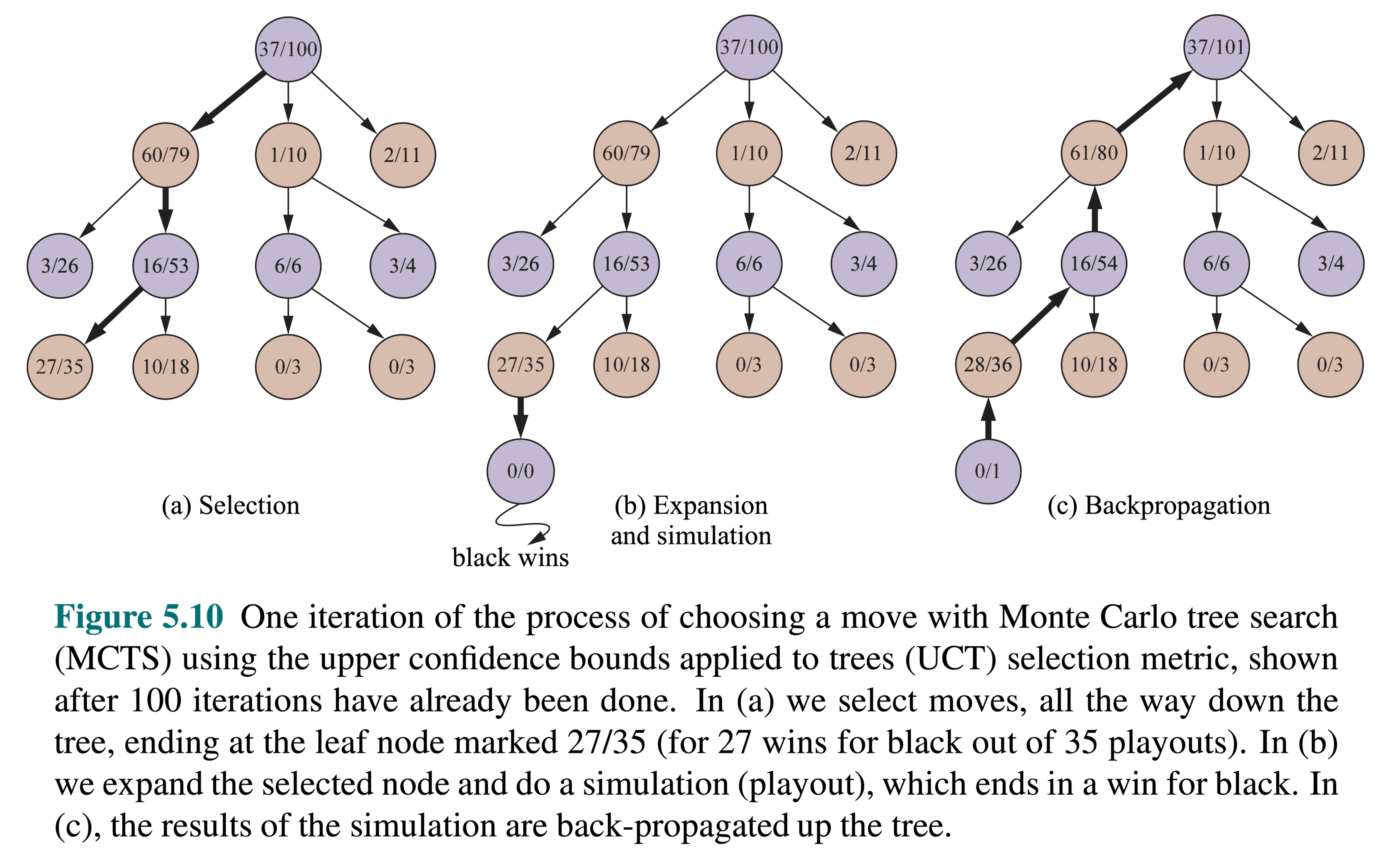
Expliquer le concept et les étapes clés de la recherche arborescente de Monte-Carlo (MCTS).
Comparer MCTS avec d’autres algorithmes de recherche tels que BFS, DFS, \(A^\star\), le recuit simulé et les algorithmes génétiques.
Analyser comment MCTS équilibre exploration et exploitation en utilisant la formule UCB1.
Implémenter MCTS dans des applications pratiques comme le Tic-Tac-Toe.
Introduction
Recherche arborescente de Monte Carlo
Dans la présentation d’introduction sur la recherche d’espace d’états, j’ai utilisé la recherche arborescente de Monte Carlo (MCTS), un élément clé d’AlphaGo, pour illustrer le rôle des algorithmes de recherche dans le raisonnement.
Aujourd’hui, nous concluons cette série en examinant les détails d’implémentation de cet algorithme.
Applications
Conception de médicaments de novo
Routage de circuits électroniques
Surveillance de la charge dans les réseaux intelligents
Tâches de maintien de voie et de dépassement
Planification de mouvement dans la conduite autonome
Résolution même du problème du voyageur de commerce
Applications (suite)
Voir aussi Besta et al. (2025) sur le rôle de MTCS dans les modèles de langage de raisonnement (RLMs).
Notes historiques
2008 : l’algorithme est introduit dans le contexte du jeu d’IA(Chaslot et al. 2008)
2016 : l’algorithme est combiné avec des réseaux neuronaux profonds pour créer AlphaGo(Silver et al. 2016)
Définition
Un algorithme de Monte Carlo est une méthode computationnelle qui utilise l’échantillonnage aléatoire pour obtenir des résultats numériques, souvent utilisée pour l’optimisation, l’intégration numérique et l’estimation de distribution de probabilité.
Il se caractérise par sa capacité à traiter des problèmes complexes avec des solutions probabilistes, échangeant exactitude contre efficacité et évolutivité.
Algorithme
Pour un nombre spécifié d’itérations (simulations) :
Sélection (descente guidée de l’arbre)
Expansion de noeud
Déroulement (simulation)
Rétropropagation
Algorithme
Algorithme à tout moment
MCTS est un exemple classique d’un algorithme à tout moment (any-time algorithm) :
Il peut être interrompu à tout moment.
Plus de temps ⇒ plus de simulations ⇒ meilleures estimations d’action.
Il renvoie le meilleur coup actuel compte tenu du nombre d’itérations effectuées.
C’est exactement ainsi qu’il est utilisé dans le Go, les échecs, Atari, MuZero, etc. : s’exécuter jusqu’à ce que le budget de temps expire, puis agir.
Discussion
Comme d’autres algorithmes déjà abordés, tels que BFS, DFS, et \(A^\star\), la recherche arborescente de Monte Carlo (MCTS) maintient une frontière de nœuds non développés.
Discussion
Similaire à \(A^\star\), la recherche arborescente de Monte Carlo (MCTS) utilise une heuristique, appelée politique, pour déterminer le prochain nœud à développer.
Cependant, dans \(A^\star\), l’heuristique est typiquement une fonction statique estimant le coût vers un objectif, tandis que dans MCTS, la “politique” implique une évaluation dynamique.
Discussion
Semblable à l’optimisation par recuit simulé (simulated annealing) et aux algorithmes génétiques (genetic algorithms), la recherche arborescente de Monte Carlo (MCTS) intègre un mécanisme pour équilibrerexploration et exploitation.
Discussion
La MCTS exploite tous les nœuds visités dans son processus de prise de décision, contrairement à \(A^\star\), qui se concentre principalement sur la frontière actuelle.
De plus, la MCTS met à jour itérativement la valeur de ses nœuds en fonction des simulations, alors que \(A^\star\) utilise généralement une heuristique statique.
Discussion
Contrairement aux algorithmes précédents avec des arbres de recherche implicites, la MCTS construit une structure d’arbreexplicite pendant l’exécution.
Étape par étape
Étape par étape
Étape par étape
Étape par étape (1.1)
Étape par étape (1.1)
Étape par étape (1.1)
Étape par étape (1.2)
Étape par étape (1.3)
Étape par étape (1.4)
Étape par étape (1.Fin)
Étape par étape (2.1)
Étape par étape (2.2)
Étape par étape (2.3)
Étape par étape (2.4)
Étape par étape (2.Fin)
Étape par étape (3.1)
Étape par étape (3.1)
Étape par étape (3.2)
Étape par étape (3.2)
Étape par étape (3.3)
Étape par étape (3.4)
Étape par étape (3.Fin)
Étape par étape (4.1)
Étape par étape (4.1)
Étape par étape (4.2)
Étape par étape (4.2)
Étape par étape (4.3)
Étape par étape (4.4)
Étape par étape (4.Fin)
Déroulement
Russell et Norvig
Résumé : construction de l’arbre
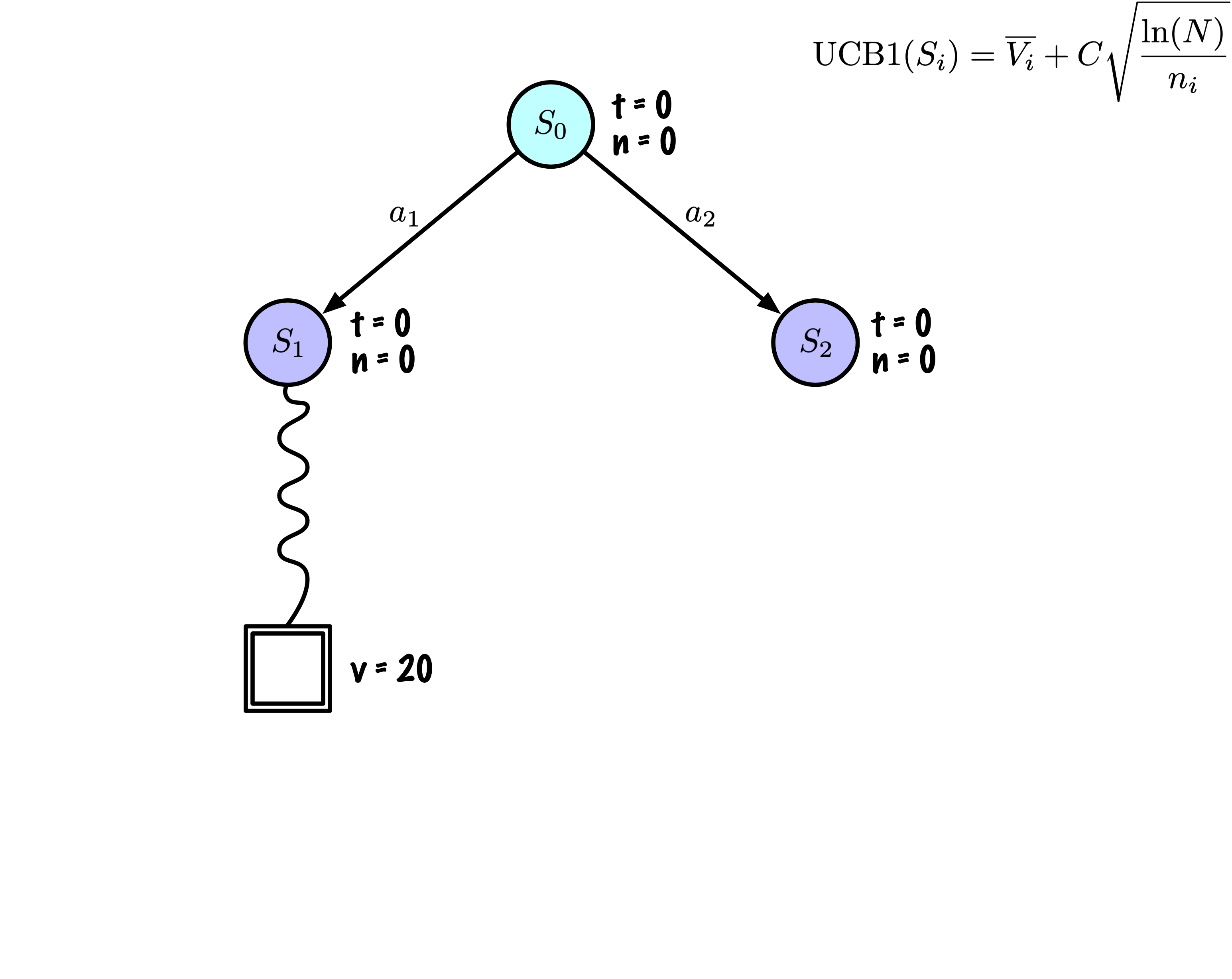
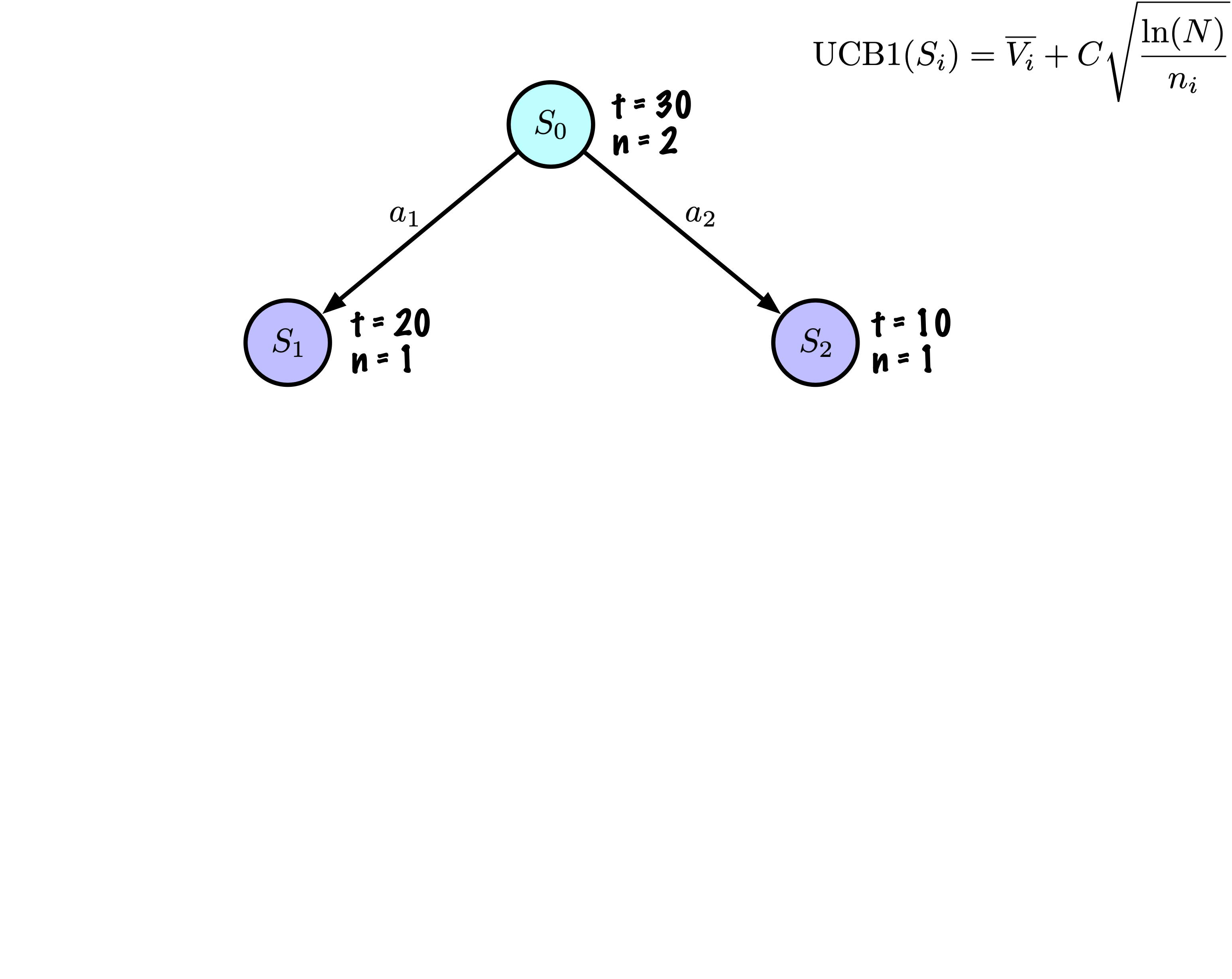
Initialement, l’arbre a un nœud, c’est \(S_0\).
Nous ajoutons ses descendants et nous sommes prêts à commencer.
La recherche arborescente de Monte Carlo construit lentement son arbre de recherche.
