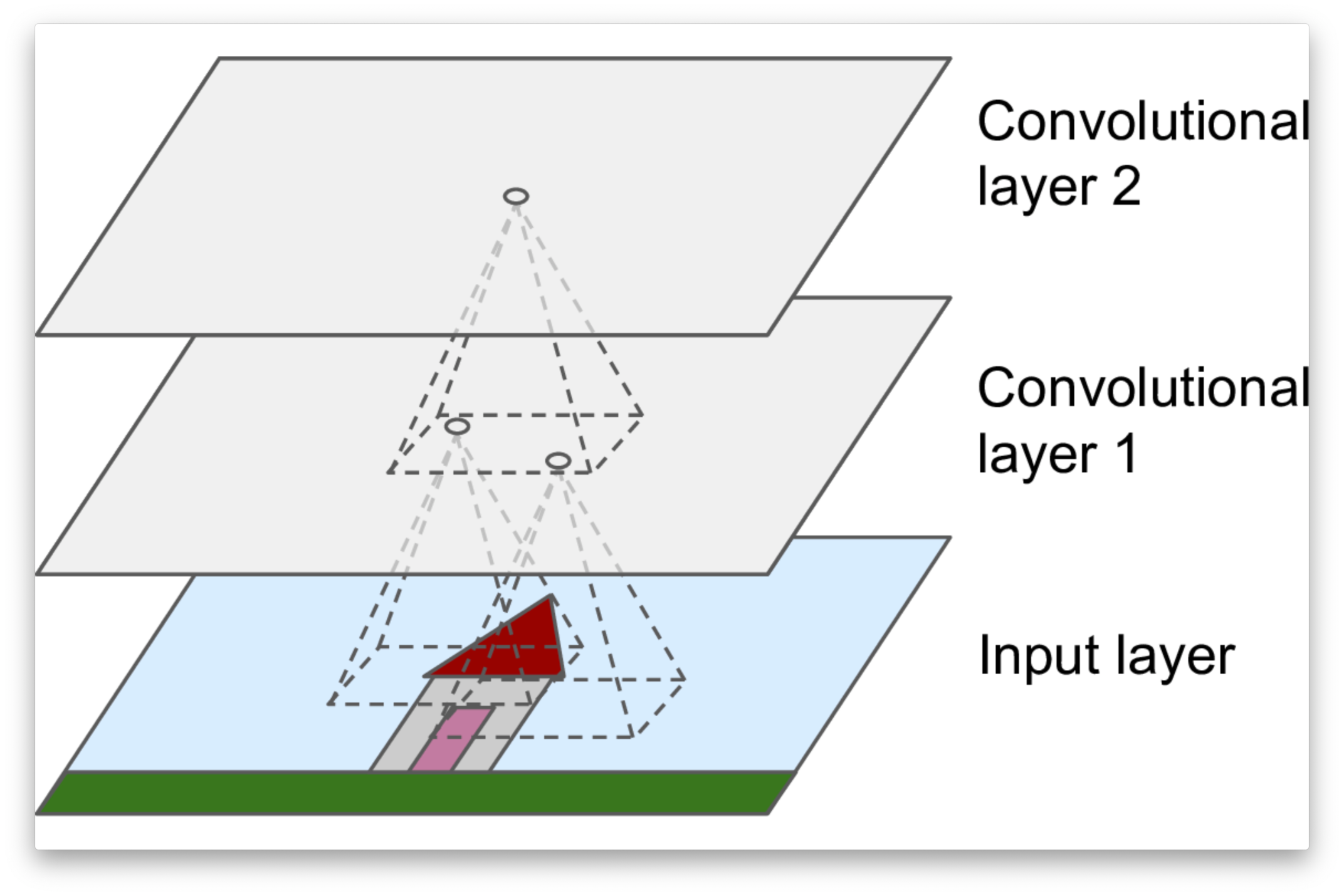
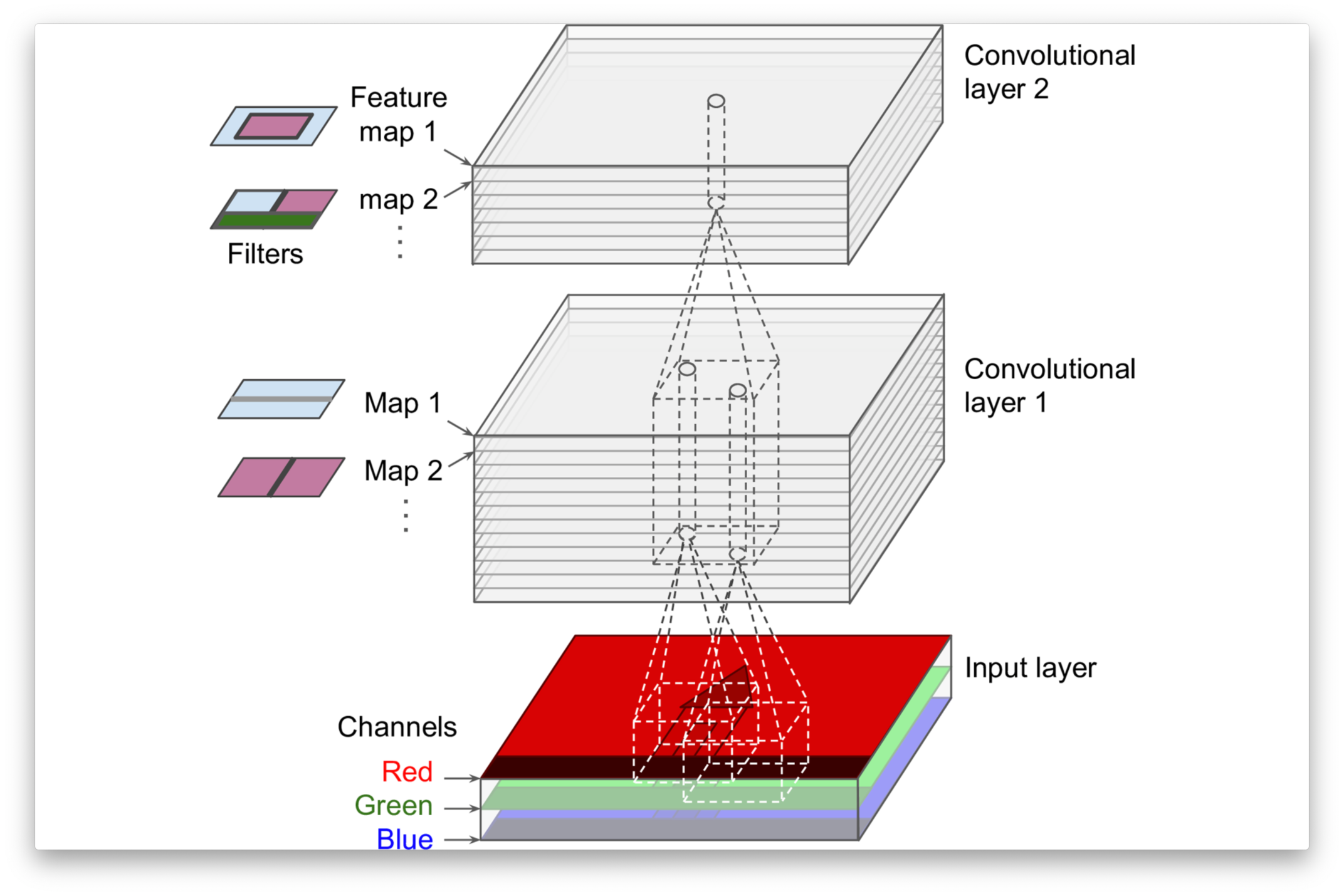
Géron, Aurélien. 2019. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 2nd éd. O’Reilly Media.
———. 2022. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 3ᵉ éd. O’Reilly Media, Inc.
Goodfellow, Ian, Yoshua Bengio, et Aaron Courville. 2016.
Deep Learning. Adaptive computation et machine learning. MIT Press.
https://dblp.org/rec/books/daglib/0040158.
Krizhevsky, Alex, Ilya Sutskever, et Geoffrey E Hinton. 2012.
« ImageNet Classification with Deep Convolutional Neural Networks ». In
Advances in Neural Information Processing Systems, édité par F. Pereira, C. J. Burges, L. Bottou, et K. Q. Weinberger. Vol. 25. Curran Associates, Inc.
https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf.
LeCun, Yann, Yoshua Bengio, et Geoffrey Hinton. 2015.
« Deep learning ».
Nature 521 (7553): 436‑44.
https://doi.org/10.1038/nature14539.
Lecun, Y., L. Bottou, Y. Bengio, et P. Haffner. 1998.
« Gradient-based learning applied to document recognition ».
Proceedings of the IEEE 86 (11): 2278‑2324.
https://doi.org/10.1109/5.726791.
Prince, Simon J. D. 2023.
Understanding Deep Learning. The MIT Press.
http://udlbook.com.
Russell, Stuart, et Peter Norvig. 2020.
Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson.
http://aima.cs.berkeley.edu/.
Simonyan, Karen, et Andrew Zisserman. 2015. « Very Deep Convolutional Networks for Large-Scale Image Recognition ». In International Conference on Learning Representations.