Décrire le rôle des algorithmes de recherche en IA, essentiel pour la planification, le raisonnement, et des applications telles qu’AlphaGo.
Rappeler les concepts clés de la recherche : espace d’états, état initial/final, actions, modèles de transition, fonctions de coût.
Identifier les différences entre les algorithmes de recherche non-informés (BFS et DFS).
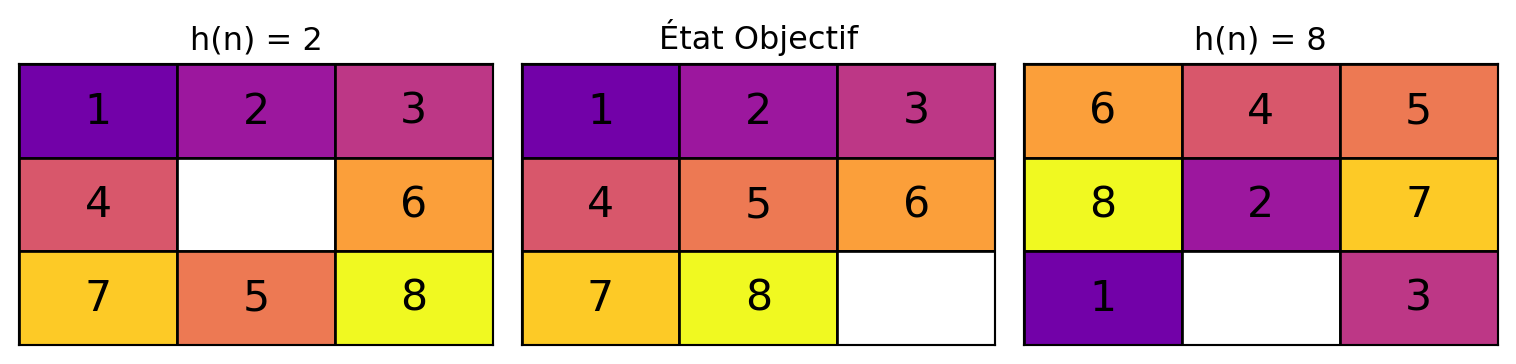
Implémenter BFS et DFS, les comparer en utilisant le problème du puzzle à 8 tuiles.
Analyser la performance et l’optimalité de divers algorithmes de recherche.
Justification
Pourquoi étudier ces algorithmes?
Justification
Nous avons perfectionné notre expertise en apprentissage automatique au point de bien comprendre les réseaux neuronaux et le deep learning, ce qui nous permet de développer des modèles simples avec Keras.
En revanche, les récentes avancées sur les recherche arborescente de Monte-Carlo (MCTS) ont joué un rôle central dans la recherche en intelligence artificielle. Nous passons donc de la concentration sur le deep learning vers l’exploration de la recherche.
Justification
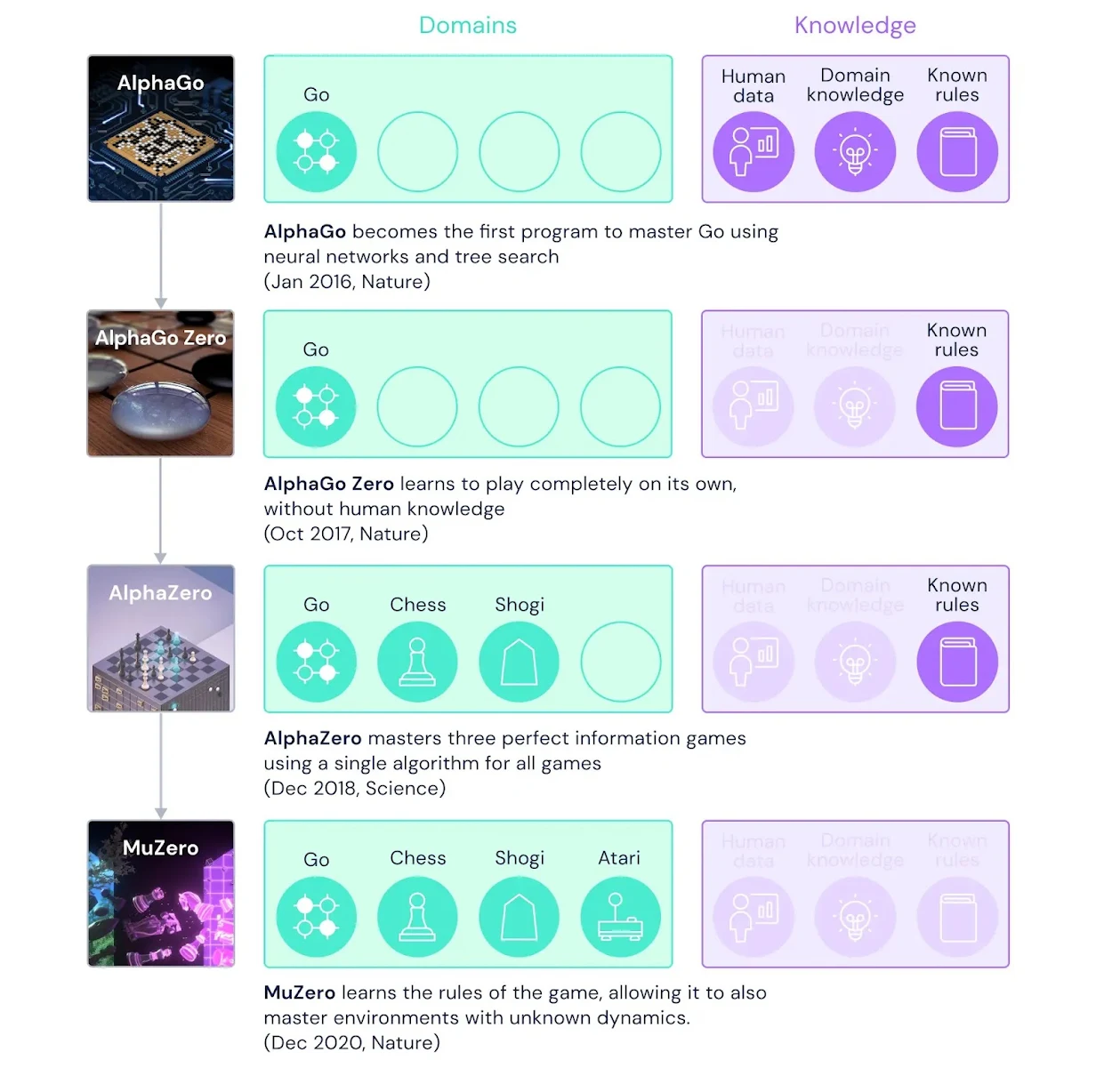
L’intégration du deep learning et de MCTS sous-tend des applications modernes comme AlphaGo, AlphaZero, et MuZero.