Résumé : 4 étapes
À chaque itération, les étapes suivantes se produisent :
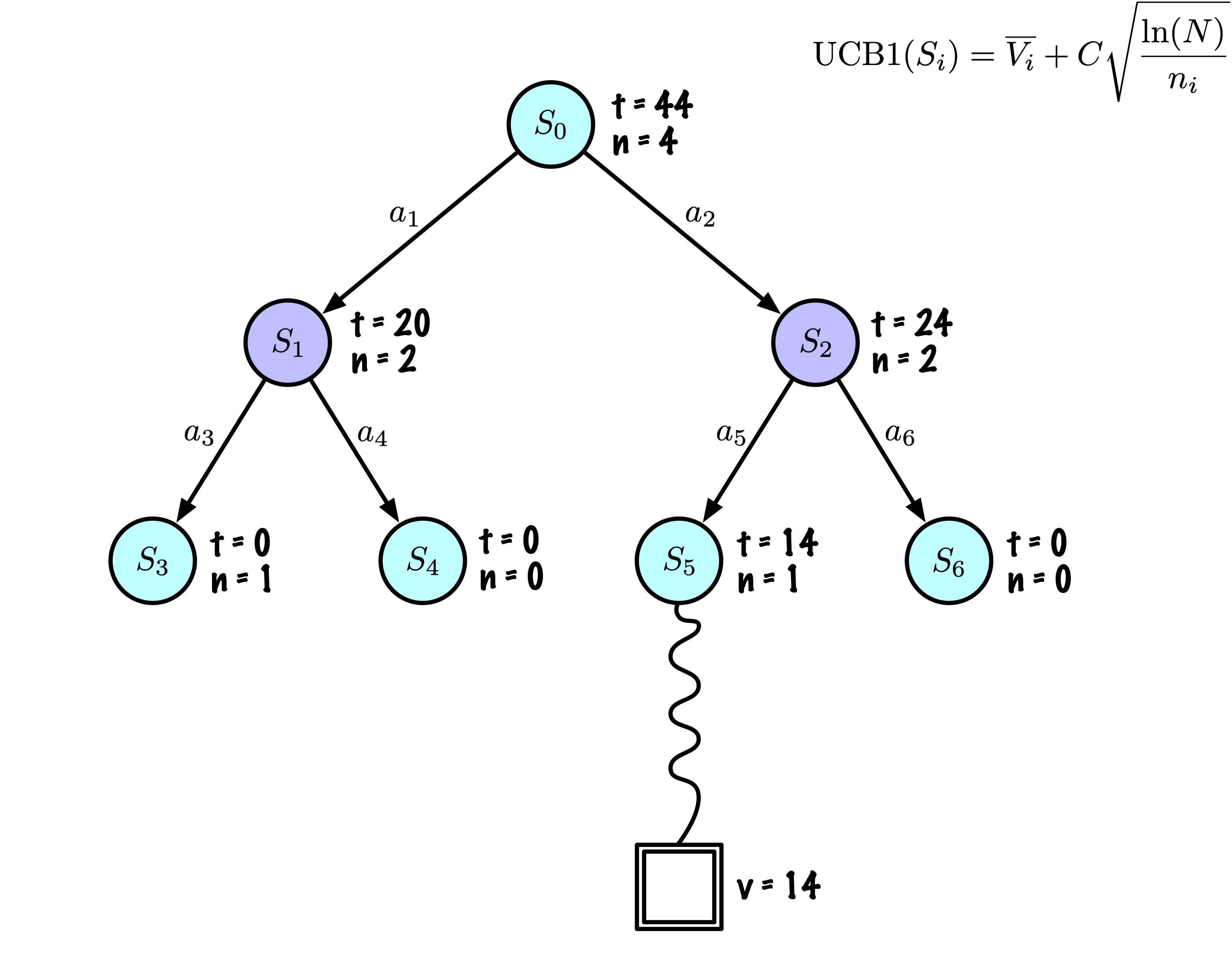
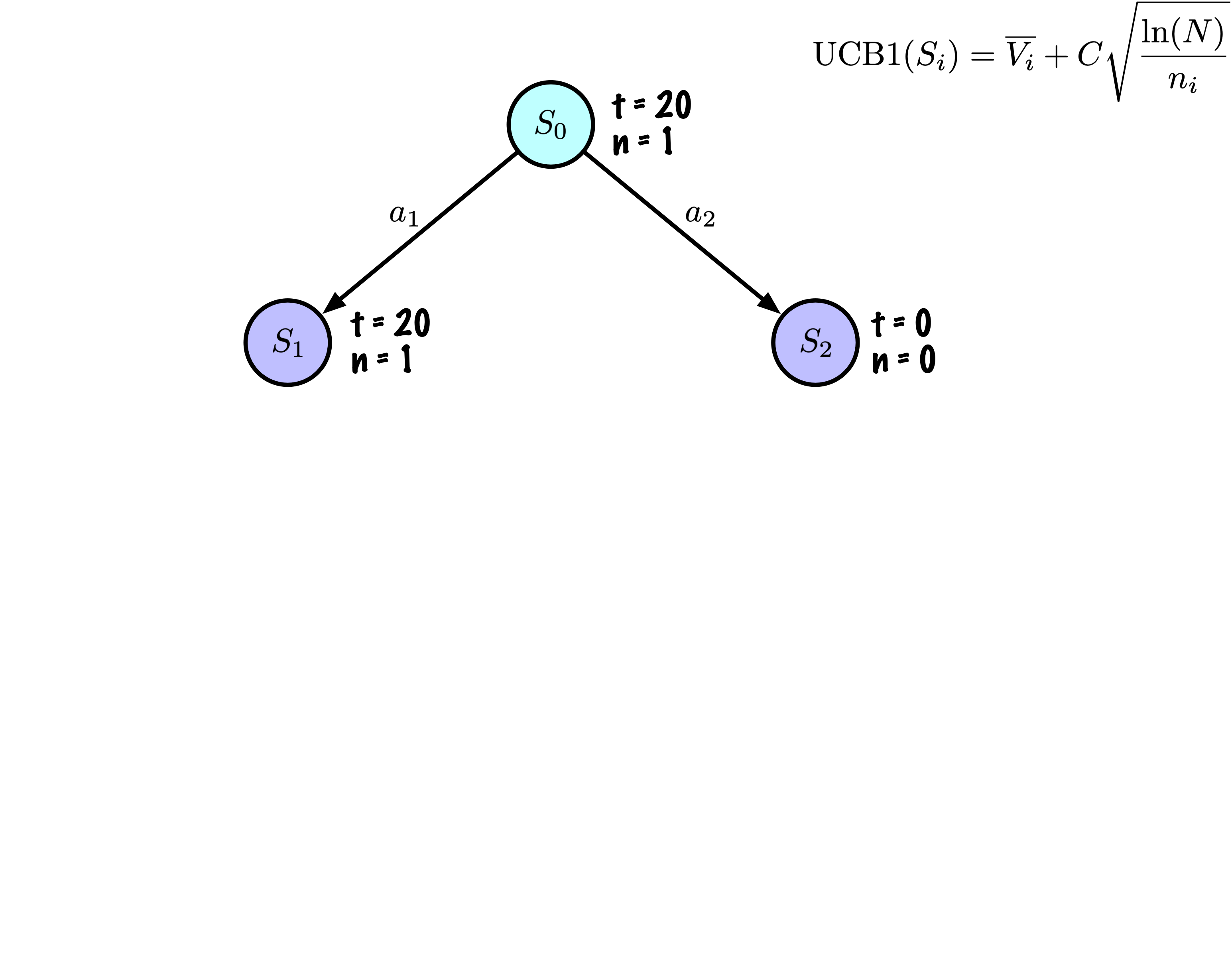
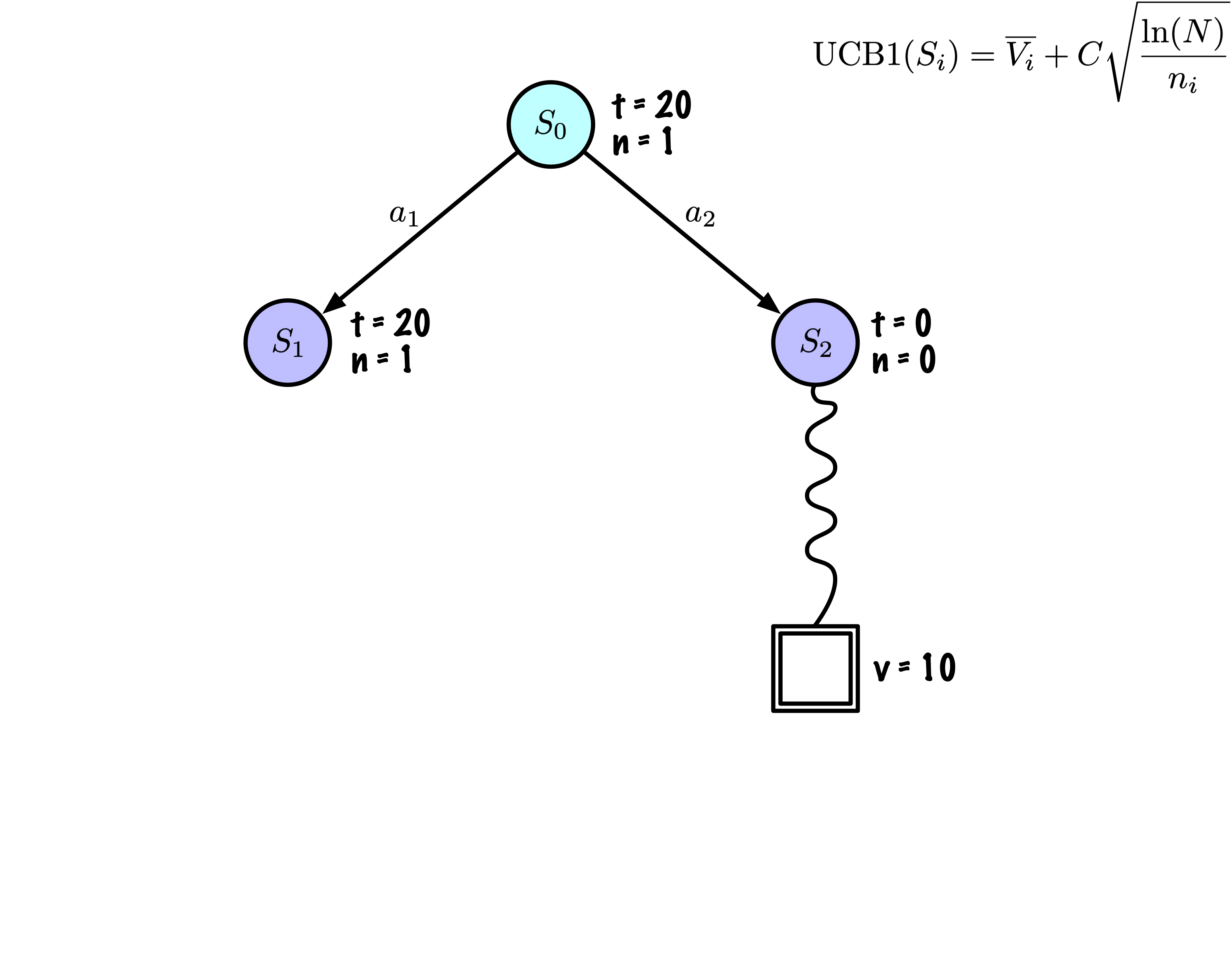
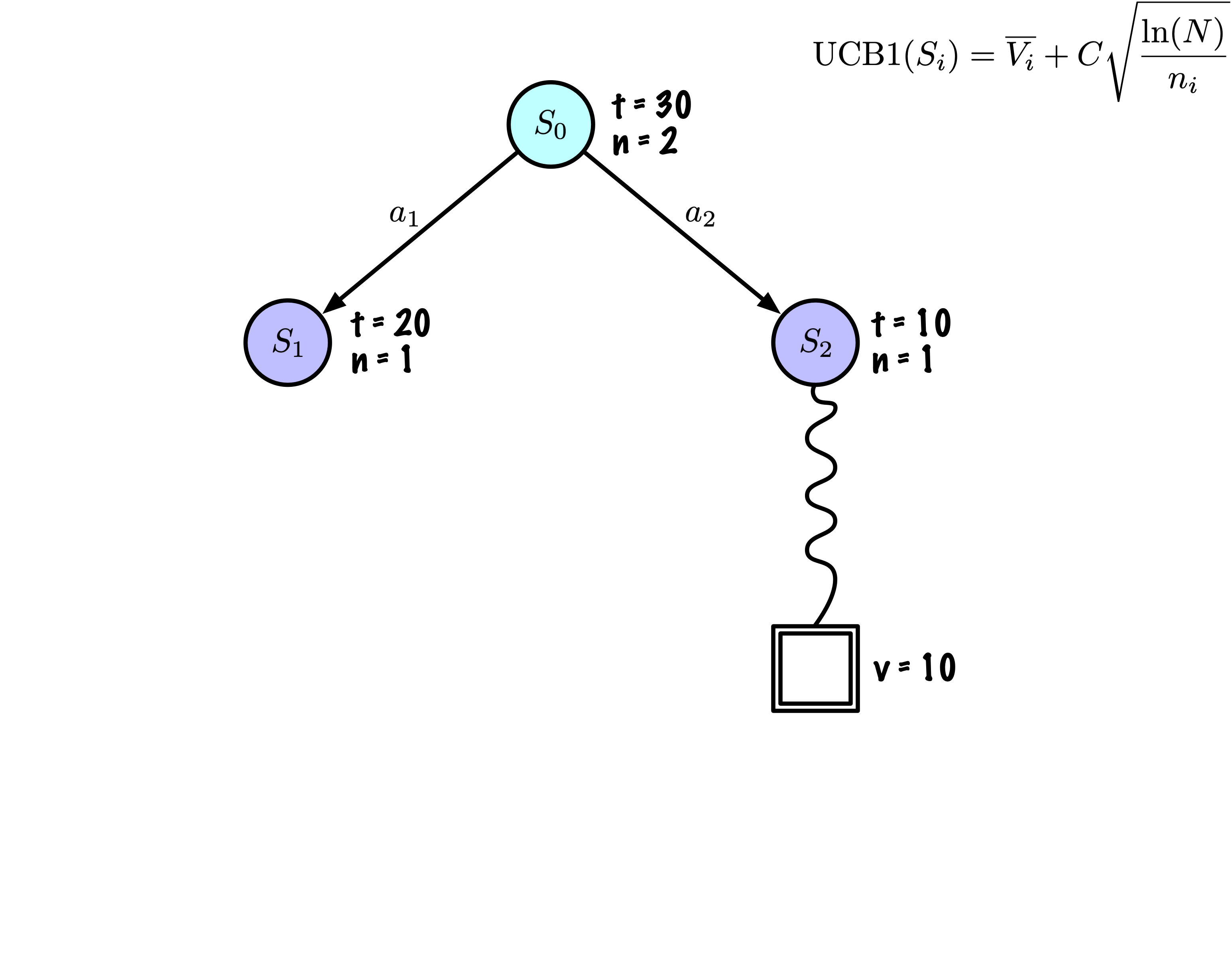
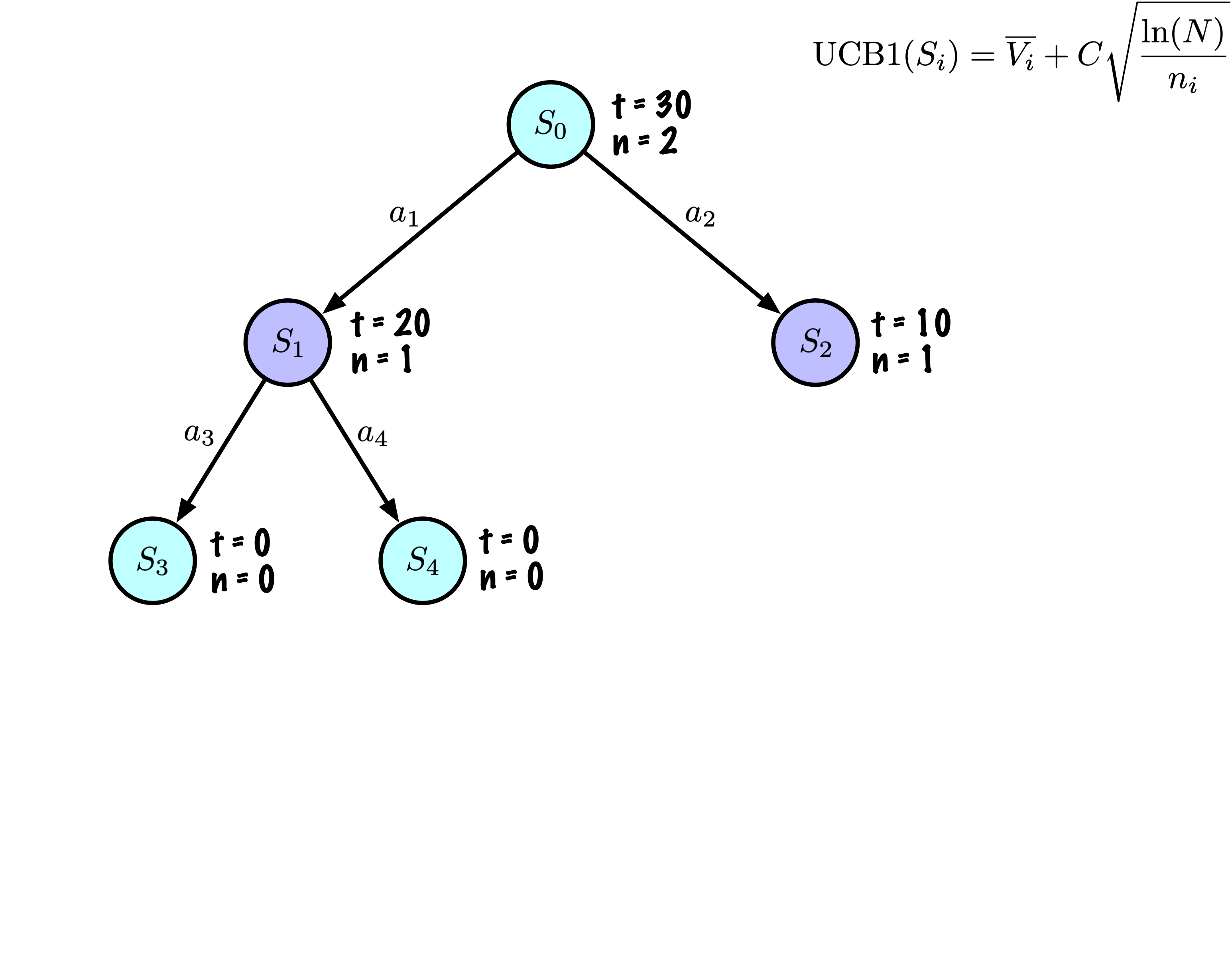
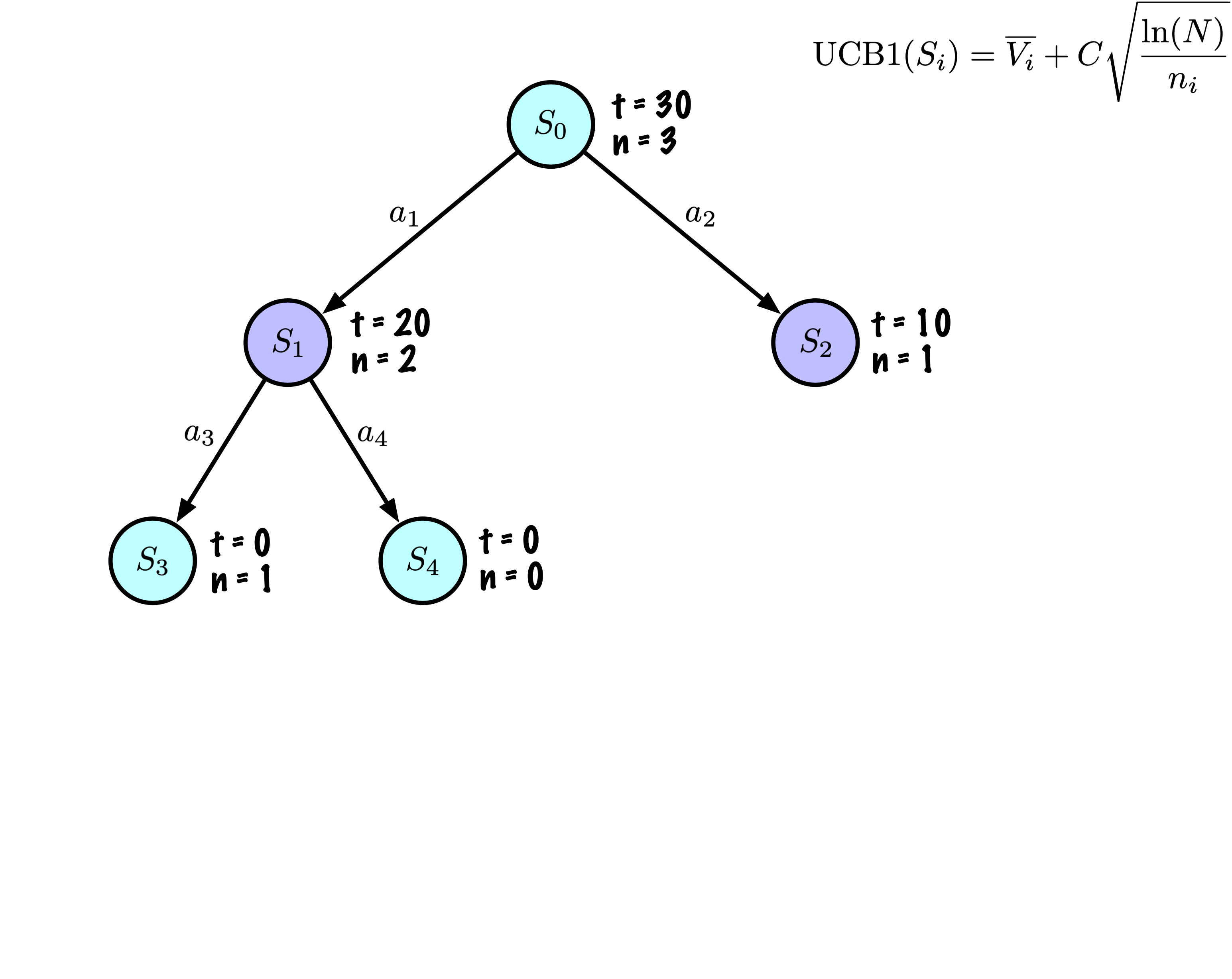
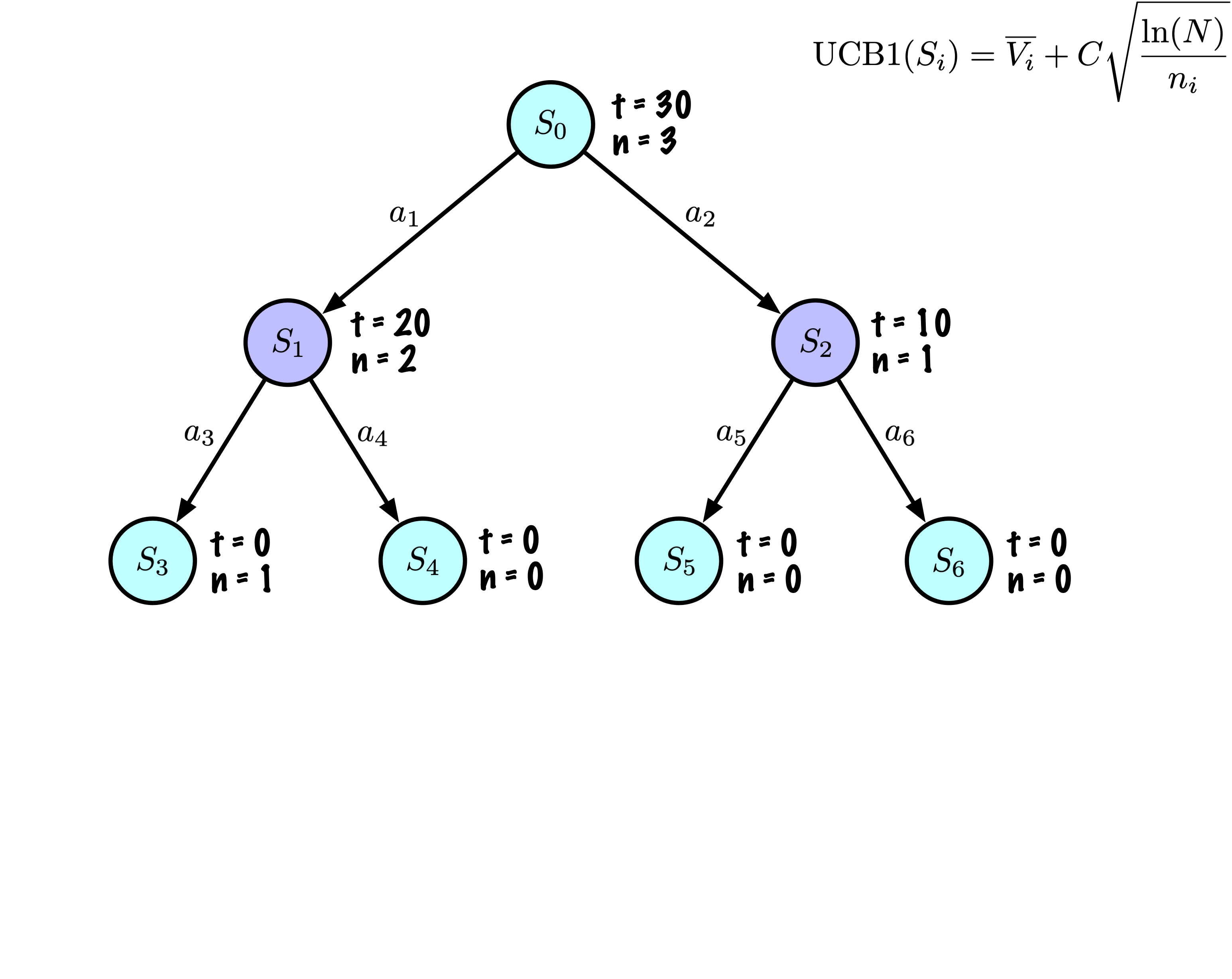
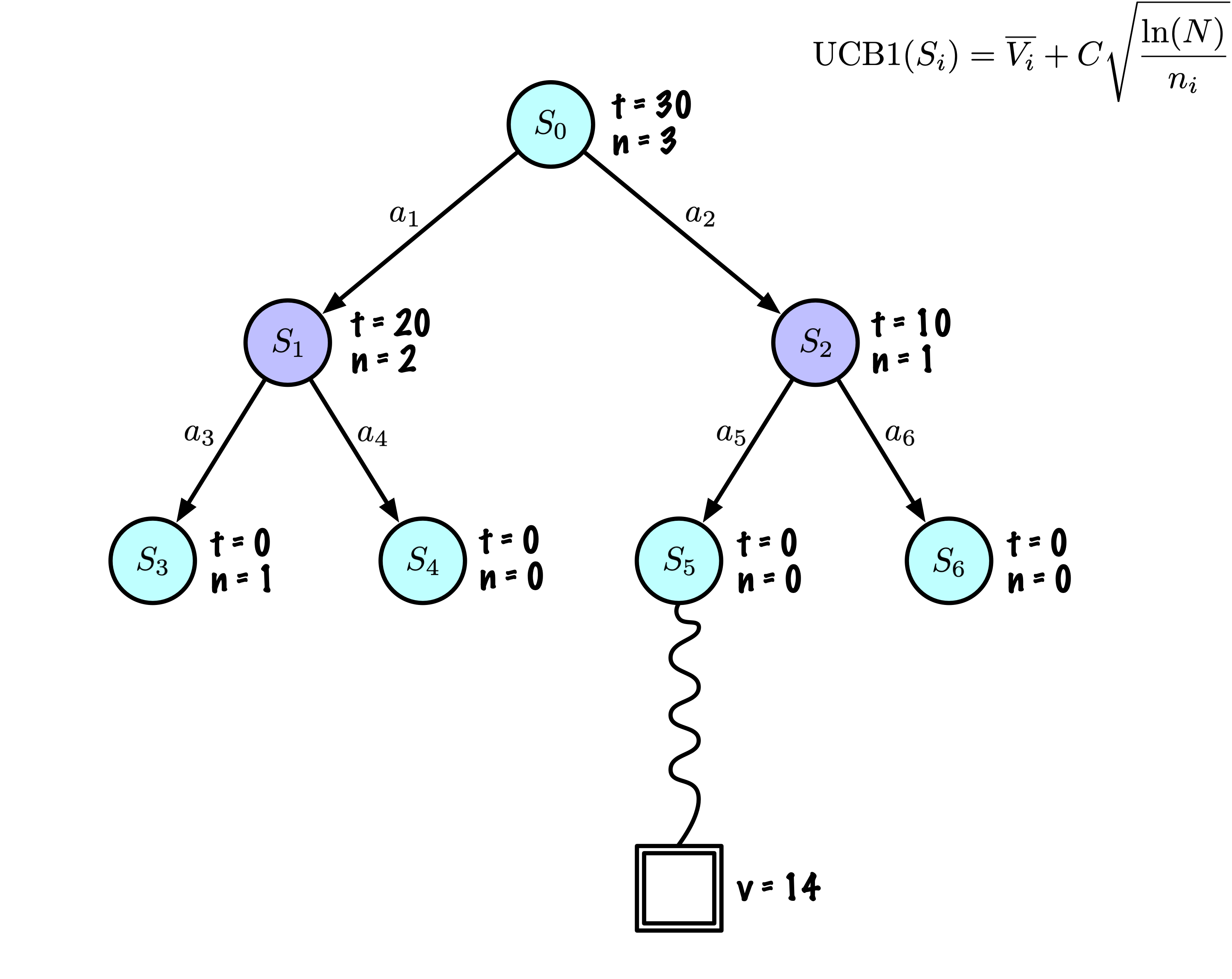
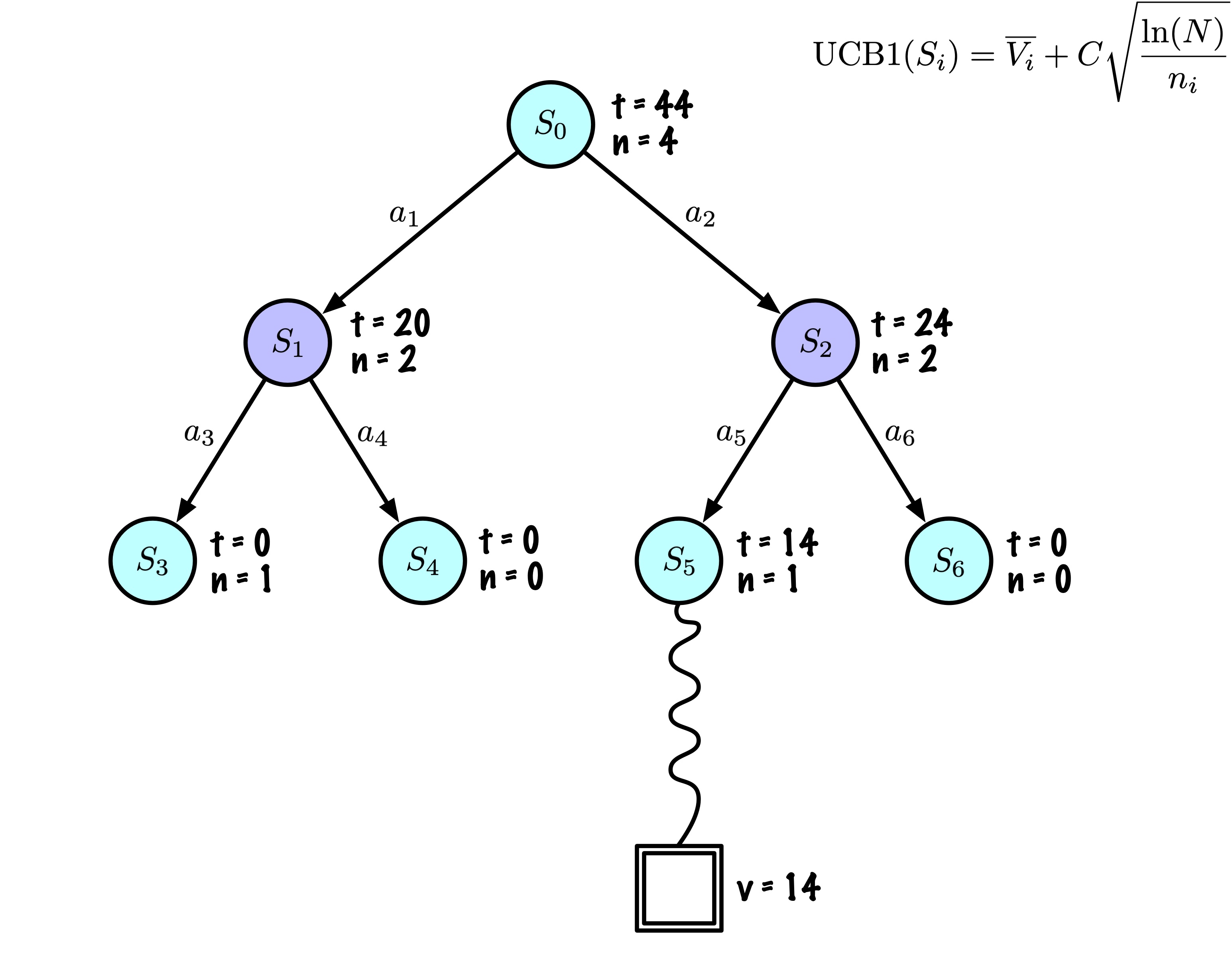
Sélection : Identifier le “meilleur” nœud en descendant un seul chemin dans l’arbre, guidé par UCB1.
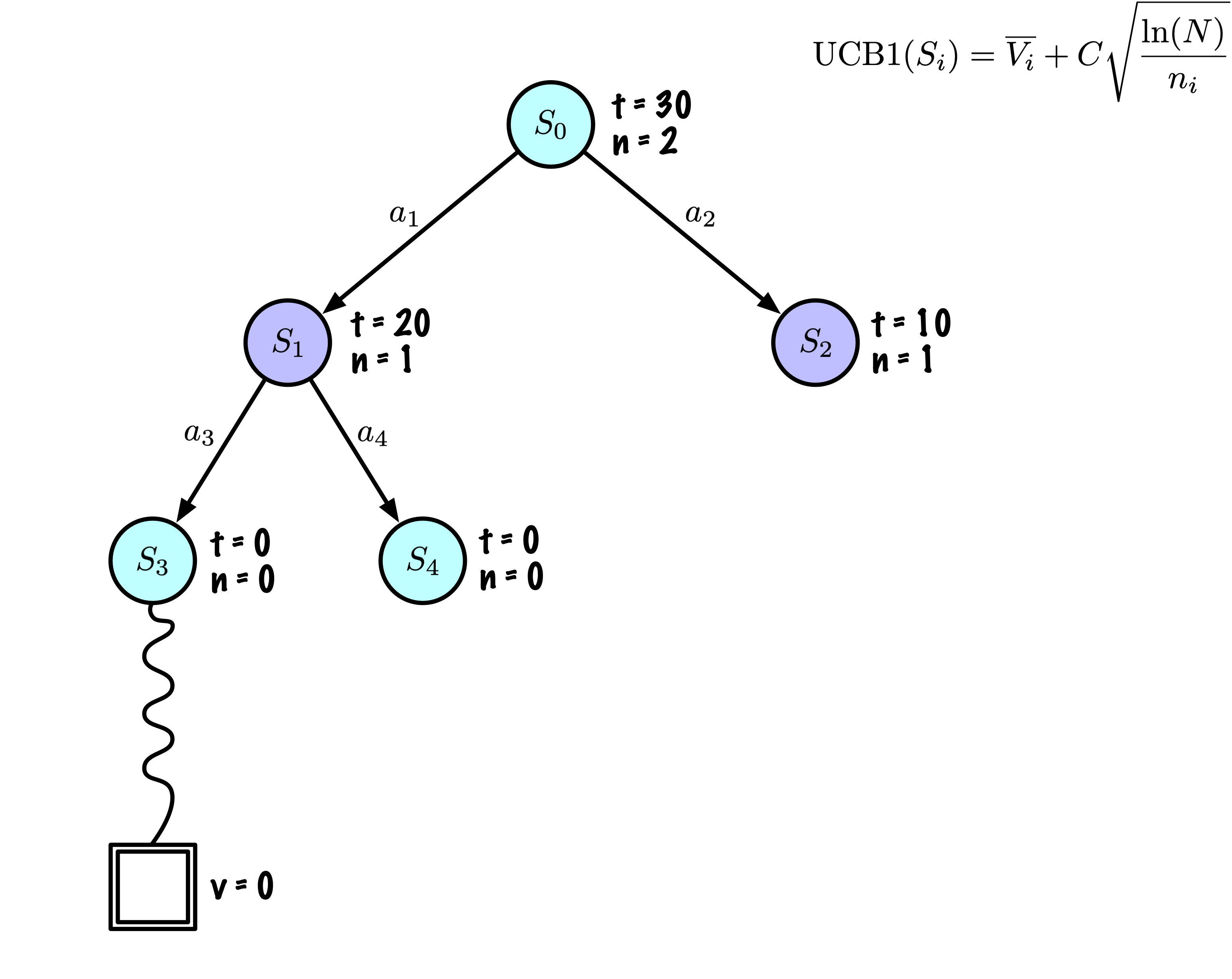
Expansion : Étendre le nœud s’il est une feuille dans l’arbre MCTS et \(n \gt 0\).
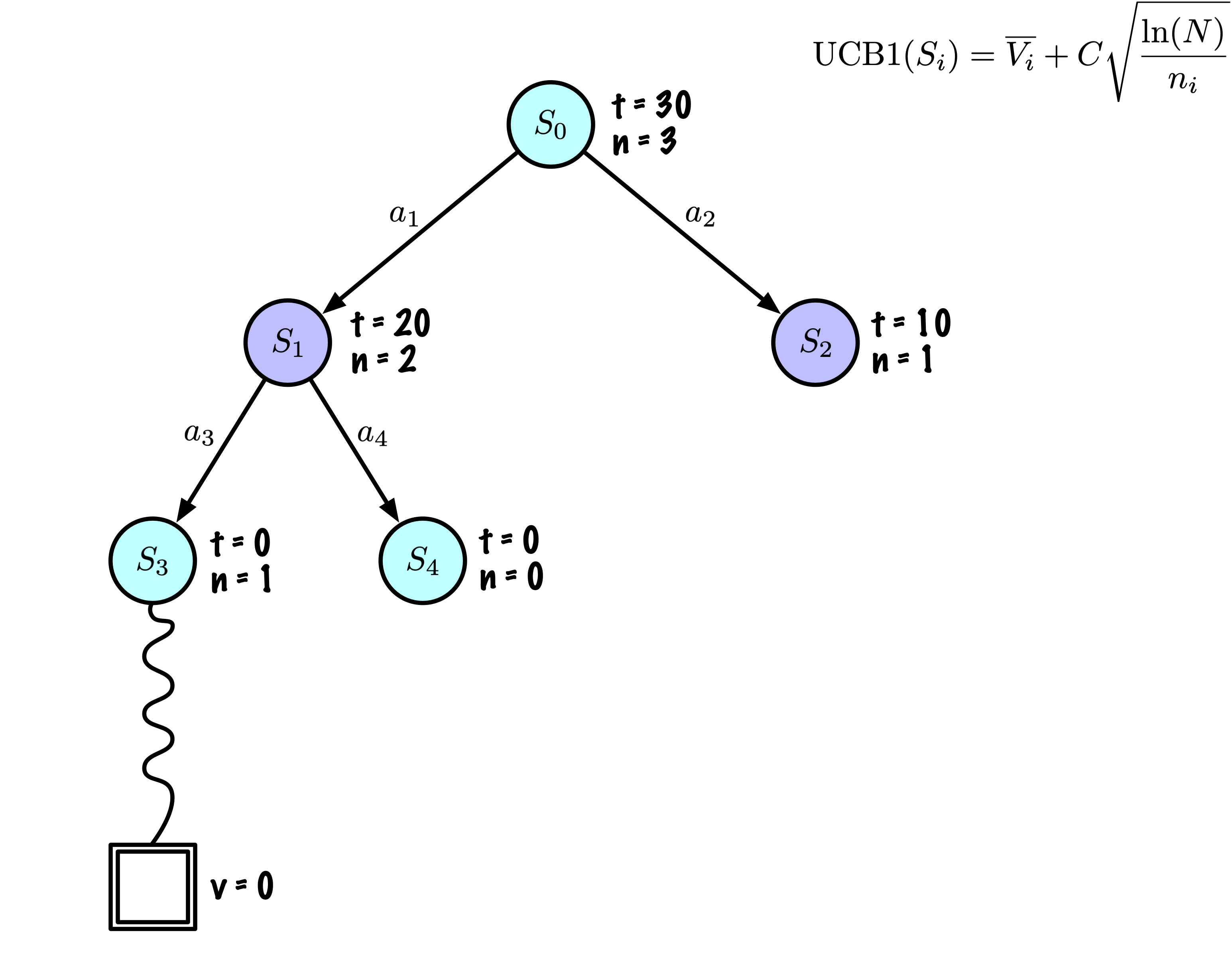
Simulation : Simuler une partie à partir de l’état actuel jusqu’à un état terminal en sélectionnant des actions au hasard.
Rétropropagation : Utiliser les informations obtenues pour mettre à jour le nœud actuel et tous les nœuds parents jusqu’à la racine.