Les algorithmes de recherche sont donc cruciaux pour la planification et le raisonnement et leur importance devrait croître avec les avancées technologiques.
Recherche (un historique biaisé)
1968 – A* : Recherche heuristique pour la planification en IA.
1970s-1980s – Algorithmes à population (ex : algorithmes génétiques) : Optimisation stochastique pour grands espaces.
1980s – CSP (Problèmes de satisfaction de contraintes) : Recherche dans des espaces structurés avec contraintes explicites.
2013 – DQN : Apprentissage par renforcement (Q-learning) sur données brutes.
2015 – AlphaGo : Recherche d’arbres de jeu avec MCTS combiné au deep learning.
2017 – AlphaZero : MCTS pour auto-apprentissage dans plusieurs domaines.
2019 – MuZero : Recherche dans environnements inconnus sans modèles préexistants.
2021 – FunSearch : Généralisation possible des techniques de recherche.
Recherche
AlphaGo - Le Film
AlphaGo2MuZero
Recherche
Applications
Cheminement et navigation : Utilisé en robotique et dans les jeux vidéo pour trouver un chemin d’un point de départ à une destination.
Résolution de puzzles : Résolution de problèmes comme le puzzle à 8 tuiles, labyrinthes, ou Sudoku.
Analyse de réseaux : Analyse de connectivité et des chemins les plus courts dans les réseaux sociaux ou les cartes de transport.
Jeux : Évaluation des coups dans les jeux comme les échecs ou le Go.
Applications
Planification et ordonnancement : Planification des tâches dans la gestion de projet ou l’ordonnancement de vols.
Allocation de ressources : Allocation de ressources dans un réseau ou organisation.
Problèmes de configuration : Assemblage de composants pour satisfaire des exigences, comme la configuration d’un système informatique.
Applications
Décisions sous incertitude : Décisions en jeux de stratégie en temps réel ou simulations.
Narration : Les modèles de langage peuvent générer des récits lorsqu’ils sont guidés par un plan valide provenant d’un planificateur automatisé. (Simon et Muise 2024)
Plan
Recherche déterministe et heuristique : BFS, DFS, A* pour la recherche de chemins et l’optimisation en IA classique.
Algorithmes basés sur la population : Focus sur les problèmes structurés et la recherche stochastique.
Algorithmes de jeux adversariaux : Minimax, élagage alpha-bêta, MCTS pour la prise de décision dans des environnements compétitifs.
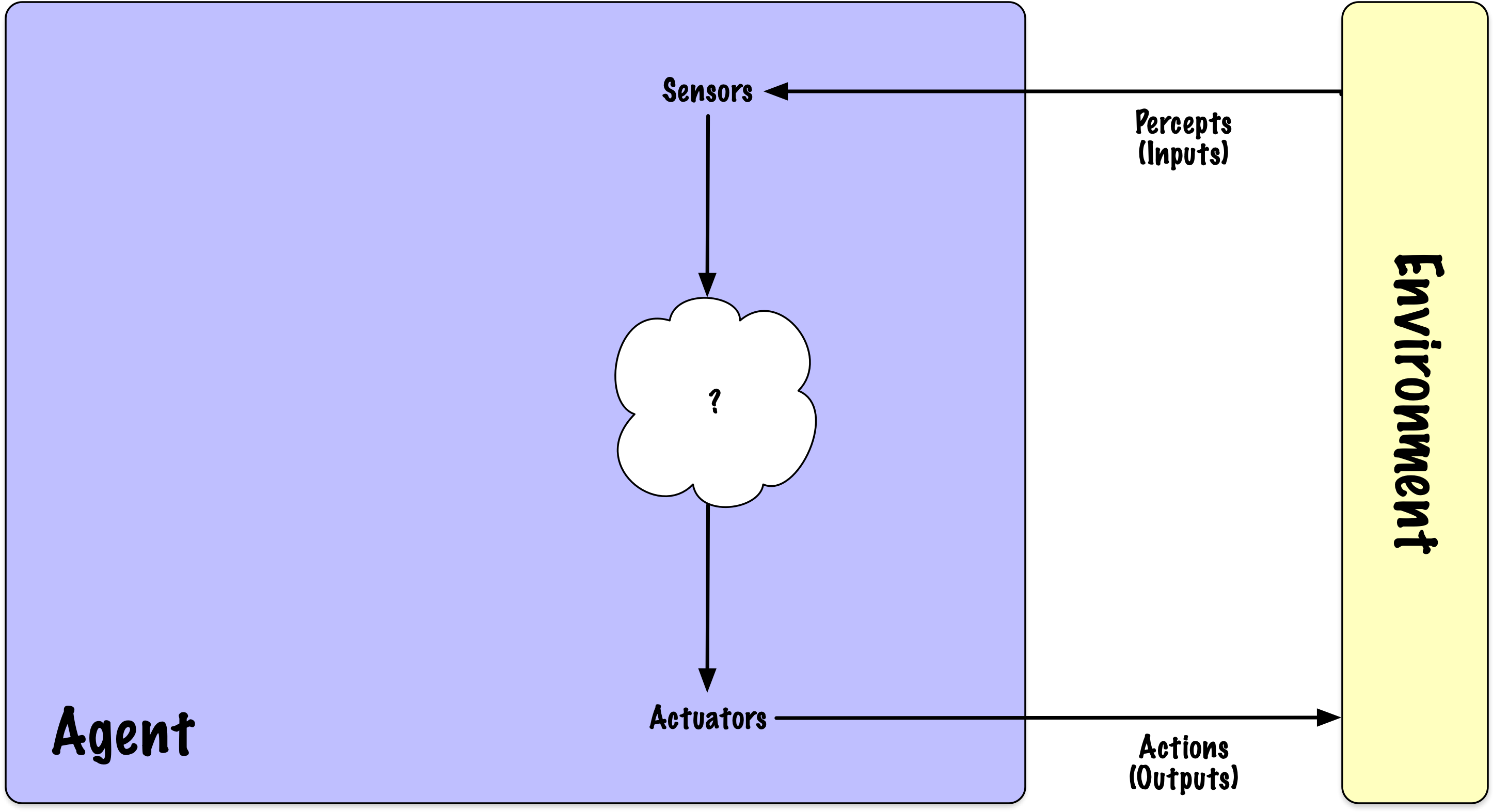
Lorsqu’il n’est pas immédiatement évident de savoir quelle action correcte entreprendre, un agent peut avoir besoin de planifier à l’avance : considérer une séquence d’actions qui forment un chemin vers un état objectif. Un tel agent est appelé un agent de résolution de problèmes, et le processus computationnel qu’il entreprend est appelé recherche.