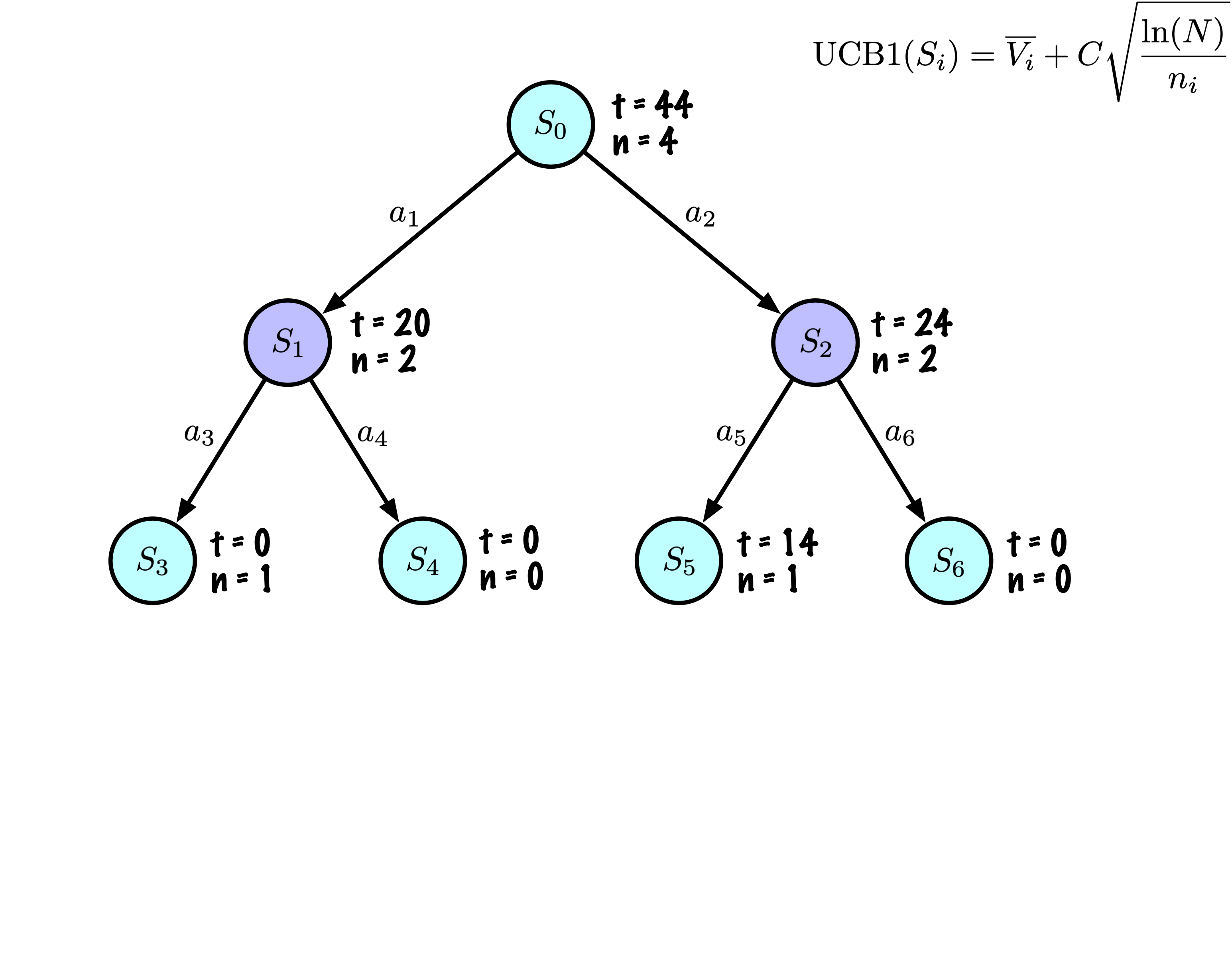
Résumé : nœuds
Chaque nœud enregistre son score total et son nombre de visites.
Cette information est utilisée pour calculer une valeur qui guide la descente de l’arbre, équilibrant exploration et exploitation.
Résumé : exploration vs exploitation
\[
\mathrm{UCB1}(S_i) = \overline{V_i} + C \sqrt{\frac{\ln(N)}{n_i}}
\]
La valeur habituelle pour \(C\) est \(\sqrt{2}\).
L’exploration se produit essentiellement lorsque deux nœuds ont approximativement le même score moyen, puis MCTS favorise les nœuds avec moins de visites (en divisant par \(n\)).
Pour \(n \lt \ln(N)\), la valeur du ratio est supérieure à 1, alors que pour \(n \gt \ln(N)\), le ratio devient inférieur à 1.
Il y a donc une petite fraction du temps où l’exploration intervient. Mais même dans ce cas, la contribution du ratio est assez modérée, nous prenons la racine carrée de ce ratio, multipliée par \(\sqrt{2} \sim 1.414213562\).
Résumé : exploration vs exploitation
Dans le recuit simulé, la température initiale et l’échelle de la fonction objectif sont liées.
Règle d’acceptation pour un déplacement candidat avec un changement de score \(\Delta E = E_{\text{nouveau}} - E_{\text{ancien}}\) :
Si \(\Delta E \le 0\) : toujours accepter (solution meilleure ou égale).
Si \(\Delta E > 0\) : accepter avec une probabilité
\[
p = \exp(-\Delta E / T).
\]
Résumé : exploration vs exploitation
Dans le Rrecuit simulé :
\(T\) définit à quel point un mauvais mouvement doit être “grand” avant qu’il ne soit peu probable d’être accepté.
Si \(T\) est grand par rapport au \(\Delta E\) typique :
Même des mouvements sensiblement aggravants ont une probabilité raisonnable.
Très exploratoire.
Si \(T\) est petit :
Seuls les mouvements très peu aggravants sont acceptés.
Principalement exploitant / recherche locale.
C’est pourquoi vous choisissez souvent la température initiale \(T\) en utilisant la distribution de \(\Delta E\) sur des états aléatoires : par exemple, “fixer \(T_0\) de sorte qu’un \(\Delta E\) typique ait, disons, 60-80% d’acceptation.” C’est explicitement lié à l’échelle de la fonction de score.
Résumé : C comme échelle d’exploration
Dans UCT (UCB1), nous utilisons
\[
\text{score}(i)
= V_i + C \sqrt{\frac{\ln N}{n_i}},
\]
où :
\(V_i\): valeur moyenne de simulation de l’enfant \(i\) (terme d’exploitation),
\(N\): nombre total de visites au nœud parent,
\(n_i\): visites à l’enfant \(i\),
\(C\): constante d’exploration.
Résumé : C comme échelle d’exploration
À un nœud donné :
L’enfant avec le plus grand \(\text{score}(i)\) est sélectionné.
Le second terme \[
C \sqrt{\frac{\ln N}{n_i}}
\] est pure exploration : grand quand \(n_i\) est petit, diminuant à mesure que vous visitez cet enfant.
Résumé : C comme échelle d’exploration
Considérons deux enfants, 1 et 2. Vous choisissez 2 au lieu de 1 quand :
La différence dans les valeurs moyennes de simulation qui peut être « annulée » par l’exploration est proportionnelle à \(C\).
Plus grand\(C\) → le terme d’exploration domine davantage → vous êtes prêt à essayer un enfant dont le \(V_i\) est significativement pire, juste parce qu’il est sous-exploré.
Plus petit\(C\) → vous vous en tenez davantage au \(V_i\)actuellement le plus prometteur.
Résumé : C comme échelle d’exploration
Dans la théorie classique de l’UCB1, les récompenses sont supposées être dans \([0,1]\), et il y a une constante recommandée spécifique (par exemple \(\sqrt{2}\)). Si votre échelle de récompense est différente (disons dans \([-1,1]\) ou de grande amplitude), vous redimensionnez essentiellement cette constante ; en pratique, les gens ajustent \(C\) empiriquement.
Résumé : C comme échelle d’exploration
Analogie :
Le \(T\) de l’optimisation simulée et le \(C\) de l’MCTS équilibrent tous deux exploration vs exploitation.
Dans les deux cas, leur signification effective dépend de l’échelle de l’objectif / des récompenses.
Dans SA : « à quel point un mouvement peut-il être mauvais et être encore souvent accepté ? »
Dans MCTS : « à quel point la valeur actuelle \(V_i\) d’un enfant peut-elle être pire et quand même être choisie pour l’exploration ? »
Résumé : C comme échelle d’exploration
Principales différences :
Recuit simulée :
Trajectoire unique.
\(T\) est explicitement programmé (de haut en bas) au fil du temps.
Équilibre les mouvements locaux dans un seul chemin de recherche.
Résumé : C comme échelle d’exploration
MCTS (UCT) :
Arbre de nombreux chemins.
\(C\) est constant, mais l’exploration décroît automatiquement via \(\sqrt{\ln N / n_i}\) :
Début : \(n_i\) petit → exploration élevée.
Fin : \(n_i\) grand → le terme d’exploration diminue, le comportement devient plus avide.
Architecture Commune de Jeu
Game
Code
import mathimport randomimport numpy as npimport matplotlib.pyplot as pltclass Game:""" Interface abstraite pour un jeu déterministe, à 2 joueurs, à somme nulle, avec prise de tours. Conventions (utilisées par le Tic-Tac-Toe et les solveurs ci-dessous) : - Les joueurs sont identifiés par les chaînes "X" et "O". - evaluate(state) retourne : > 0 si la position est favorable pour "X" < 0 si la position est favorable pour "O" == 0 pour une égalité ou une position non-terminale égale """def initial_state(self):"""Retourne un objet représentant la position de départ du jeu."""raiseNotImplementedErrordef get_valid_moves(self, state):""" Étant donné un état, retourne un itérable de coups légaux. Le type de 'move' dépend du jeu (par exemple, (ligne, colonne) pour le Tic-Tac-Toe). """raiseNotImplementedErrordef make_move(self, state, move, player):""" Retourne l'état successeur obtenu en appliquant 'move' pour 'player' à 'state'. L'état original ne doit pas être modifié sur place. """raiseNotImplementedErrordef get_opponent(self, player):"""Retourne l'adversaire de 'player'."""raiseNotImplementedErrordef is_terminal(self, state):""" Retourne True si 'state' est une position terminale (victoire, défaite ou égalité), False sinon. """raiseNotImplementedErrordef evaluate(self, state):""" Retourne une évaluation scalaire de 'state' : +1 pour une victoire de X, -1 pour une victoire de O, 0 sinon (pour le Tic-Tac-Toe). Pour d'autres jeux, cela peut être généralisé, mais ici nous gardons cela simple. """raiseNotImplementedErrordef display(self, state):"""Affiche une représentation lisible par l'humain de 'state' (pour le débogage)."""raiseNotImplementedError
TicTacToe
Code
class TicTacToe(Game):""" Implémentation classique du Tic-Tac-Toe 3x3 utilisant un tableau NumPy de chaînes de caractères. Les cases vides sont représentées par " ". Le joueur "X" est supposé être le joueur maximisant. """def__init__(self):self.size =3def initial_state(self):"""Retourne un plateau 3x3 vide."""return np.full((self.size, self.size), " ")def get_valid_moves(self, state):"""Tous les couples (i, j) où la case du plateau est vide."""return [ (i, j)for i inrange(self.size)for j inrange(self.size)if state[i, j] ==" " ]def make_move(self, state, move, player):""" Retourne un nouveau plateau avec 'player' placé à 'move' (ligne, colonne). L'état original n'est pas modifié. """ new_state = state.copy() new_state[move] = playerreturn new_statedef get_opponent(self, player):"""Échange les étiquettes des joueurs entre 'X' et 'O'."""return"O"if player =="X"else"X"def is_terminal(self, state):""" Un état est terminal si : - L'un des joueurs a une ligne de 3 (evaluate != 0), ou - Il n'y a plus de cases vides (match nul). """ifself.evaluate(state) !=0:returnTruereturn" "notin statedef evaluate(self, state):""" Retourne +1 si X a trois alignés, -1 si O a trois alignés, et 0 sinon (y compris les états non terminaux et les matchs nuls). Il s'agit d'une évaluation "théorique" du jeu dans les états terminaux ; pour les positions non terminales, nous retournons simplement 0. """ lines = []# Lignes et colonnesfor i inrange(self.size): lines.append(state[i, :]) # ligne i lines.append(state[:, i]) # colonne i# Diagonales principales lines.append(np.diag(state)) lines.append(np.diag(np.fliplr(state)))# Vérifie chaque ligne pour une victoirefor line in lines:if np.all(line =="X"):return1if np.all(line =="O"):return-1return0def display(self, state):""" Visualise un plateau de Tic-Tac-Toe en utilisant matplotlib. Paramètres ---------- state : np.ndarray de forme (size, size) Plateau contenant ' ', 'X' ou 'O'. """ size =self.size fig, ax = plt.subplots() ax.set_aspect('equal') ax.set_xlim(0, size) ax.set_ylim(0, size)# Dessine les lignes de la grillefor i inrange(1, size): ax.axhline(i, color='black') ax.axvline(i, color='black')# Cache complètement les axes ax.axis('off')# Dessine les symboles X et Ofor i inrange(size):for j inrange(size): cx = j +0.5 cy = size - i -0.5# inverse l'axe y pour une orientation correcte des lignes symbol = state[i, j]if symbol =="X": ax.plot(cx, cy, marker='x', markersize=40* (3/size), color='blue', markeredgewidth=3)elif symbol =="O": circle = plt.Circle((cx, cy), radius=0.30* (3/size), fill=False, color='red', linewidth=3) ax.add_patch(circle) plt.show()
Solver
Code