Terminologie
Caractéristiques de l’environnement
Observabilité : Partiellement observable ou totalement observable
Composition de l’agent : Agent unique ou multiple
Prédictibilité : Déterministe ou non déterministe
Dépendance d’état : Sans état ou avec état
Dynamique temporelle : Statique ou dynamique
Représentation de l’état : Discrète ou continue
Processus de résolution de problèmes
Recherche : Le processus implique de simuler des séquences d’actions jusqu’à ce que l’agent atteigne son objectif. Une séquence réussie est appelée une solution.
Problème de recherche
Un ensemble d’états, appelé espace d’états.
Un état initial où l’agent commence.
Un ou plusieurs états objectifs qui définissent des résultats réussis.
Un ensemble d’actions disponibles dans un état donné \(s\).
Un modèle de transition qui détermine l’état suivant en fonction de l’état actuel et de l’action sélectionnée.
Une fonction de coût d’action qui spécifie le coût de l’exécution de l’action \(a\) dans l’état \(s\) pour atteindre l’état \(s'\).
Définitions
Un chemin est défini comme une séquence d’actions.
Une solution est un chemin qui relie l’état initial à l’état objectif.
Une solution optimale est le chemin avec le coût le plus bas parmi toutes les solutions possibles.
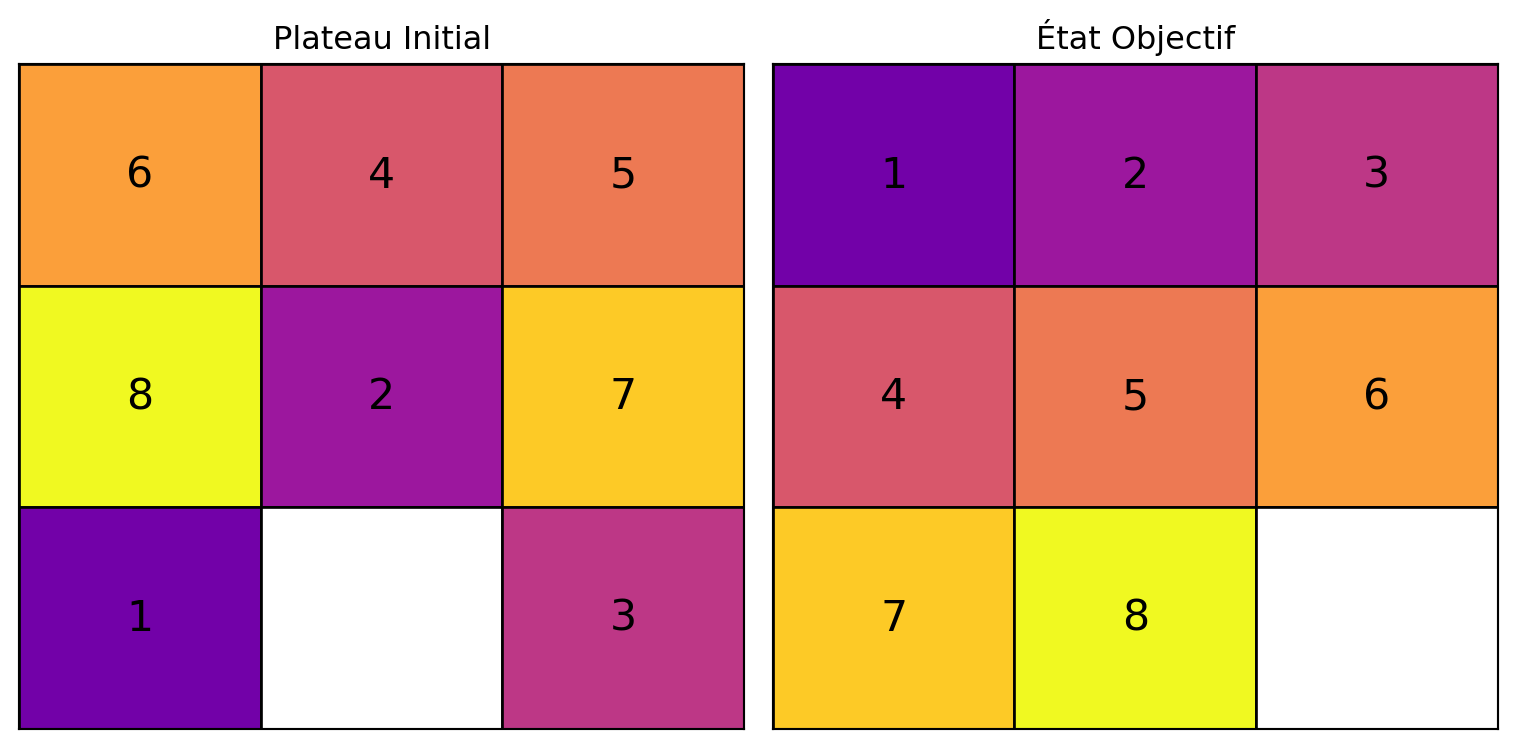
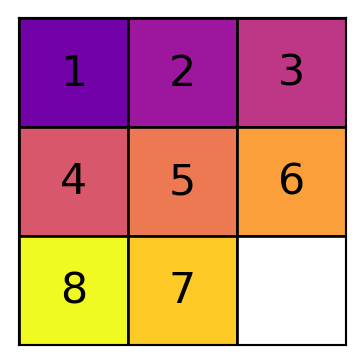
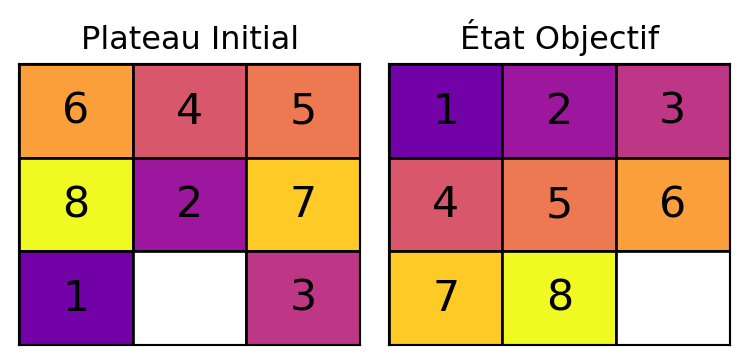
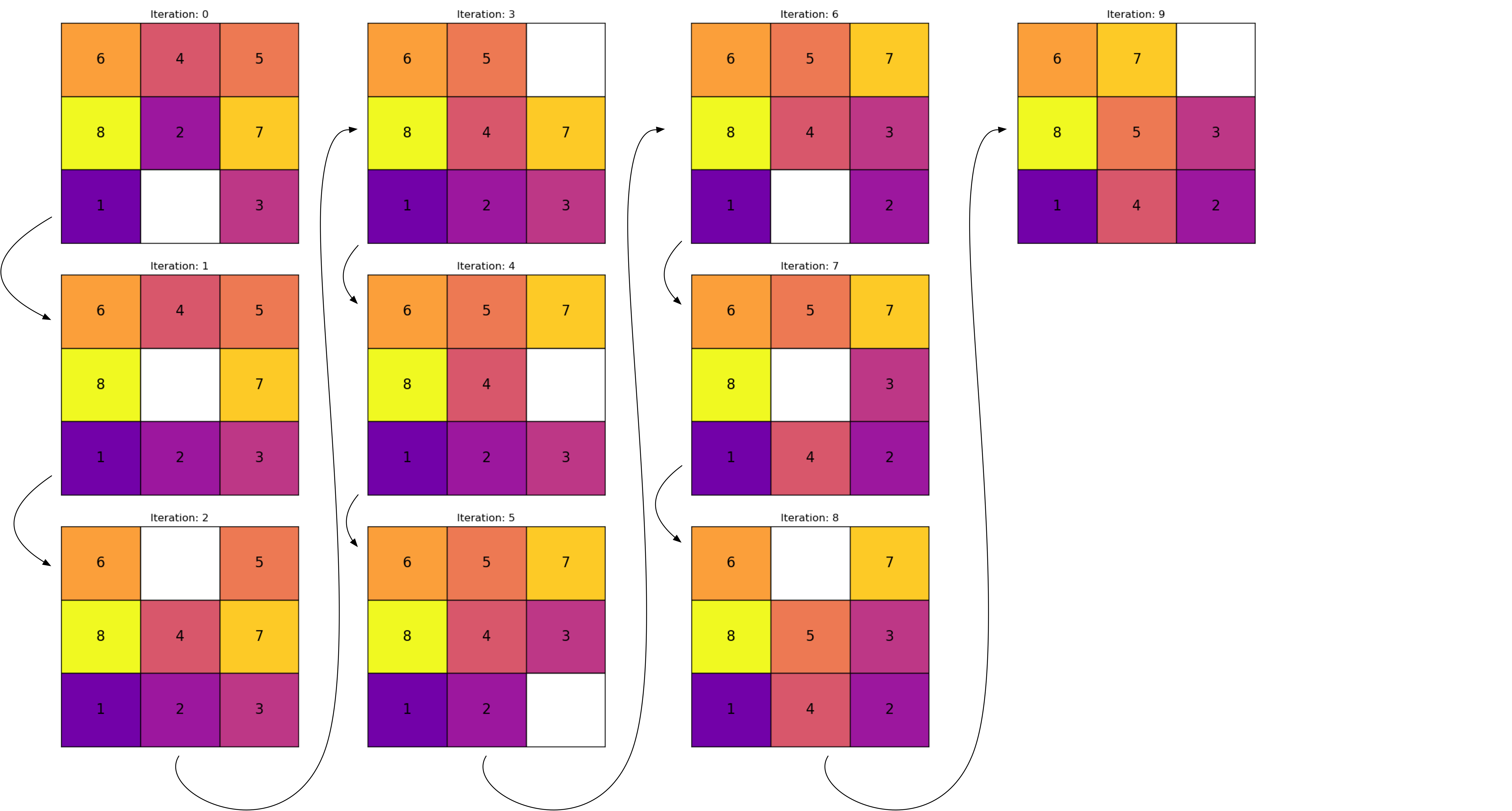