class Solver:""" Classe de base pour tous les solveurs (Aléatoire, Minimax, AlphaBeta, MCTS, etc.). Les solveurs doivent implémenter : - select_move(jeu, état, joueur) Les solveurs peuvent éventuellement implémenter : - reset() : appelé au début de chaque partie - opponent_played() : utilisé par les solveurs persistants (par exemple, MCTS) Remarques --------- • Les solveurs peuvent conserver un état interne qui persiste à travers les mouvements. • GameRunner peut appeler reset() automatiquement avant chaque match. """def select_move(self, jeu, état, joueur):""" Doit être implémentée par les sous-classes. Retourne un mouvement légal pour le joueur donné. """raiseNotImplementedErrordef get_name(self):""" Retourne le nom du solveur pour les rapports, journaux ou résultats de tournoi. Par défaut, retourne le nom de la classe, mais les solveurs peuvent surcharger pour inclure des paramètres (par exemple, "MCTS(num_simulations=500)""). """returnself.__class__.__name__def opponent_played(self, move):""" Optionnel. Appelé après le mouvement de l'adversaire. Utile pour les solveurs à état comme MCTS. Les solveurs sans état peuvent l'ignorer. """passdef reset(self):""" Optionnel. Appelé une fois au début de chaque partie. Surcharger uniquement si le solveur maintient un état interne (par exemple, arbre MCTS, analyse mise en cache, tables heuristiques). """pass
RandomSolver
Code
class RandomSolver(Solver):""" Un solveur de référence simple : - À chaque coup, choisit uniformément au hasard parmi tous les coups légaux. - Ne conserve aucun état interne (pas d'apprentissage). """def__init__(self, seed=None):self.rng = random.Random(seed)def select_move(self, game, state, player):"""Retourne un coup légal aléatoire pour le joueur actuel.""" moves = game.get_valid_moves(state)returnself.rng.choice(moves)def opponent_played(self, move):"""Le solveur aléatoire n'a aucun état interne à mettre à jour."""pass
GameRunner
Code
class GameRunner:""" Outil pour exécuter une seule partie entre deux solveurs sur un jeu donné. Cette classe est délibérément simple : elle alterne les coups entre "X" et "O" jusqu'à ce qu'un état terminal soit atteint. """def__init__(self, game, verbose=False):self.game = gameself.verbose = verbosedef play_game(self, solver_X, solver_O):""" Joue une partie complète : - solver_X contrôle le joueur "X" - solver_O contrôle le joueur "O" Retourne ------- result : int +1 si X gagne, -1 si O gagne, 0 pour un match nul. """ state =self.game.initial_state() player ="X" solvers = {"X": solver_X, "O": solver_O}# Jouer jusqu'à une position terminalewhilenotself.game.is_terminal(state):# Le joueur actuel sélectionne un coup move = solvers[player].select_move(self.game, state, player)# Appliquer le coup state =self.game.make_move(state, move, player)ifself.verbose:self.game.display(state)# Informer l'adversaire (pour les solveurs persistants comme MCTS) opp =self.game.get_opponent(player) solvers[opp].opponent_played(move)# Changer de joueur actif player = oppifself.verbose:print(self.game.evaluate(state), "\n")# Évaluation finale du point de vue de Xreturnself.game.evaluate(state)
evaluate_solvers
Code
def evaluate_solvers(game, solver_X, solver_O, num_games, verbose=False):""" Évaluer deux solveurs en confrontation directe sur un jeu donné. Paramètres ---------- game : Game Une instance d'un jeu (par exemple, TicTacToe). solver_X : Solver Solveur contrôlant le joueur "X" (le joueur maximisant). solver_O : Solver Solveur contrôlant le joueur "O" (le joueur minimisant). num_games : int Nombre de parties à jouer avec ces rôles fixes. Remarques --------- - Les mêmes instances de solveurs sont réutilisées à travers les jeux. Cela permet aux solveurs *persistants* (par exemple, MCTS) d'accumuler de l'expérience à travers les jeux. - Les résultats sont interprétés du point de vue de X : +1 -> X gagne -1 -> O gagne 0 -> match nul """ runner = GameRunner(game)# Agréger les statistiques sur tous les jeux results = {"X_wins": 0,"O_wins": 0,"draws": 0, }for i inrange(num_games):# Jouer une partie avec solver_X comme "X" et solver_O comme "O" outcome = runner.play_game(solver_X, solver_O)# Mettre à jour les compteurs en fonction du résultat (+1, -1 ou 0)if outcome ==1: results["X_wins"] +=1if verbose:print(f"Partie {i +1}: X gagne") elif outcome ==-1: results["O_wins"] +=1if verbose:print(f"Partie {i +1}: O gagne") else: results["draws"] +=1if verbose:print(f"Partie {i +1}: Match nul")# Imprimer le résumé finalif verbose:print(f"\nAprès {num_games} parties :")print(f" X ({solver_X.get_name()}) gagne : {results['X_wins']}")print(f" O ({solver_O.get_name()}) gagne : {results['O_wins']}")print(f" Matchs nuls : {results['draws']}")return results
MinimaxSolver
Code
from functools import lru_cachedef canonical(state):""" Convertir une grille NumPy en une représentation immuable et hachable (tuple de tuples). Cela nous permet de l'utiliser comme clé dans des dictionnaires ou comme argument pour lru_cache. MCTS peut également réutiliser cette représentation. """returntuple(map(tuple, state))class MinimaxSolver(Solver):""" Un solveur Minimax classique et exact pour le Tic-Tac-Toe. - Suppose que "X" est le joueur maximisant. - Utilise la mémoïsation (lru_cache) pour éviter de recalculer les valeurs pour des positions identiques. """def select_move(self, game, state, player):""" Interface publique : choisir le meilleur coup pour 'player' en utilisant Minimax. Pour le Tic-Tac-Toe, nous pouvons explorer en toute sécurité l'arbre de jeu complet. """# Stocker le jeu sur self pour que _minimax puisse l'utiliserself.game = game# Du point de vue de X : X maximise, O minimise maximizing = (player =="X")# Pour le Tic-Tac-Toe, depth=9 est suffisant pour couvrir tous les coups restants. _, move =self._minimax(canonical(state), player, maximizing, 9)return move@lru_cache(maxsize=None)def _minimax(self, state_key, player, maximizing, depth):""" Minimax récursif interne. Paramètres ---------- state_key : représentation hachable de la grille (tuple de tuples) player : joueur devant jouer à ce nœud ("X" ou "O") maximizing: True si ce nœud est un nœud 'max' (X doit jouer), False si c'est un nœud 'min' (O doit jouer) depth : profondeur de recherche restante (non utilisé pour les coupes dans cette implémentation de recherche complète du Tic-Tac-Toe, mais conservé à des fins didactiques et pour une extension facile). """# Récupérer la grille NumPy à partir de state_key canonique state = np.array(state_key)# Test terminal : victoire, défaite ou match nulifself.game.is_terminal(state):# L'évaluation est toujours du point de vue de X : +1, -1, ou 0returnself.game.evaluate(state), None moves =self.game.get_valid_moves(state) best_move =Noneif maximizing:# X doit jouer : maximiser l'évaluation best_val =-math.inffor move in moves: st2 =self.game.make_move(state, move, player) val, _ =self._minimax( canonical(st2),self.game.get_opponent(player),False, depth -1 )if val > best_val: best_val = val best_move = movereturn best_val, best_moveelse:# O doit jouer : minimiser l'évaluation (puisque l'évaluation est pour X) best_val = math.inffor move in moves: st2 =self.game.make_move(state, move, player) val, _ =self._minimax( canonical(st2),self.game.get_opponent(player),True, depth -1 )if val < best_val: best_val = val best_move = movereturn best_val, best_move
MinimaxAlphaBetaSolver
Code
class MinimaxAlphaBetaSolver(Solver):""" Un solveur Minimax classique amélioré avec l'élagage Alpha-Beta. - Suppose que "X" est le joueur maximisant. - Utilise la mémorisation (lru_cache) pour éviter de recalculer les états. - Effectue une recherche *complète* du Tic-Tac-Toe (profondeur=9). - Retourne le coup optimal pour le joueur actuel. """# ------------------------------------------------------------# Interface du solveur# ------------------------------------------------------------def select_move(self, game, state, player):""" Interface publique requise par Solver. Exécute la recherche Alpha-Beta depuis l'état actuel. """self.game = game maximizing = (player =="X") # X maximise, O minimise# Réinitialiser le cache entre les jeux pour éviter de stocker des millions de clésself._alphabeta.cache_clear() value, move =self._alphabeta( canonical(state), player, maximizing,9, # recherche en profondeur complète-math.inf, # alpha math.inf # beta )return move# ------------------------------------------------------------# Alpha-beta interne avec mémorisation# ------------------------------------------------------------@lru_cache(maxsize=None)def _alphabeta(self, state_key, player, maximizing, depth, alpha, beta):""" Paramètres ---------- state_key : plateau sous forme de tuple de tuples player : joueur dont c'est le tour ('X' ou 'O') maximizing: Vrai si ce nœud est un nœud de maximisation pour X depth : profondeur restante alpha : meilleure valeur garantie pour le maximiseur jusqu'à présent beta : meilleure valeur garantie pour le minimiseur jusqu'à présent """ state = np.array(state_key)# Cas terminal ou d'horizonifself.game.is_terminal(state) or depth ==0:returnself.game.evaluate(state), None moves =self.game.get_valid_moves(state) best_move =None# --------------------------------------------------------# MAX (X)# --------------------------------------------------------if maximizing: value =-math.inffor move in moves: st2 =self.game.make_move(state, move, player) child_val, _ =self._alphabeta( canonical(st2),self.game.get_opponent(player),False, # maintenant minimisant depth -1, alpha, beta )if child_val > value: value = child_val best_move = move alpha =max(alpha, value)if beta <= alpha:break# coupure βreturn value, best_move# --------------------------------------------------------# MIN (O)# --------------------------------------------------------else: value = math.inffor move in moves: st2 =self.game.make_move(state, move, player) child_val, _ =self._alphabeta( canonical(st2),self.game.get_opponent(player),True, # maintenant maximisant depth -1, alpha, beta )if child_val < value: value = child_val best_move = move beta =min(beta, value)if beta <= alpha:break# coupure αreturn value, best_move
Vérification
game = TicTacToe()a = RandomSolver(7)b = MinimaxSolver()results = evaluate_solvers(game, a, b, num_games=100)results
{'X_wins': 0, 'O_wins': 82, 'draws': 18}
Vérification
game = TicTacToe()a = RandomSolver(7)b = MinimaxAlphaBetaSolver()results = evaluate_solvers(game, a, b, num_games=100)results
{'X_wins': 0, 'O_wins': 82, 'draws': 18}
Implémentation
MCTSClassicSolver
Code
class MCTSClassicSolver(Solver):""" Une implémentation classique et initiale de la recherche arborescente de Monte Carlo (MCTS) pour les jeux déterministes à somme nulle à 2 joueurs (par exemple, Tic-Tac-Toe). Idées clés : - Pour chaque décision, nous construisons un arbre enraciné à la position actuelle. - Chaque nœud stocke : * état : position sur le plateau * joueur : joueur qui doit jouer dans cet état ("X" ou "O") * N : nombre de visites * W : récompense totale du point de vue de ce joueur * enfants : mouvement -> enfant Node * mouvements_non_essais : liste de mouvements légaux non encore développés * parent : lien vers le nœud parent (pour la rétropropagation) - Une *simulation* MCTS = sélection → expansion → simulation (rollout) → rétropropagation. - Nous jetons l'arbre après avoir retourné un mouvement (pas d'apprentissage). """class Node:"""Un seul nœud dans l'arbre de recherche MCTS."""def__init__(self, state, player, parent=None, moves=None):self.state = state # position sur le plateau (tableau NumPy)self.player = player # joueur qui doit jouer dans cet étatself.parent = parent # nœud parent (None pour la racine)self.children = {} # mouvement -> enfant Nodeself.untried_moves =list(moves) if moves isnotNoneelse []self.N =0# nombre de visitesself.W =0.0# récompense totale (du point de vue de ce joueur)def__init__(self, num_simulations=500, exploration_c=math.sqrt(2), seed=None):""" Paramètres ---------- num_simulations : int Nombre de simulations (jeux) à exécuter par mouvement. exploration_c : float Constante d'exploration C dans la formule UCT. seed : int ou None Graine aléatoire optionnelle pour la reproductibilité. """self.num_simulations = num_simulationsself.exploration_c = exploration_cself.rng = random.Random(seed)self.game =Noneself.root =None# nœud racine pour la recherche actuelle# ------------------------------------------------------------# Interface publique du solveur# ------------------------------------------------------------def select_move(self, game, state, player):""" Choisissez un mouvement pour 'player' dans 'state' en utilisant MCTS classique. Un nouvel arbre est construit à partir de zéro pour cet appel. L'arbre n'est pas réutilisé pour les mouvements ou les jeux ultérieurs. """self.game = gameself.root =None# nœud racine pour la recherche actuelle# Créez le nœud racine pour la position actuelle. root_state = state.copy() root_moves =self.game.get_valid_moves(root_state)self.root =self.Node(root_state, player, parent=None, moves=root_moves)# Exécutez plusieurs simulations en partant de la racine.for _ inrange(self.num_simulations):self._run_simulation()# Après les simulations, choisissez l'enfant avec le plus grand nombre de visites.ifnotself.root.children:# Pas d'enfants : pas de mouvements légaux (terminal). Revenir à l'aléatoire si nécessaire. moves =self.game.get_valid_moves(self.root.state)returnself.rng.choice(moves) if moves elseNone best_move =None best_visits =-1for move, child inself.root.children.items():if child.N > best_visits: best_visits = child.N best_move = movereturn best_movedef opponent_played(self, move):""" Le MCTS classique ici est sans état entre les mouvements et les jeux : nous reconstruisons l'arbre pour chaque décision. Nous n'avons donc pas besoin de suivre le mouvement de l'adversaire. """pass# ------------------------------------------------------------# Étapes internes du MCTS# ------------------------------------------------------------def _run_simulation(self):""" Effectuer une simulation MCTS à partir de la racine. 1. Sélection : descendre dans l'arbre en utilisant UCT jusqu'à atteindre un nœud terminal ou ayant des mouvements non essayés. 2. Expansion : si le nœud est non terminal et a des mouvements non essayés, développer un enfant. 3. Simulation (rollout) : à partir du nouvel enfant, jouer des mouvements aléatoires jusqu'à la fin du jeu. 4. Rétropropagation : mettre à jour N et W le long du chemin avec le résultat. """ node =self.root# 1. SÉLECTION : descendre tant que l'arbre est complètement développé et non terminal.whileTrue:ifself.game.is_terminal(node.state):# Position terminale : évaluer immédiatement. outcome =self.game.evaluate(node.state) # du point de vue de Xself._backpropagate(node, outcome)returnif node.untried_moves:# 2. EXPANSION : choisir un mouvement non essayé et créer un nœud enfant. move =self.rng.choice(node.untried_moves) node.untried_moves.remove(move) next_state =self.game.make_move(node.state, move, node.player) next_player =self.game.get_opponent(node.player) next_moves =self.game.get_valid_moves(next_state) child =self.Node(next_state, next_player, parent=node, moves=next_moves) node.children[move] = child# 3. SIMULATION : déroulement à partir du nouvel enfant créé. outcome =self._rollout(child.state, child.player)# 4. RÉTROPROPAGATION : mettre à jour tous les nœuds sur le chemin de l'enfant à la racine.self._backpropagate(child, outcome)return# Le nœud est complètement développé et non terminal → choisir un enfant par UCT. node =self._select_child(node)def _select_child(self, node):""" Sélection UCT : pour chaque enfant V_parent(child) = - (child.W / child.N) UCT = V_parent(child) + C * sqrt( ln(N_parent + 1) / N_child ) Nous stockons W et N du point de vue de l'enfant, donc nous négatifions child.W / child.N pour obtenir la perspective du parent. """ parent_visits = node.N best_score =-math.inf best_child =Nonefor move, child in node.children.items():if child.N ==0: score = math.inf # toujours explorer les enfants non visités au moins une foiselse:# Récompense moyenne du point de vue de l'enfant. avg_child = child.W / child.N# Le joueur parent et l'enfant alternent ; la récompense du point de vue du parent# est le négatif du point de vue de l'enfant. reward_parent =-avg_child exploration =self.exploration_c * math.sqrt( math.log(parent_visits +1) / child.N ) score = reward_parent + explorationif score > best_score: best_score = score best_child = childreturn best_childdef _rollout(self, state, player_to_move):""" Jouer aléatoirement à partir de 'state' jusqu'à la fin du jeu. Retourne le résultat final du point de vue de X : +1 si X gagne, -1 si O gagne, 0 pour match nul. """ current_state = state.copy() current_player = player_to_movewhilenotself.game.is_terminal(current_state): moves =self.game.get_valid_moves(current_state) move =self.rng.choice(moves) current_state =self.game.make_move(current_state, move, current_player) current_player =self.game.get_opponent(current_player)returnself.game.evaluate(current_state)def _backpropagate(self, node, outcome):""" Rétropropager le résultat de la simulation dans l'arbre. outcome est toujours du point de vue de X : +1, -1, ou 0. Pour chaque nœud sur le chemin de 'node' à la racine : - Convertir le résultat en fonction du point de vue du joueur de ce nœud : reward = outcome si node.player == "X" = -outcome si node.player == "O" - Mettre à jour : node.N += 1 node.W += reward """ current = nodewhile current isnotNone:if current.player =="X": reward = outcomeelse: reward =-outcome current.N +=1 current.W += reward current = current.parent
Node
class MCTSClassicSolver(Solver):class Node:def__init__(self, state, player, parent=None, moves=None):self.state = state # position du plateau (tableau NumPy)self.player = player # joueur qui doit jouer dans cet étatself.parent = parent # nœud parent (None pour la racine)self.children = {} # coup -> nœud enfantself.untried_moves =list(moves) if moves isnotNoneelse []self.N =0# nombre de visitesself.W =0.0# récompense totale (du point de vue de ce joueur)
def select_move(self, game, state, player):self.game = gameself.root =None# construire un nouvel arbre pour chaque appel# Créer le nœud racine pour la position actuelle. root_state = state.copy() root_moves =self.game.get_valid_moves(root_state)self.root =self.Node(root_state, player, parent=None, moves=root_moves)# Exécuter plusieurs simulations à partir de la racine.for _ inrange(self.num_simulations):self._run_simulation() best_move =None best_visits =-1for move, child inself.root.children.items():if child.N > best_visits: best_visits = child.N best_move = movereturn best_move
Interface publique Solver
def opponent_played(self, move):pass
_run_simulation
def _run_simulation(self): node =self.root# 1. SÉLECTION : descendre tant que complètement développé et non terminal.whileTrue:ifself.game.is_terminal(node.state):# Position terminale : évaluer immédiatement. outcome =self.game.evaluate(node.state) # du point de vue de Xself._backpropagate(node, outcome)returnif node.untried_moves:# 2. EXPANSION : choisir un mouvement non essayé et créer un nœud enfant. move =self.rng.choice(node.untried_moves) node.untried_moves.remove(move) next_state =self.game.make_move(node.state, move, node.player) next_player =self.game.get_opponent(node.player) next_moves =self.game.get_valid_moves(next_state) child =self.Node(next_state, next_player, parent=node, moves=next_moves) node.children[move] = child# 3. SIMULATION : déroulement à partir du nouvel enfant créé. outcome =self._rollout(child.state, child.player)# 4. RÉTROPROPAGATION : mettre à jour tous les nœuds sur le chemin de l'enfant à la racine.self._backpropagate(child, outcome)return# Le nœud est complètement développé et non terminal → choisir un enfant par UCT. node =self._select_child(node)
_select_child