Exemple : 8-Puzzle
Code
import randomimport matplotlib.pyplot as pltimport numpy as nprandom.seed(58)def is_solvable(tiles):# Compter les inversions dans la liste à plat des tuiles (en excluant l'espace vide) inversions =0for i inrange(len(tiles)):for j inrange(i +1, len(tiles)):if tiles[i] !=0and tiles[j] !=0and tiles[i] > tiles[j]: inversions +=1return inversions %2==0def generate_solvable_board():# Générer une configuration de plateau aléatoire qui est garantie d'être résoluble tiles =list(range(9)) random.shuffle(tiles)whilenot is_solvable(tiles): random.shuffle(tiles)return tilesdef plot_board(board, title, num_pos, position): ax = plt.subplot(1, num_pos, position) ax.set_title(title) ax.set_xticks([]) ax.set_yticks([]) board = np.array(board).reshape(3, 3).tolist() # Reconfigurer en une grille 3x3# Utiliser une carte de couleurs pour afficher les numéros cmap = plt.cm.plasma norm = plt.Normalize(vmin=-1, vmax=8)for i inrange(3):for j inrange(3): tile_value = board[i][j] color = cmap(norm(tile_value)) ax.add_patch(plt.Rectangle((j, 2- i), 1, 1, facecolor=color, edgecolor='black'))if tile_value ==0: ax.add_patch(plt.Rectangle((j, 2- i), 1, 1, facecolor='white', edgecolor='black'))else: ax.text(j +0.5, 2- i +0.5, str(tile_value), fontsize=16, ha='center', va='center', color='black') ax.set_xlim(0, 3) ax.set_ylim(0, 3)
Un tableau est résolvable s’il a la même parité d’inversion que l’état final.