def _select_child(self, node): parent_visits = node.N best_score =-math.inf best_child =Nonefor move, child in node.children.items():if child.N ==0: score = math.inf # toujours explorer les enfants non visités au moins une foiselse:# Récompense moyenne du point de vue de l'enfant. avg_child = child.W / child.N# Les joueurs parent et enfant alternent ; la récompense du point de vue du parent# est le négatif du point de vue de l'enfant. reward_parent =-avg_child exploration =self.exploration_c * math.sqrt( math.log(parent_visits +1) / child.N ) score = reward_parent + explorationif score > best_score: best_score = score best_child = childreturn best_child
def _backpropagate(self, node, outcome): current = nodewhile current isnotNone:if current.player =="X": reward = outcomeelse: reward =-outcome current.N +=1 current.W += reward current = current.parent
visualize_tree
Code
from graphviz import Digraphdef visualize_tree(root, max_depth=3, show_mcts_stats=True, show_edge_labels=True):""" Visualiser un arbre de jeu enraciné à `root` en utilisant Graphviz. Suppose : - `root` est un nœud avec les attributs : state, player, children: dict[move -> Node], N, W. - Cela correspond au nœud utilisé dans MCTSClassicSolver. Paramètres ---------- root : Node Racine de l'(sous-)arbre à visualiser. max_depth : int Profondeur maximale pour la récursion (racine à la profondeur 0). show_mcts_stats : bool Si vrai, inclure N et V pour chaque nœud (mise en page verticale compacte). show_edge_labels : bool Si vrai, étiqueter les arêtes avec le mouvement (par exemple, (ligne, colonne)). """ dot = Digraph(format="png") dot.edge_attr.update( fontsize="8", fontname="Comic Sans MS" )# Rendre l'arbre compact dot.graph_attr.update( rankdir="TB", # de haut en bas nodesep="0.15", # espacement horizontal ranksep="0.50", # espacement vertical ) dot.node_attr.update( shape="box", fontsize="9", fontname="Comic Sans MS", margin="0.02,0.02", )def add_node(node, node_id, depth):if depth > max_depth:return# Construire une étiquette compacteif show_mcts_stats and node.N >0: V = node.W / node.N# joueur en haut, puis N, puis V (vertical) label =f"{node.player}\\nN={node.N}\\nV={V:.2f}"else: label =f"{node.player}" dot.node(node_id, label=label)# Recurse sur les enfantsif depth == max_depth:returnfor move, child in node.children.items(): child_id =f"{id(child)}"if show_edge_labels: dot.edge(node_id, child_id, label=str(move))else: dot.edge(node_id, child_id) add_node(child, child_id, depth +1) add_node(root, "root", depth=0)return dot
def tally_scores(game):""" Énumérer tous les jeux complets de Tic-Tac-Toe depuis la position initiale (X doit jouer) et compter combien se terminent par : - victoire de X - match nul - victoire de O Retourne ------- overall : dict {'X': total_victoires_X, 'draw': total_matchs_nuls, 'O': total_victoires_O} table : list[list[dict]] Une liste 3x3 de dictionnaires. Pour chaque case (i, j), table[i][j] = {'X': ..., 'draw': ..., 'O': ...} compte les jeux où le *premier coup* de X était à (i, j). """ size = game.size # devrait être 3 pour le Tic-Tac-Toe standard# Décomptes globaux pour tous les jeux overall = {'X': 0, 'draw': 0, 'O': 0}# Décomptes par premier coup sous forme de grille 3x3 table = [ [ {'X': 0, 'draw': 0, 'O': 0} for _ inrange(size) ]for _ inrange(size) ]def recurse(state, player, first_move):""" Énumération en profondeur de tous les jeux complets. Paramètres ---------- state : position du plateau (tableau NumPy) player : 'X' ou 'O' (joueur à jouer) first_move : None, ou (ligne, colonne) du tout premier coup de X """# Cas de base : état terminal → classer le résultatif game.is_terminal(state): v = game.evaluate(state) # +1 (victoire de X), -1 (victoire de O), 0 (match nul)if v >0: outcome ='X'elif v <0: outcome ='O'else: outcome ='draw'# Mettre à jour le décompte global overall[outcome] +=1# Si nous connaissons le premier coup de X, mettre à jour le décompte de cette case aussiif first_move isnotNone: i, j = first_move table[i][j][outcome] +=1return# Cas récursif : étendre tous les coups légauxfor move in game.get_valid_moves(state): next_state = game.make_move(state, move, player) next_player = game.get_opponent(player)# Enregistrer le tout premier coup de Xif first_move isNoneand player =="X": fm = move # cela devient le first_move pour le reste de cette brancheelse: fm = first_move recurse(next_state, next_player, fm)# Commencer par le plateau vide, X doit jouer, et pas de first_move encore initial_state = game.initial_state() recurse(initial_state, player="X", first_move=None)return overall, tabledef print_tally_table(table):""" Imprimer une table 3x3 des décomptes. Chaque case montre : X:<victoires> D:<matchs nuls> O:<victoires> où les comptes sont restreints aux jeux où le premier coup de X a été joué dans cette case. """ size =len(table)for i inrange(size): row_cells = []for j inrange(size): stats = table[i][j] cell_str =f"X:{stats['X']} D:{stats['draw']} O:{stats['O']}" row_cells.append(cell_str)print(" | ".join(row_cells))print()def print_tally_table_percentages(table):""" Imprimer une table 3x3 des décomptes en pourcentages. Chaque case montre : X:<victoires> D:<matchs nuls> O:<victoires> où les comptes sont restreints aux jeux où le premier coup de X a été joué dans cette case. """ size =len(table)for i inrange(size): row_cells = []for j inrange(size): stats = table[i][j] cell_str =f"X:{stats['X']/255168:.2%} D:{stats['draw']/255168:.2%} O:{stats['O']/255168:.2%}" row_cells.append(cell_str)print(" | ".join(row_cells))print()game = TicTacToe()overall, table = tally_scores(game)print("Décompte global :")print(overall) # {'X': ..., 'draw': ..., 'O': ...}print("\nDécomptes par premier coup de X (grille 3x3, X/draw/O) :")print_tally_table(table)print("\nDécomptes par premier coup de X (grille 3x3, X/draw/O) en pourcentages :")print_tally_table_percentages(table)
Décompte global :
{‘X’: 131184, ‘draw’: 46080, ‘O’: 77904}
{‘X’: 51.41%, ‘draw’: 18.06%, ‘O’: 30.53%}
Décomptes par premier coup de X (grille 3x3) :
14652/5184/7896
14232/5184/10176
14652/5184/7896
14232/5184/10176
15648/4608/5616
14232/5184/10176
14652/5184/7896
14232/5184/10176
14652/5184/7896
Décomptes par premier coup de X (grille 3x3) en pourcentage :
5.74% / 2.03% / 3.09%
5.58% / 2.03% / 3.99%
5.74% / 2.03% / 3.09%
5.58% / 2.03% / 3.99%
6.13% / 1.81% / 2.20%
5.58% / 2.03% / 3.99%
5.74% / 2.03% / 3.09%
5.58% / 2.03% / 3.99%
5.74% / 2.03% / 3.09%
evaluate_solvers_with_plot
Code
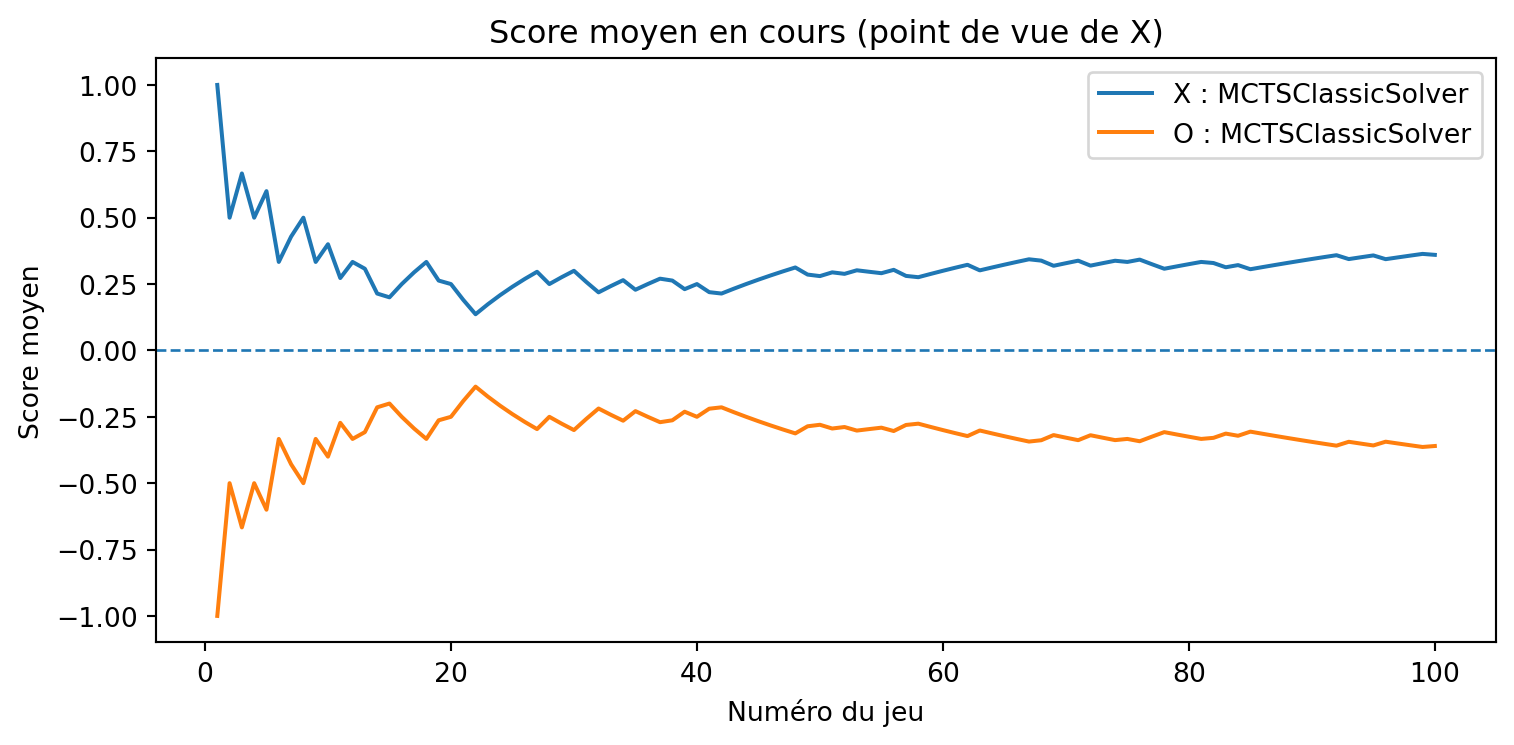
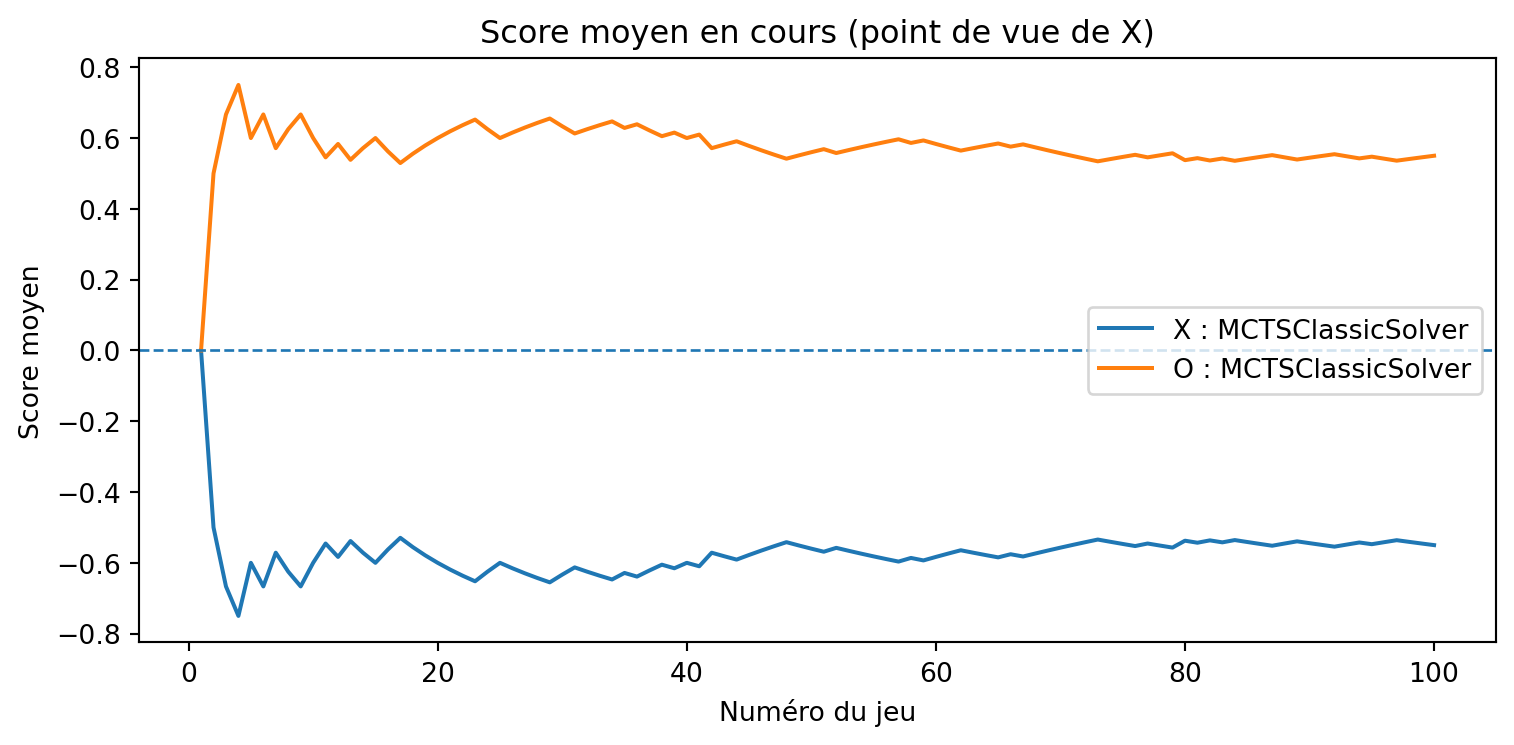
def evaluate_solvers_with_plot(game, solver_X, solver_O, num_games):""" Jouer 'num_games' parties entre solver_X (comme 'X') et solver_O (comme 'O'), suivre la performance cumulative et tracer les scores moyens en cours. Le score est du point de vue de X : résultat = +1 si X gagne résultat = -1 si O gagne résultat = 0 si match nul Le score moyen en cours pour O est simplement le négatif du score moyen en cours de X (somme nulle). """ runner = GameRunner(game)# Compteurs pour le résumé final results = {"X_wins": 0,"O_wins": 0,"draws": 0, }# Pour le traçage : score moyen en cours en fonction de l'indice du jeu avg_scores_X = [] avg_scores_O = [] cumulative_score_X =0.0for i inrange(num_games): outcome = runner.play_game(solver_X, solver_O)# Mettre à jour les compteurs de victoires/matchs nulsif outcome ==1: results["X_wins"] +=1elif outcome ==-1: results["O_wins"] +=1else: results["draws"] +=1# Mettre à jour le score cumulatif (du point de vue de X) cumulative_score_X += outcome avg_X = cumulative_score_X / (i +1) avg_O =-avg_X # somme nulle avg_scores_X.append(avg_X) avg_scores_O.append(avg_O)# Tracer les scores moyens en cours games =range(1, num_games +1) plt.figure(figsize=(8, 4)) plt.plot(games, avg_scores_X, label=f"X : {solver_X.get_name()}") plt.plot(games, avg_scores_O, label=f"O : {solver_O.get_name()}") plt.axhline(0.0, linestyle="--", linewidth=1) plt.xlabel("Numéro du jeu") plt.ylabel("Score moyen") plt.title("Score moyen en cours (point de vue de X)") plt.legend() plt.tight_layout() plt.show()return results, avg_scores_X, avg_scores_O
MCTS (peu de simulations) vs MCTS (beaucoup de simulations)
{'X_wins': 2, 'O_wins': 57, 'draws': 41}
Apprentissage à travers les actions et les jeux
Code