Une inversion est une paire de tuiles (à l’exclusion du vide) qui sont dans le mauvais ordre l’une par rapport à l’autre, lorsqu’on lit le tableau comme une liste unidimensionnelle (de gauche à droite, de haut en bas).
Lorsque le but est la séquence ordonnée de 1 à 8, il n’y a pas d’inversion, et donc la parité est paire.
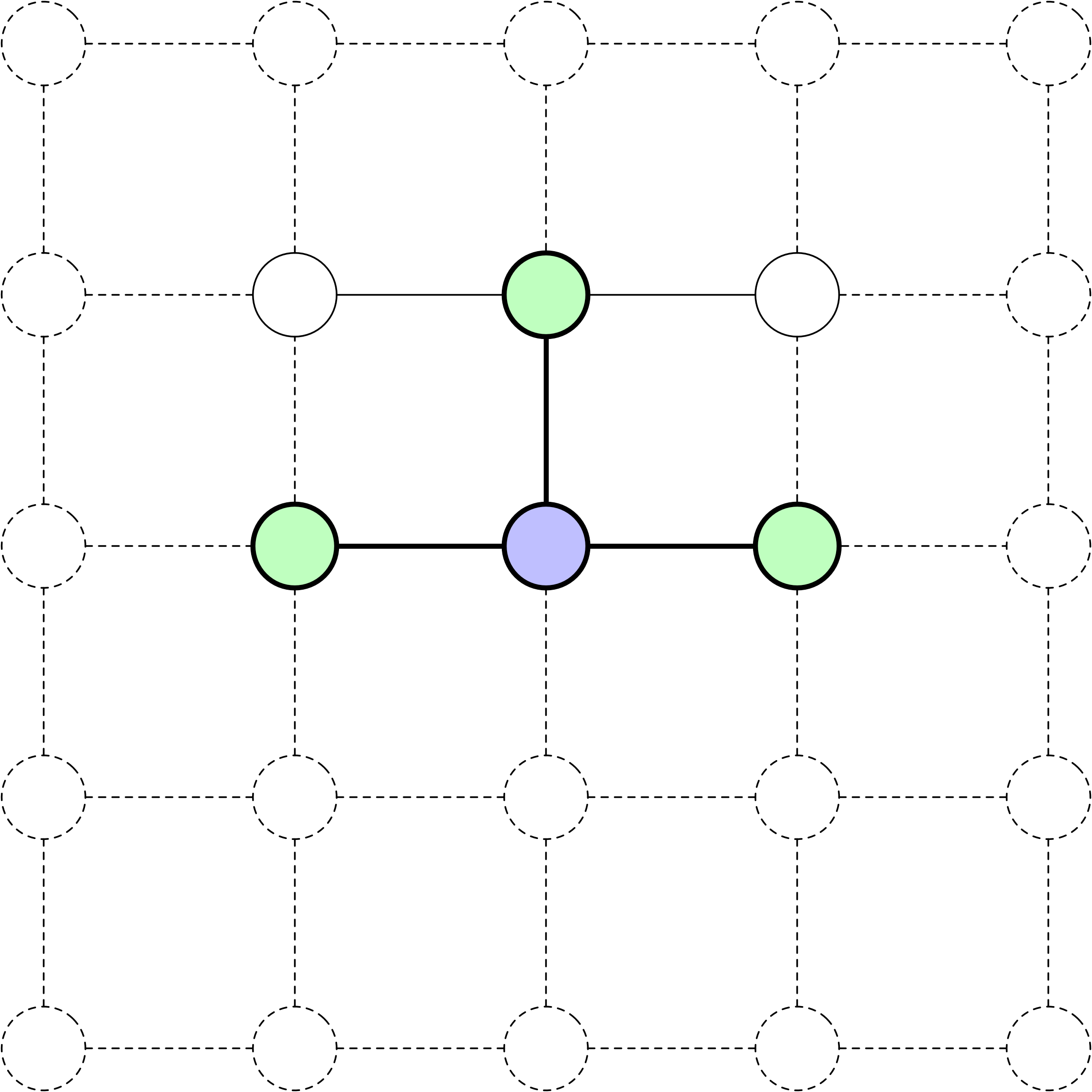
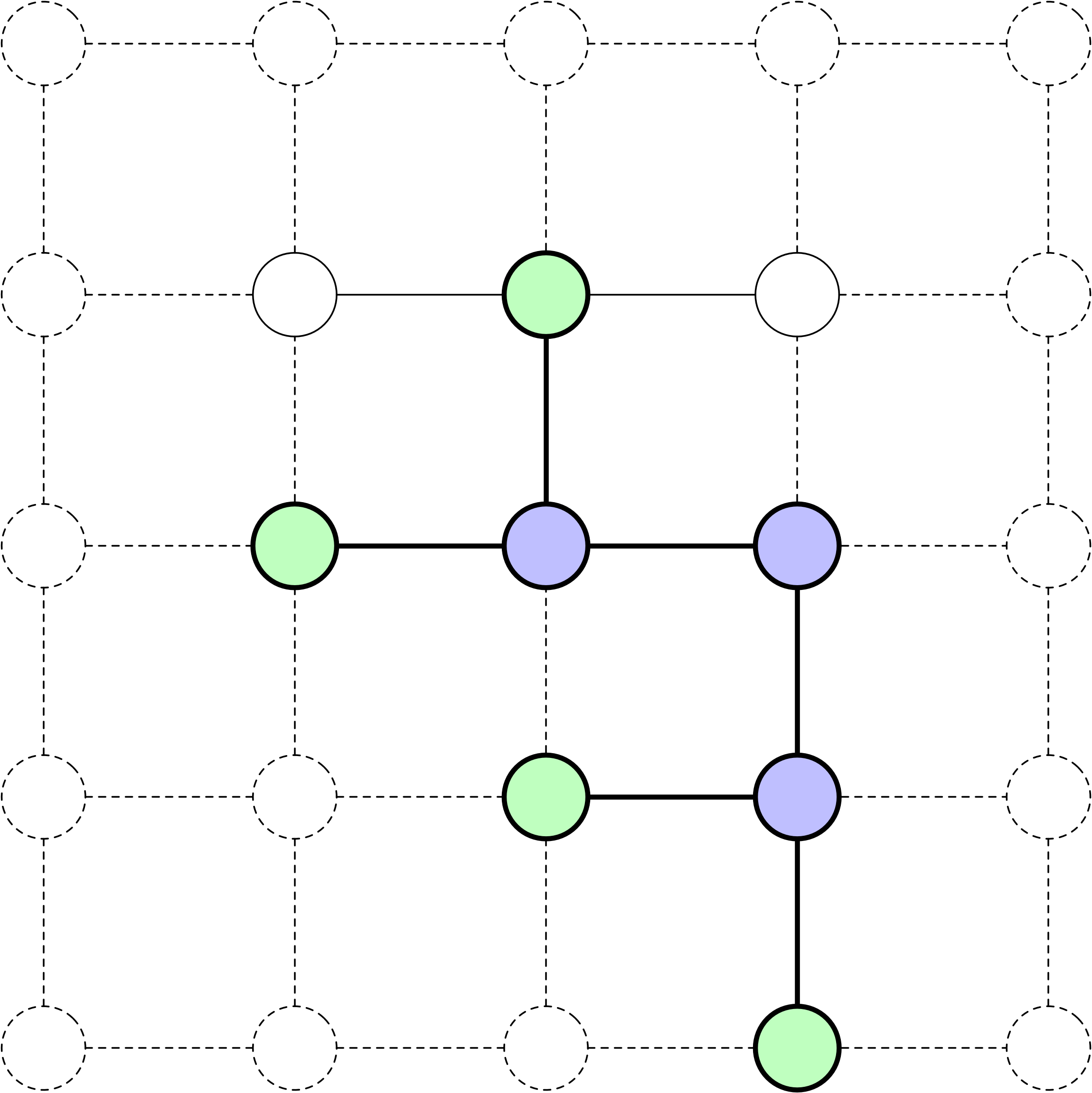
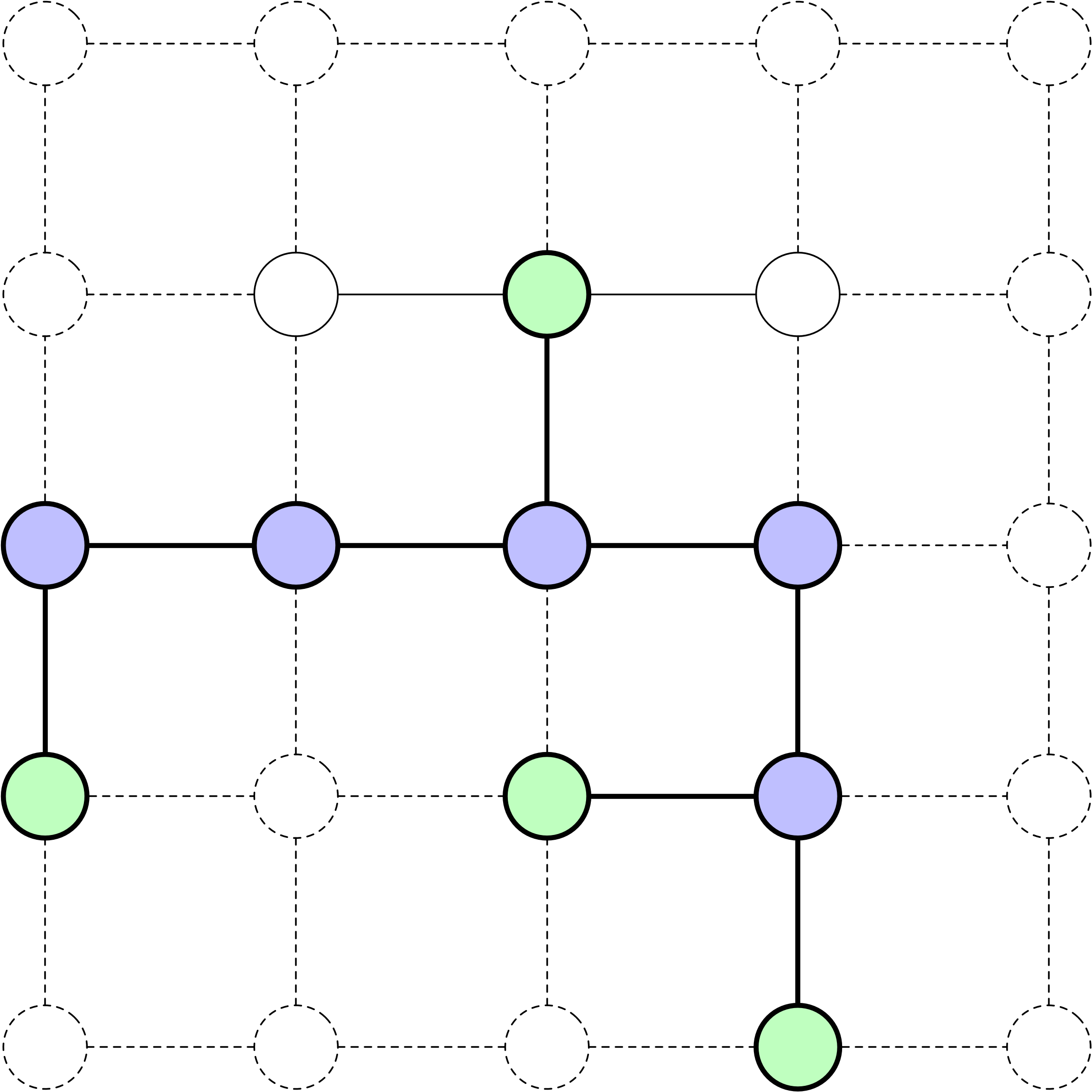
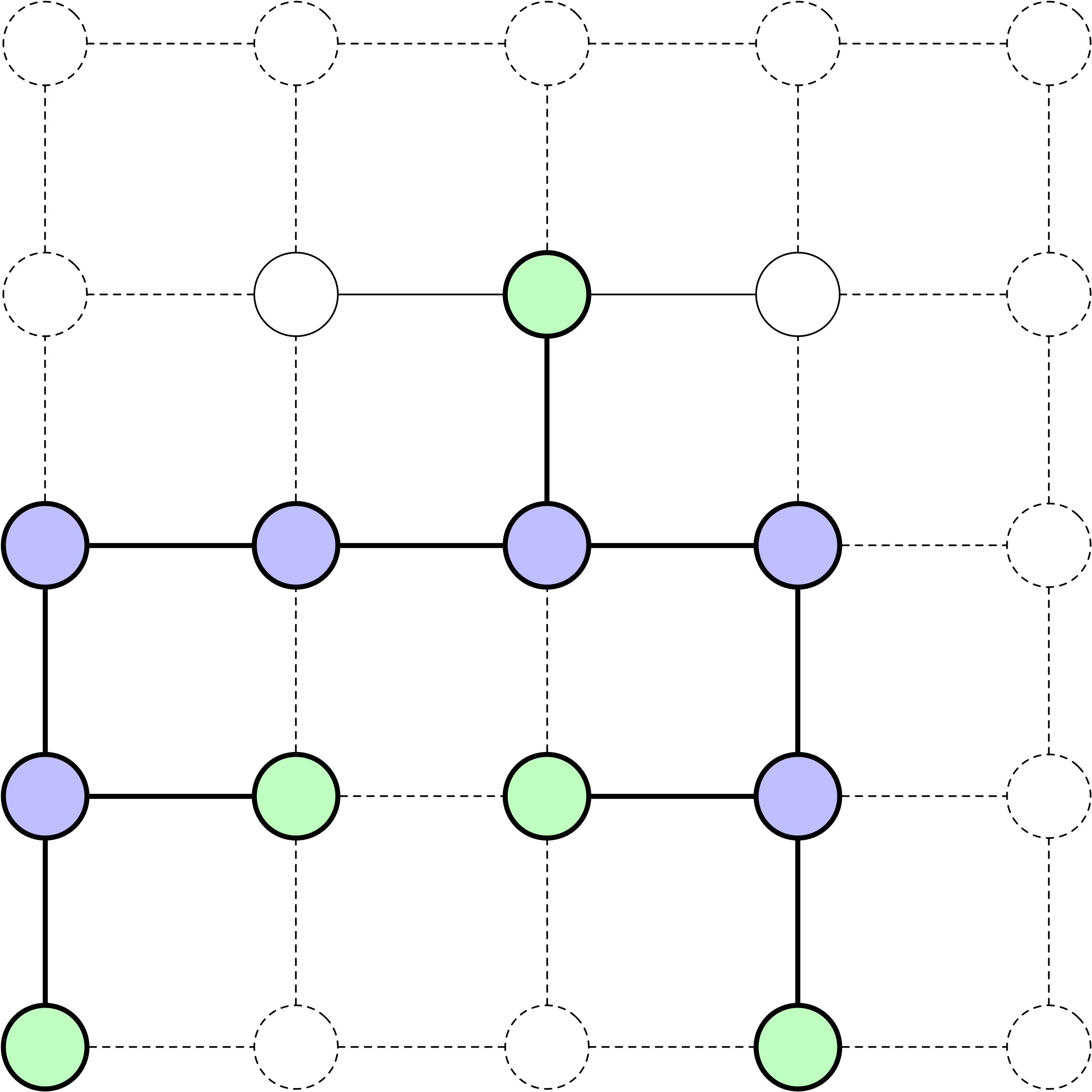
La racine de l’arbre de recherche représente l’état initial du problème.
Développer un nœud implique d’évaluer toutes les actions possibles disponibles à partir de cet état.
Le résultat d’une action est le nouvel état atteint après avoir appliqué cette action à l’état actuel.
À l’instar d’autres structures d’arbres, chaque nœud a un parent et peut avoir des enfants.
Frontière
Frontière
Frontière
Recherche non informée
Définition
Une recherche non informée (ou recherche aveugle) est une stratégie de recherche qui explore l’espace de recherche en utilisant uniquement les informations disponibles dans la définition du problème, sans aucune connaissance spécifique au domaine, en évaluant les nœuds uniquement sur la base de leurs propriétés intrinsèques plutôt que sur des coûts estimés ou des heuristiques.
def is_goal(state, goal_state):"""Détermine si un état donné correspond à l'état objectif."""return state == goal_state
expand
def expand(state):"""Génère les états successeurs en déplaçant la tuile vide dans toutes les directions possibles.""" size =int(len(state) **0.5) # Déterminer la taille du puzzle (3 pour le 8-Puzzle, 4 pour le 15-Puzzle) idx = state.index(0) # Trouver l'index de la tuile vide représentée par 0 x, y = idx % size, idx // size # Convertir l'index en coordonnées (x, y) neighbors = []# Définir les mouvements possibles : Gauche, Droite, Haut, Bas moves = [(-1, 0), (1, 0), (0, -1), (0, 1)]for dx, dy in moves: nx, ny = x + dx, y + dy# Vérifier si la nouvelle position est dans les limites du puzzleif0<= nx < size and0<= ny < size: n_idx = ny * size + nx new_state = state.copy()# Échanger la tuile vide avec la tuile adjacente new_state[idx], new_state[n_idx] = new_state[n_idx], new_state[idx] neighbors.append(new_state)return neighbors
def is_empty(frontier):"""Vérifie si la frontière est vide."""returnlen(frontier) ==0
print_solution
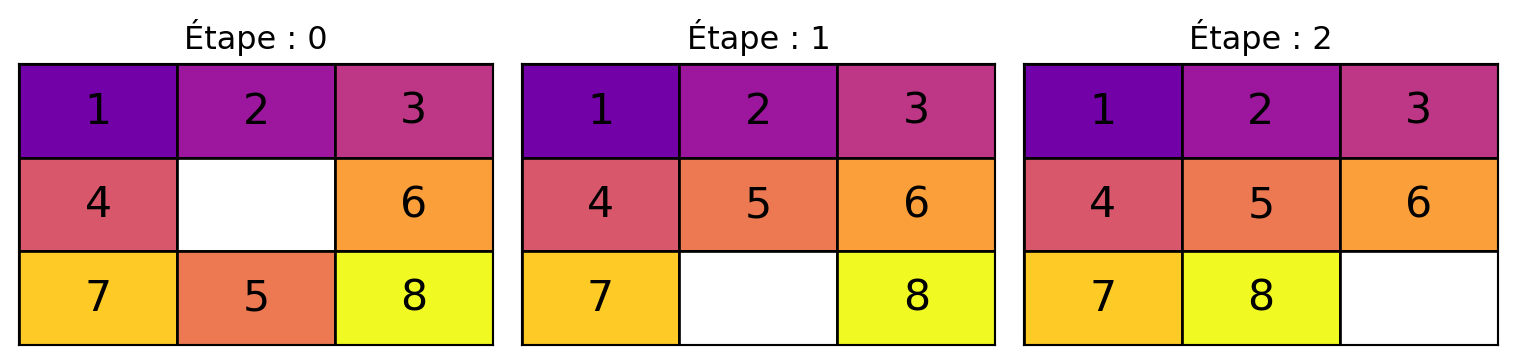
def print_solution(solution):"""Affiche la séquence d'étapes de l'état initial à l'état objectif.""" size =int(len(solution[0]) **0.5)for step, state inenumerate(solution):print(f"Étape {step} :")for i inrange(size): row = state[i*size:(i+1)*size]print(' '.join(str(n) if n !=0else' 'for n in row))print()
Cycles
Un chemin qui revisite les mêmes états forme un cycle.
Permettre des cycles rendrait l’arbre de recherche résultant infini.
Pour éviter cela, nous surveillons les états qui ont été atteints, bien que cela entraîne un coût en mémoire.
Recherche en largeur
Recherche en largeur
from collections import deque
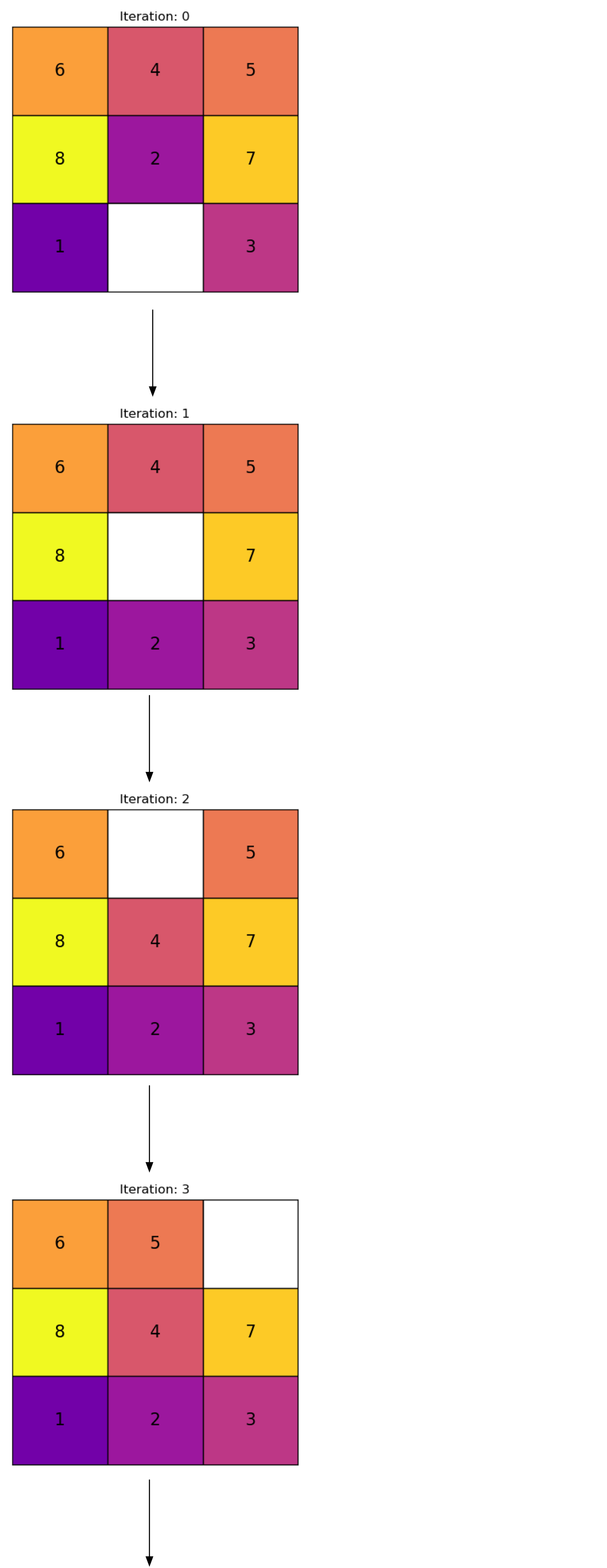
La recherche en largeur (BFS) utilise une file d’attente pour gérer les nœuds de la frontière, également connus sous le nom de liste ouverte.
Recherche en largeur
def bfs(initial_state, goal_state): frontier = deque() # Initialiser la file d'attente pour BFS frontier.append((initial_state, [])) # Chaque élément est un tuple : (état, chemin) explored =set() explored.add(tuple(initial_state)) iterations =0# utilisé simplement pour comparer les algorithmeswhilenot is_empty(frontier): current_state, path = frontier.popleft()if is_goal(current_state, goal_state):print(f"Nombre d'itérations : {iterations}")return path + [current_state] # Retourner le chemin réussi iterations = iterations +1for neighbor in expand(current_state): neighbor_tuple =tuple(neighbor)if neighbor_tuple notin explored: explored.add(neighbor_tuple) frontier.append((neighbor, path + [current_state]))returnNone# Aucune solution trouvée
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.
Schrittwieser, Julian, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, et al. 2020. « Mastering Atari, Go, chess and shogi by planning with a learned model ». Nature 588 (7839): 604‑9. https://doi.org/10.1038/s41586-020-03051-4.
Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, et al. 2016. « Mastering the game of Go with deep neural networks and tree search ». Nature 529 (7587): 484‑89. https://doi.org/10.1038/nature16961.
Simon, Nisha, et Christian Muise. 2024. « Want ToChooseYourOwnAdventure? ThenFirstMake a Plan. »Proceedings of the Canadian Conference on Artificial Intelligence.