class MCTSSolver(Solver):""" Solveur de recherche arborescente de Monte Carlo pour des jeux déterministes, à somme nulle, à deux joueurs comme le Tic-Tac-Toe. Idées clés : - Le solveur maintient un arbre de recherche indexé par canonical(state). - Chaque nœud stocke : * N : nombre de visites * W : récompense totale du point de vue du joueur qui doit jouer à ce nœud (positif est bon pour ce joueur) * children : mappage move -> child_state_key * untried_moves : actions qui n'ont pas encore été développés * player : le joueur qui doit jouer à ce nœud ("X" ou "O") - select_move() : * S'assure que l'état actuel est dans l'arbre. * Exécute un nombre fixe de simulations à partir de la racine actuelle. * Retourne l'action menant à l'enfant le plus visité. - opponent_played(move) : * Avance la racine interne le long du mouvement réellement joué (si ce mouvement a été exploré). * Cela permet au solveur de réutiliser les statistiques de recherche à travers les mouvements et à travers les jeux. """def__init__(self, num_simulations=500, exploration_c=math.sqrt(2), seed=None):""" Paramètres ---------- num_simulations : int Nombre de simulations MCTS à exécuter par mouvement. exploration_c : float Constante d'exploration 'c' dans la formule UCT. seed : int ou None Graine aléatoire optionnelle pour la reproductibilité. """self.num_simulations = num_simulationsself.exploration_c = exploration_cself.rng = random.Random(seed)# L'arbre de recherche : dictionnaire state_key -> nodeself.tree = {}# Racine actuelle dans l'arbreself.root_key =None# canonical(state)self.root_player =None# joueur qui doit jouer à la racine ("X" ou "O")# Référence du jeu (définie lors du premier select_move)self.game =None# -----------------------------# API publique# -----------------------------def select_move(self, game, state, player):""" Choisir un mouvement pour 'player' à partir de 'state' en utilisant la recherche arborescente de Monte Carlo. Cette méthode : 1. Synchronise la racine interne avec l'état fourni. 2. Exécute un nombre fixe de simulations MCTS depuis la racine. 3. Retourne le mouvement menant à l'enfant avec le plus grand nombre de visites. """self.game = game state_key = canonical(state)# S'assurer que la racine de l'arbre correspond à l'état actuel.# Si cet état a été vu auparavant, nous réutilisons son nœud et ses statistiques.self.root_key = state_keyself.root_player = playerself._get_or_create_node(state_key, player)# Exécuter les simulations MCTS à partir de la racine actuellefor _ inrange(self.num_simulations):self._run_simulation()# Après les simulations, choisir l'enfant avec le plus grand nombre de visites. root_node =self.tree[self.root_key]ifnot root_node["children"]:# Pas d'enfants : doit être un état terminal ou pas de mouvements légaux.# Revenir à un mouvement valide (ou lever une erreur) ; ici nous choisissons au hasard. moves =self.game.get_valid_moves(np.array(self.root_key))returnself.rng.choice(moves) best_move =None best_visits =-1for move, child_key in root_node["children"].items(): child =self.tree[child_key]if child["N"] > best_visits: best_visits = child["N"] best_move = movereturn best_movedef opponent_played(self, move):""" Mettre à jour la racine interne en fonction du mouvement de l'adversaire. Cela est appelé par GameRunner après que l'autre joueur a effectué un mouvement. Nous essayons de déplacer la racine vers le nœud enfant correspondant : - Si le mouvement a été exploré, nous réutilisons ce sous-arbre. - Sinon, nous créons un nouveau nœud pour l'état résultant. """# Si nous n'avons pas encore de racine ou de référence de jeu, rien à faire.ifself.root_key isNoneorself.game isNone:return root_node =self.tree.get(self.root_key)if root_node isNone:# Ne devrait pas arriver, mais soyons robustes.self.root_key =Noneself.root_player =Nonereturn# Si nous avons déjà exploré ce mouvement depuis la racine, juste descendre l'arbre.if move in root_node["children"]: child_key = root_node["children"][move]self.root_key = child_keyself.root_player =self.tree[child_key]["player"]return# Sinon, nous devons appliquer le mouvement sur le plateau et créer un nouveau nœud. state = np.array(self.root_key) player_who_played = root_node["player"] next_state =self.game.make_move(state, move, player_who_played) next_key = canonical(next_state) next_player =self.game.get_opponent(player_who_played)self.root_key = next_keyself.root_player = next_playerself._get_or_create_node(next_key, next_player)# -----------------------------# Aides internes# -----------------------------def _get_or_create_node(self, state_key, player_to_move):""" S'assurer qu'un nœud pour 'state_key' existe dans l'arbre. S'il n'est pas présent, le créer avec : - N = 0, W = 0 - untried_moves = tous les mouvements valides depuis cet état - children = {} - player = player_to_move """if state_key notinself.tree: state = np.array(state_key)self.tree[state_key] = {"N": 0, # nombre de visites"W": 0.0, # récompense totale du point de vue du joueur du nœud"children": {}, # move -> child_state_key"untried_moves": self.game.get_valid_moves(state),"player": player_to_move, }returnself.tree[state_key]def _run_simulation(self):""" Effectuer une simulation MCTS à partir de la racine actuelle : 1. SÉLECTION : Suivre l'arbre en utilisant UCT jusqu'à atteindre un nœud avec des untried_moves ou un état terminal. 2. EXPANSION : Si le nœud a des untried_moves et n'est pas terminal, développer un mouvement. 3. DÉROULEMENT : À partir de la nouvelle feuille, jouer des mouvements aléatoires jusqu'à un état terminal. 4. RÉTROPROPAGATION : Propager le résultat final le long du chemin visité. """ifself.root_key isNone:return# rien à faire state_key =self.root_key state = np.array(state_key) path = [] # liste des state_keys visités lors de cette simulation# -------------------------# 1–2. Sélection & Expansion# -------------------------whileTrue: path.append(state_key) node =self.tree[state_key]# Si c'est un état terminal, arrêter et évaluer directement.ifself.game.is_terminal(state): outcome =self.game.evaluate(state) # du point de vue de Xbreak# S'il y a des mouvements non essayés, en développer un.if node["untried_moves"]: move = node["untried_moves"].pop() next_state =self.game.make_move(state, move, node["player"]) next_key = canonical(next_state) next_player =self.game.get_opponent(node["player"])# Créer le nœud enfant s'il n'existe pas encore.self._get_or_create_node(next_key, next_player)# Lier l'enfant dans l'arbre node["children"][move] = next_key# Le déroulement commence à partir de ce nouveau nœud feuille. state_key = next_key state = next_state path.append(state_key) outcome =self._rollout(state, next_player)break# Sinon, le nœud est complètement développé : sélectionner un enfant en utilisant UCT. move, child_key =self._select_child(node) state_key = child_key state = np.array(state_key)# -------------------------# 4. Rétropropagation# -------------------------self._backpropagate(path, outcome)def _select_child(self, node):""" Sélectionner un enfant de 'node' en utilisant la règle UCT (Upper Confidence Bound). Score UCT du point de vue du joueur à 'node' : score(child) = mean_reward_from_node_perspective + c * sqrt( ln(N_parent + 1) / N_child ) Remarque : - Chaque enfant stocke W et N de la perspective de son propre joueur. - Nous convertissons la valeur de l'enfant à la perspective du parent en inversant le signe, car le joueur enfant est toujours l'adversaire du joueur parent dans un jeu à deux joueurs alternant. """ parent_visits = node["N"] parent_player = node["player"] best_move =None best_child_key =None best_score =-math.inffor move, child_key in node["children"].items(): child =self.tree[child_key]if child["N"] ==0:# Encourager l'exploration des enfants non visités au moins une fois. uct_score = math.infelse:# Récompense moyenne du point de vue du joueur de l'enfant. avg_child_reward = child["W"] / child["N"]# Convertir à la perspective du parent.# Les joueurs parent et enfant sont toujours des adversaires ici. reward_from_parent_perspective =-avg_child_reward uct_score = ( reward_from_parent_perspective+self.exploration_c* math.sqrt(math.log(parent_visits +1) / child["N"]) )if uct_score > best_score: best_score = uct_score best_move = move best_child_key = child_keyreturn best_move, best_child_keydef _rollout(self, state, player_to_move):""" Effectuer un déroulement aléatoire (simulation) à partir de 'state' jusqu'à un état terminal. Paramètres ---------- state : tableau NumPy Position actuelle du plateau. player_to_move : str Joueur à jouer ("X" ou "O") au début de ce déroulement. Renvoie ------- outcome : int Résultat final du jeu du point de vue de X : +1 (X gagne), -1 (O gagne), ou 0 (match nul). """ current_state = state.copy() current_player = player_to_move# Jouer des mouvements aléatoires jusqu'à la fin du jeu.whilenotself.game.is_terminal(current_state): moves =self.game.get_valid_moves(current_state) move =self.rng.choice(moves) current_state =self.game.make_move(current_state, move, current_player) current_player =self.game.get_opponent(current_player)returnself.game.evaluate(current_state) # +1, -1, ou 0 du point de vue de Xdef _backpropagate(self, path, outcome):""" Rétropropager le résultat final le long du chemin de simulation. Paramètres ---------- path : liste de state_keys La séquence d'états visités de la racine à la feuille. outcome : int Résultat final du point de vue de X : +1, -1, ou 0. Pour chaque nœud sur le chemin : - Nous convertissons 'outcome' à la perspective du joueur de ce nœud : reward = outcome si player == "X" = -outcome si player == "O" - Puis mettre à jour : node.N += 1 node.W += reward """for state_key in path: node =self.tree[state_key] player = node["player"]# Convertir le résultat de la perspective de X à la perspective de ce nœud.if player =="X": reward = outcomeelse: reward =-outcome node["N"] +=1 node["W"] += reward
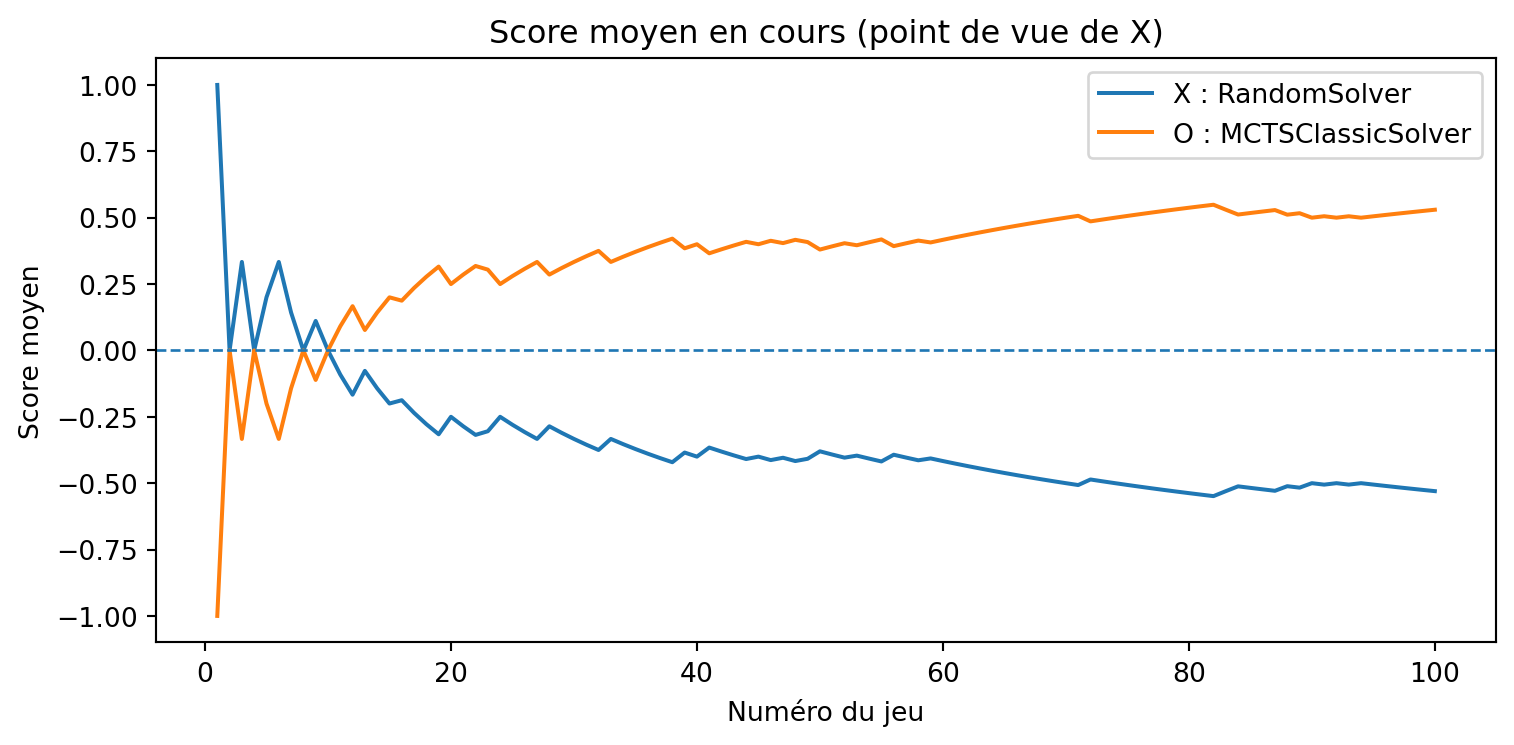
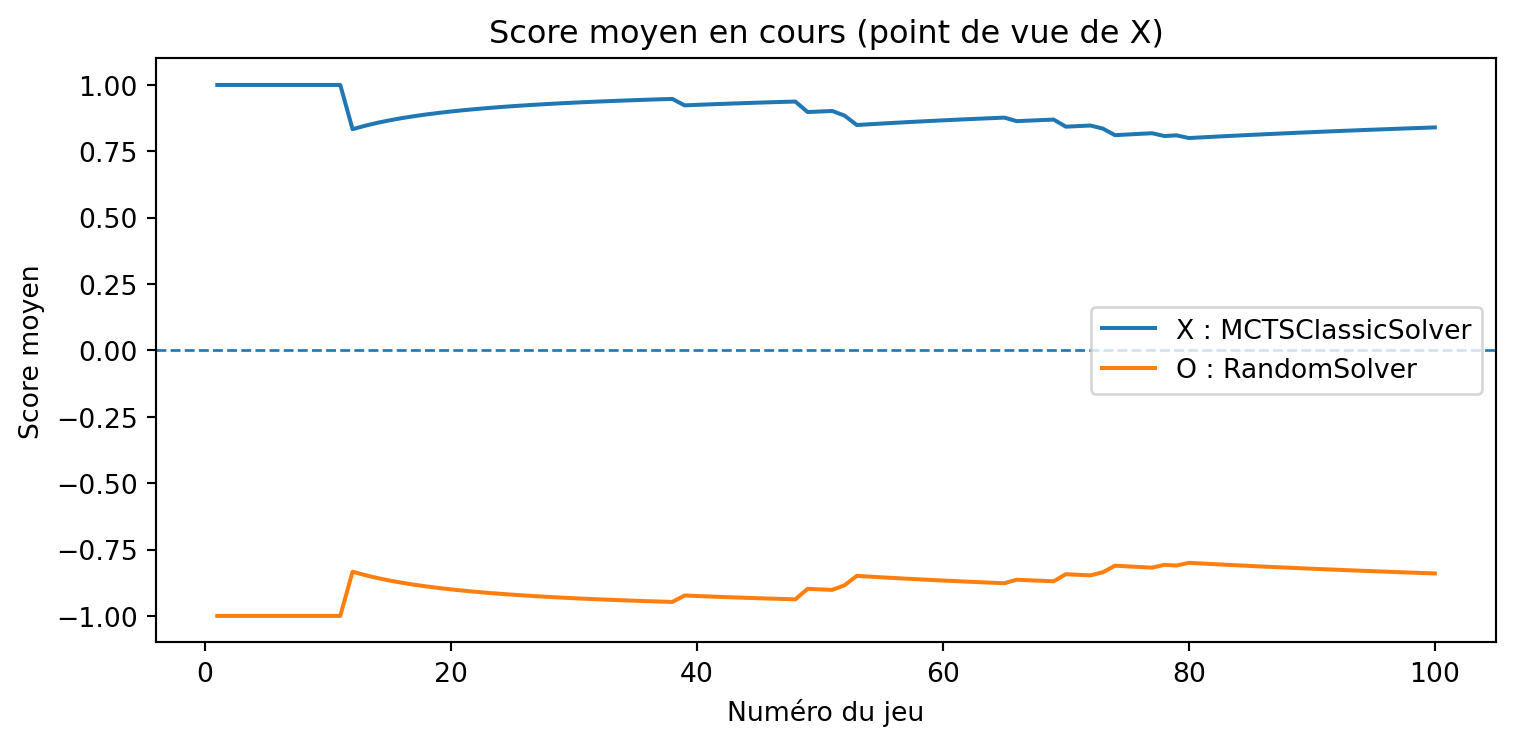
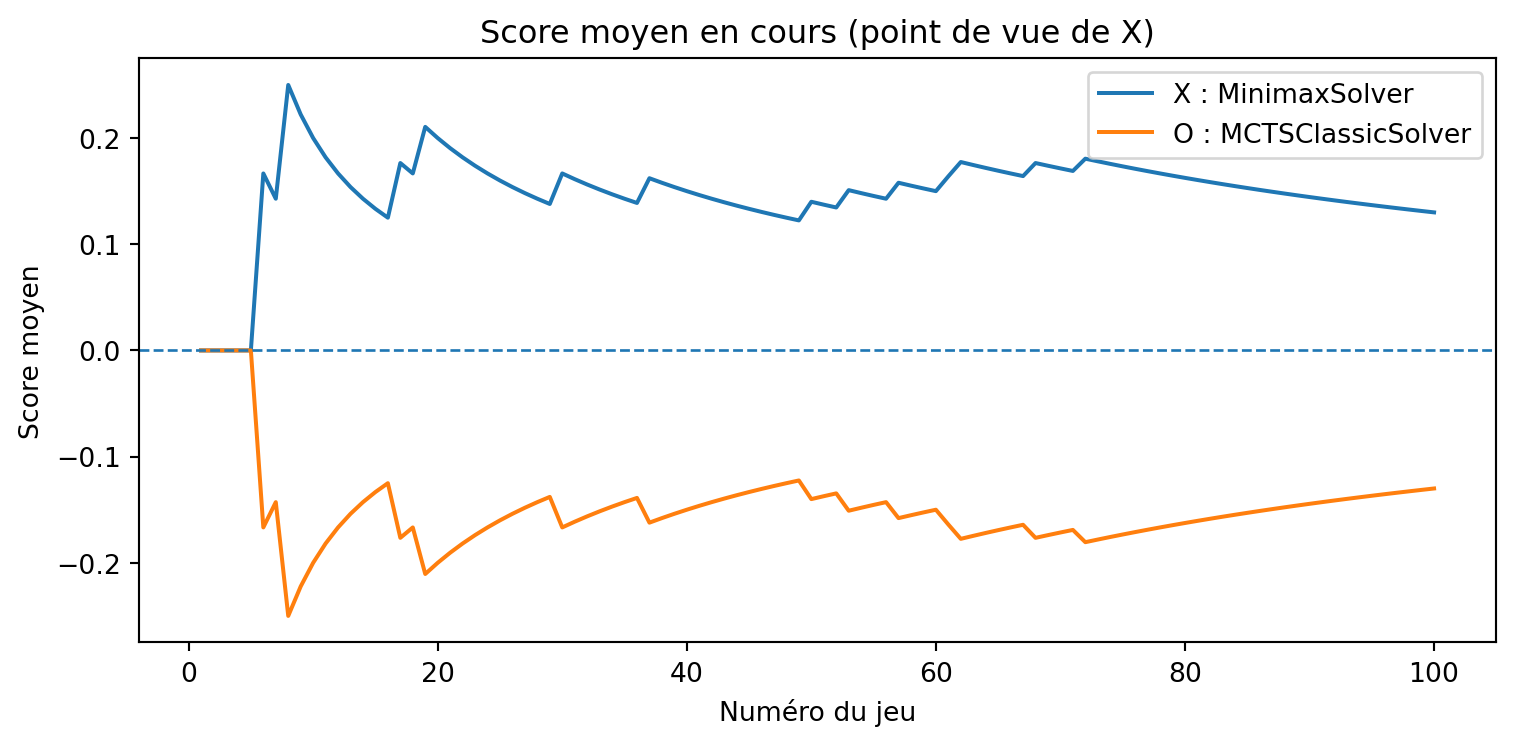
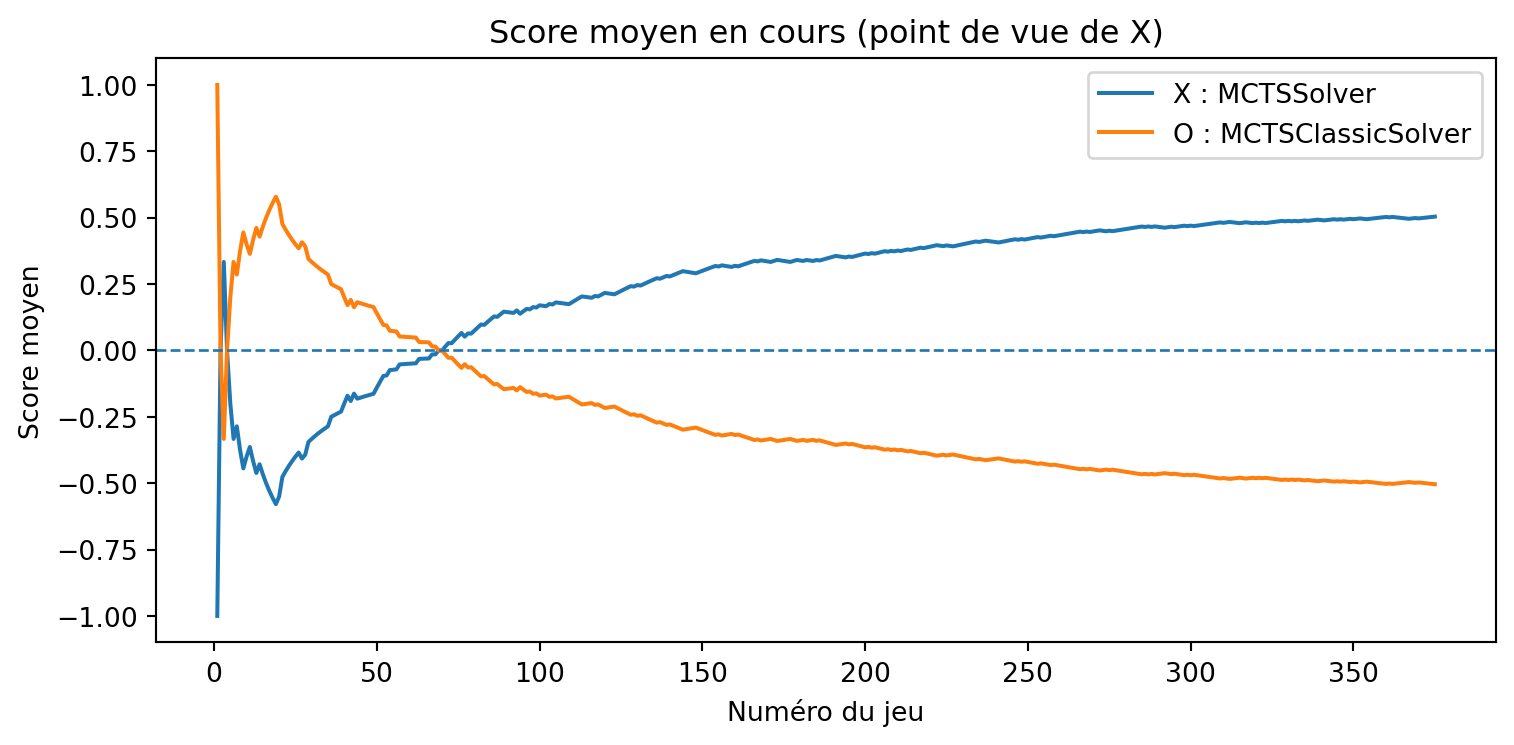
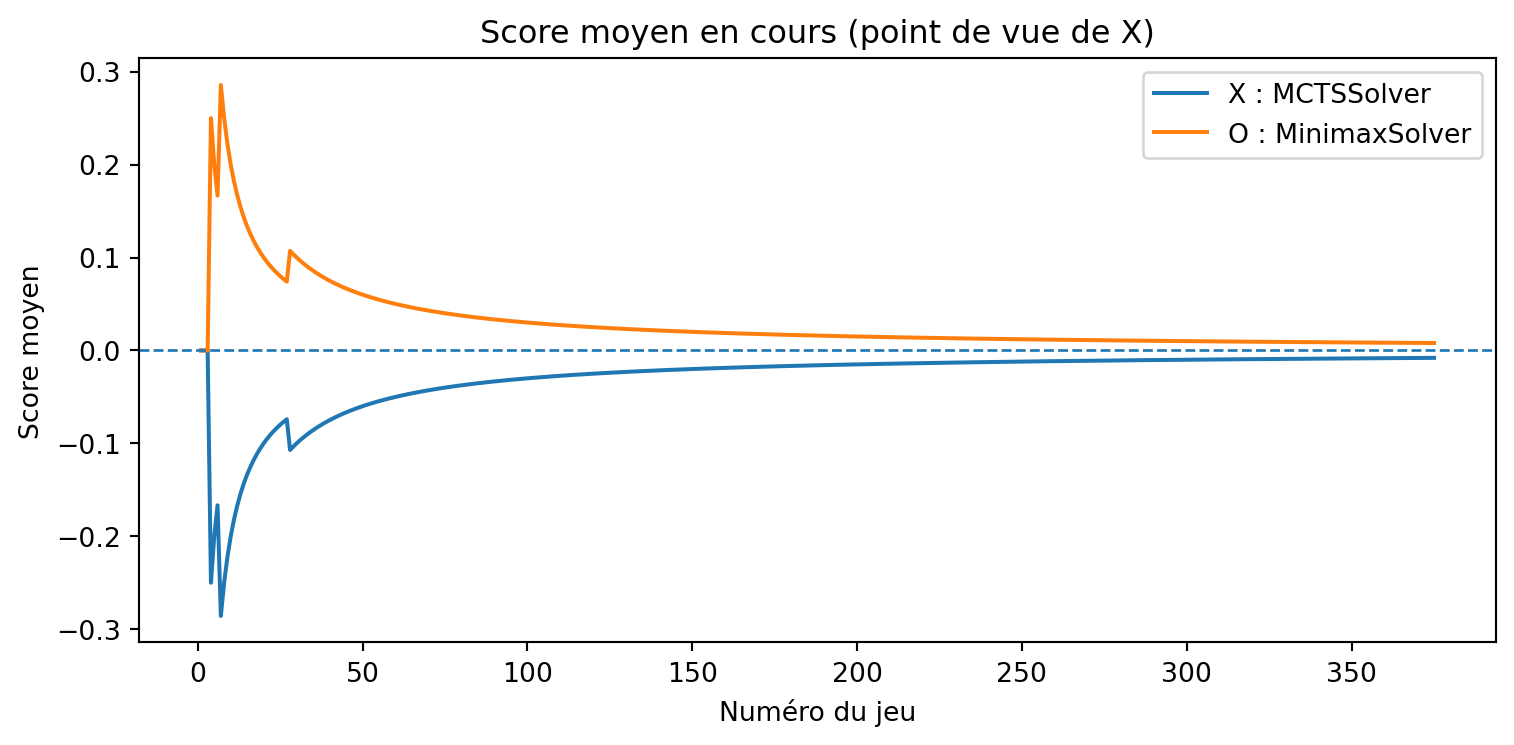
a = MCTSSolver(num_simulations=10, seed=3)b = MCTSClassicSolver(num_simulations=40, seed=4)results, _, _ = evaluate_solvers_with_plot(game, a, b, num_games=375)results
Apprenant vs Penseur
{'X_wins': 207, 'O_wins': 18, 'draws': 150}
Apprenant vs Minimax
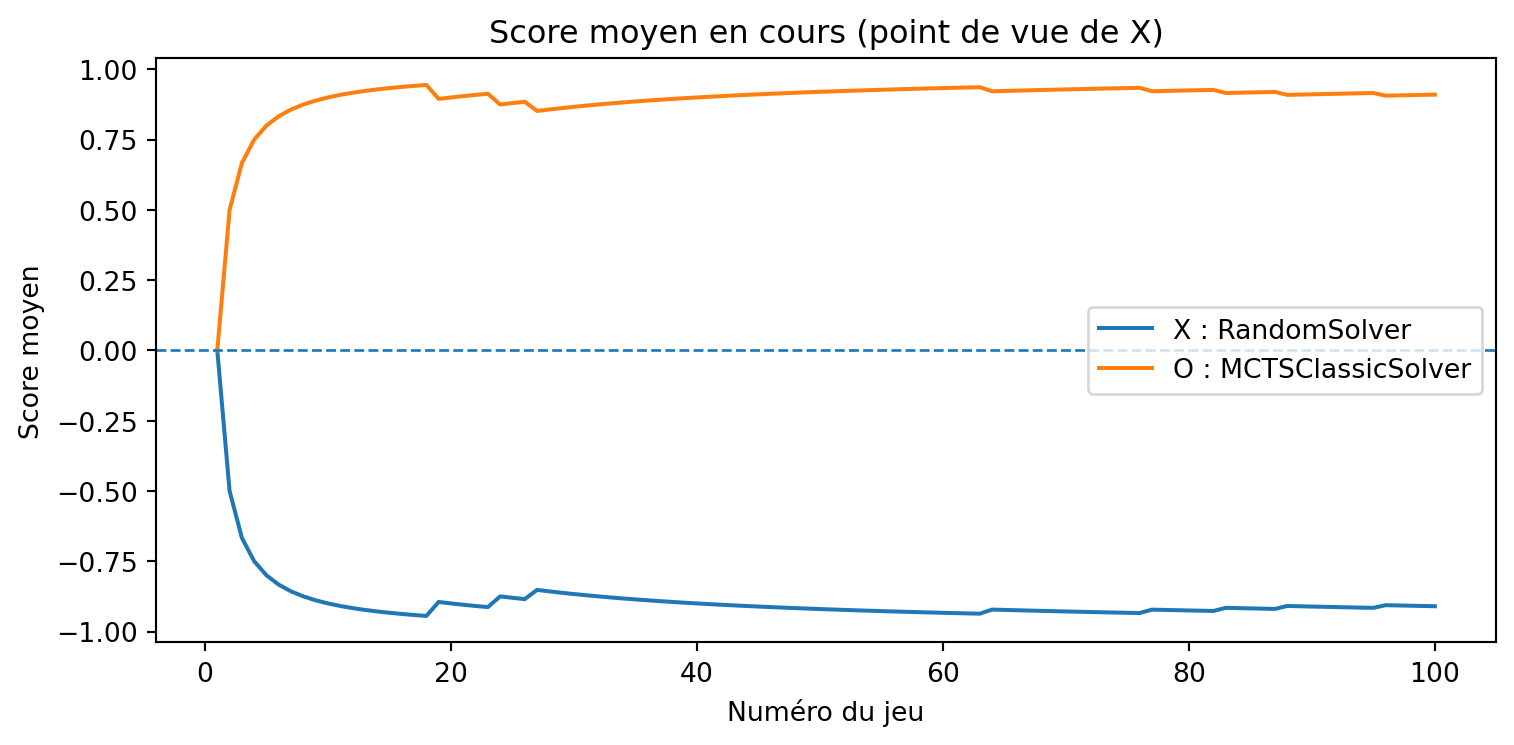
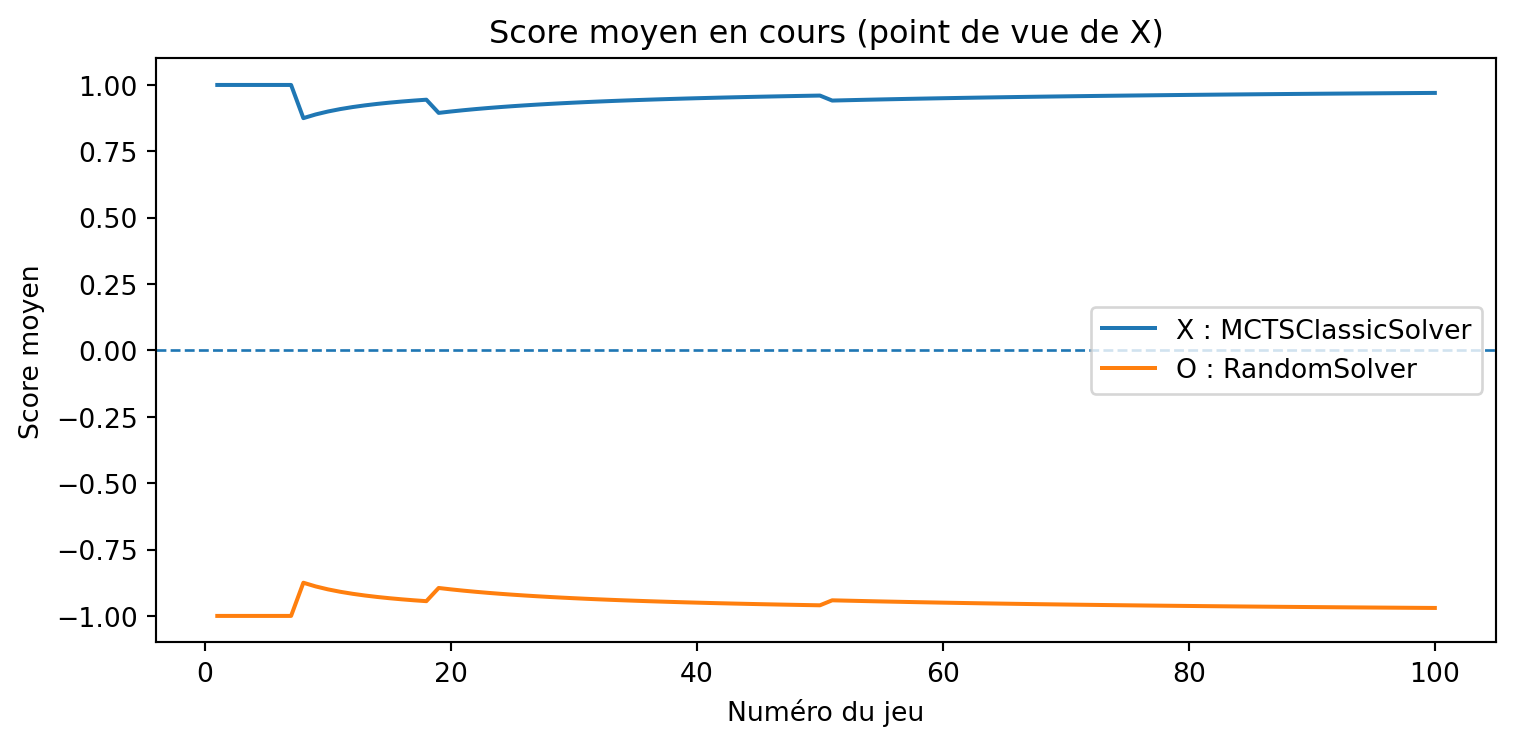
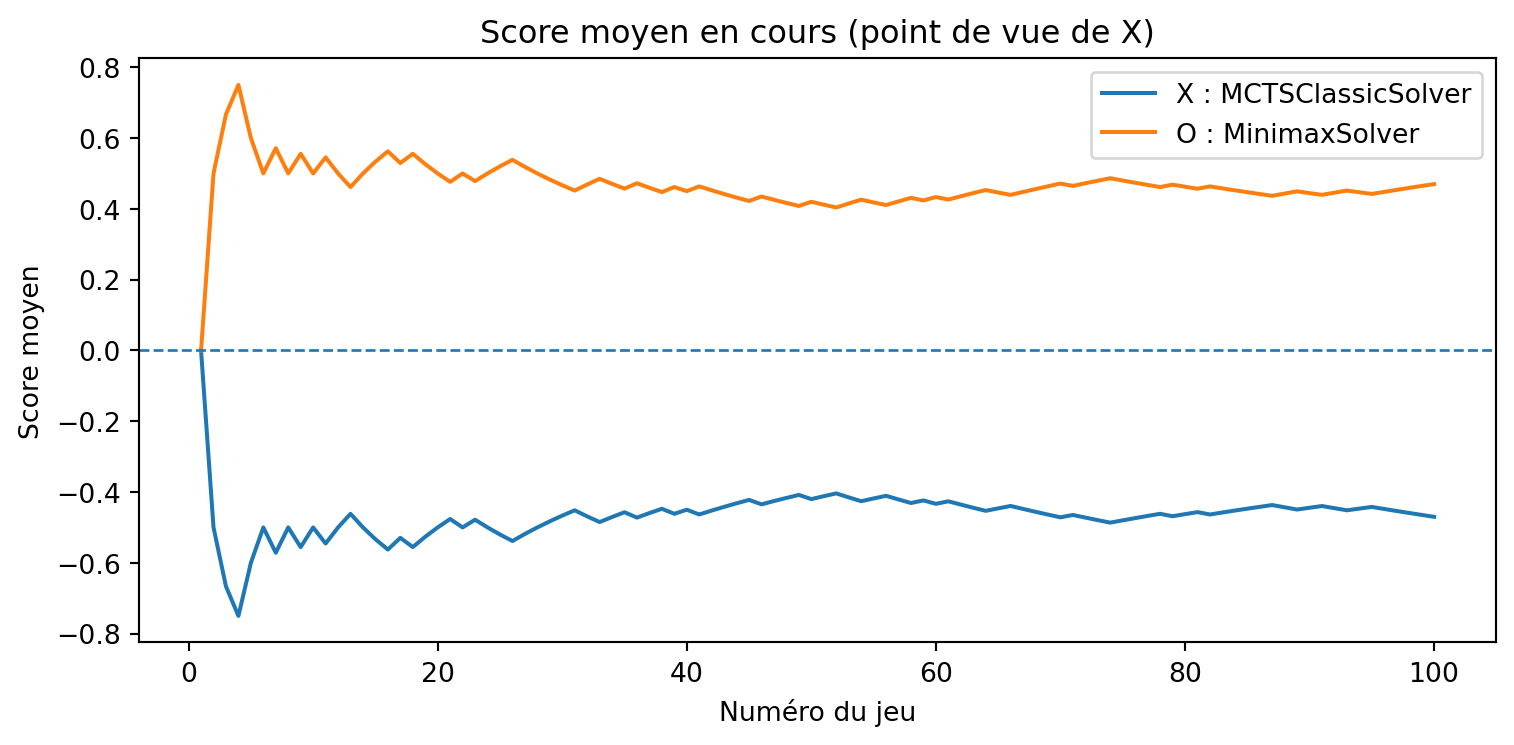
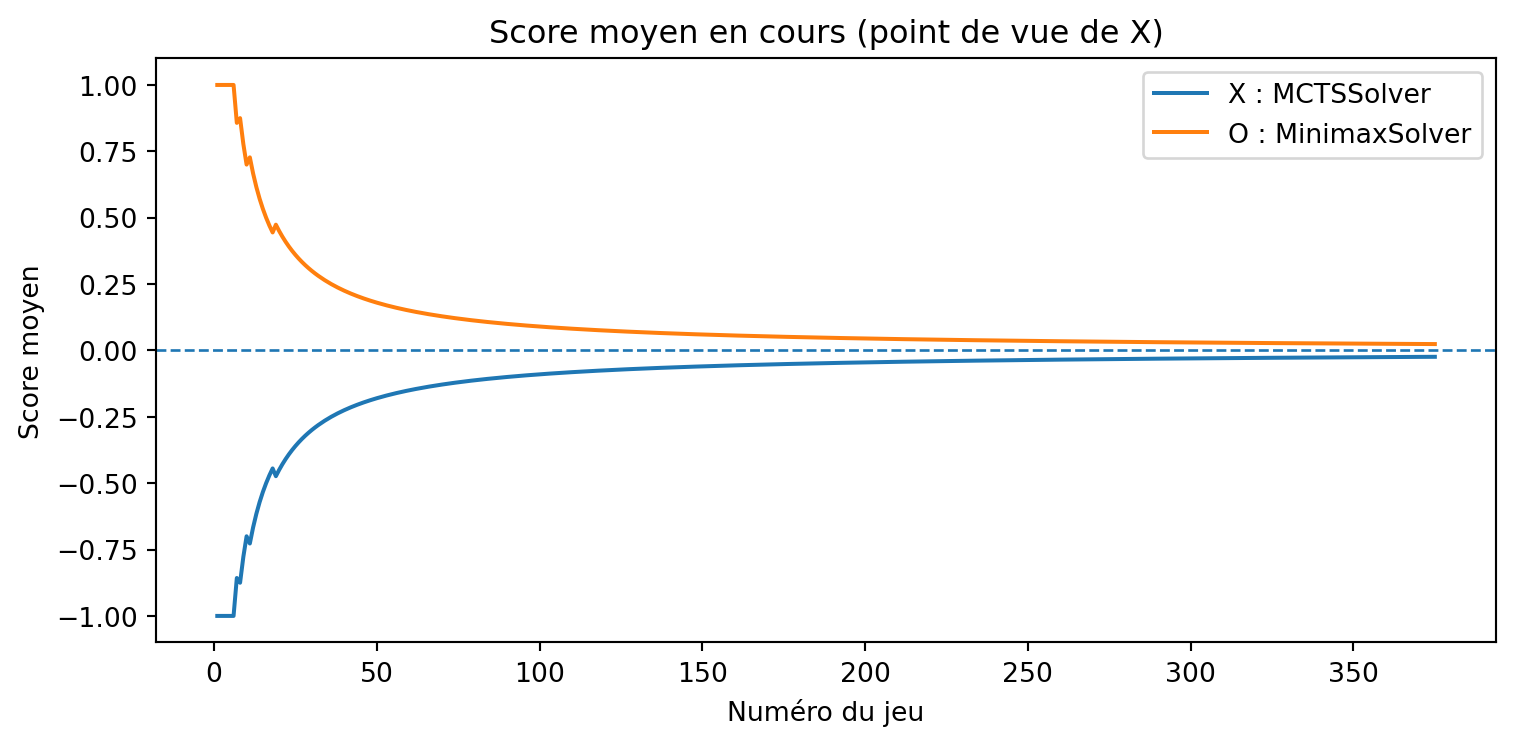
a = MCTSSolver(num_simulations=10, seed=3)b = MinimaxSolver()results, _, _ = evaluate_solvers_with_plot(game, a, b, num_games=375)results
Apprenant vs Minimax
{'X_wins': 0, 'O_wins': 9, 'draws': 366}
Apprenant vs Minimax
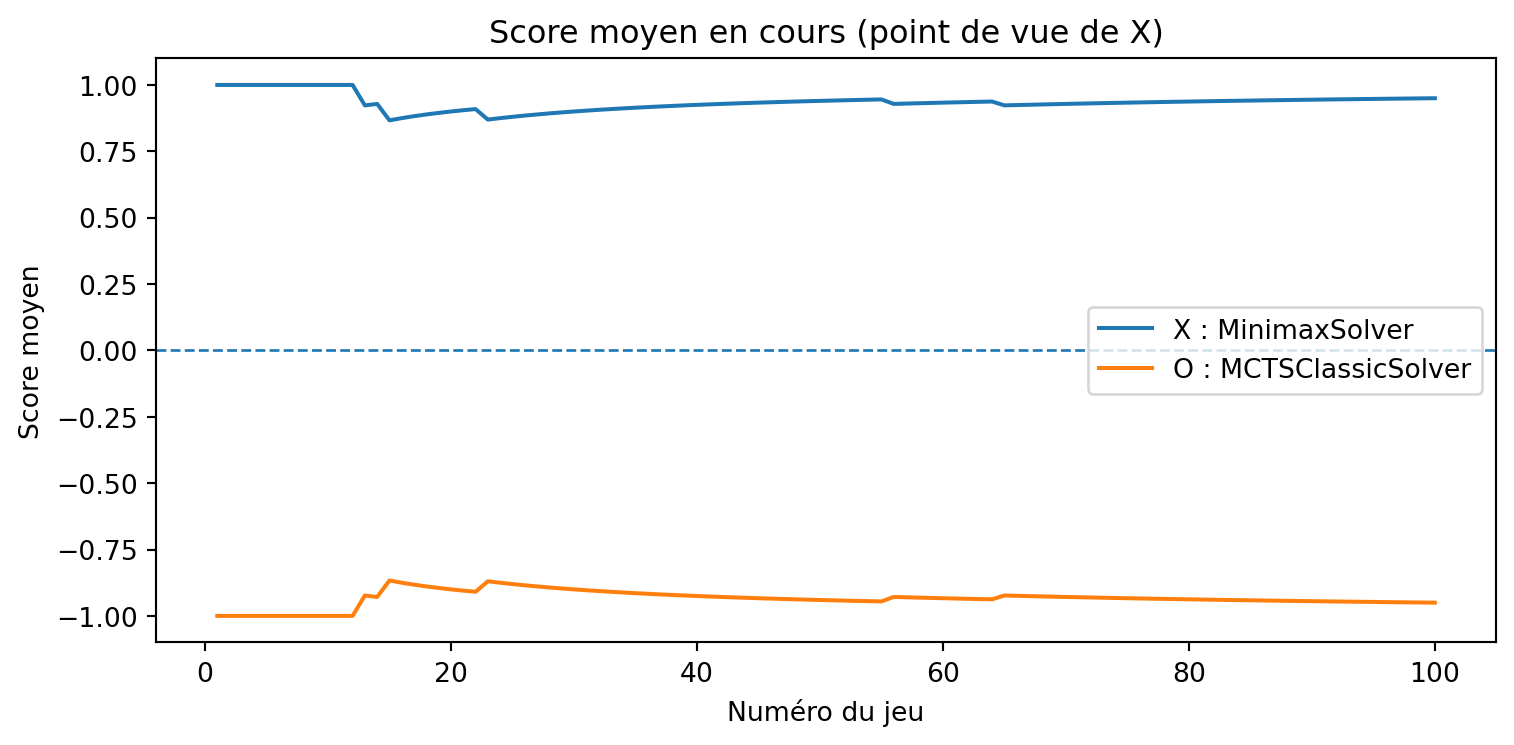
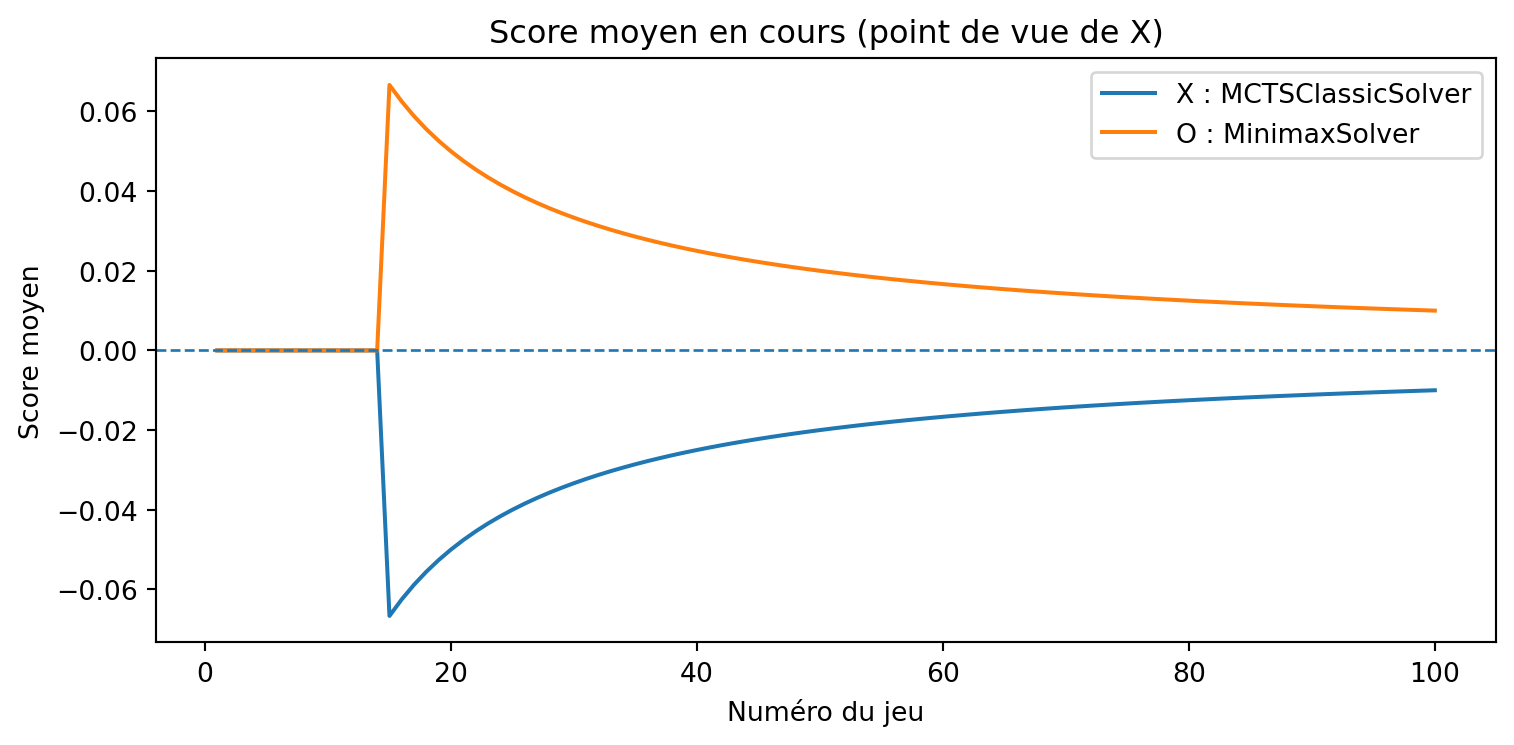
a = MCTSSolver(num_simulations=20, seed=3)b = MinimaxSolver()results, _, _ = evaluate_solvers_with_plot(game, a, b, num_games=375)results
Apprenant vs Minimax
{'X_wins': 0, 'O_wins': 3, 'draws': 372}
Apprenant vs Minimax
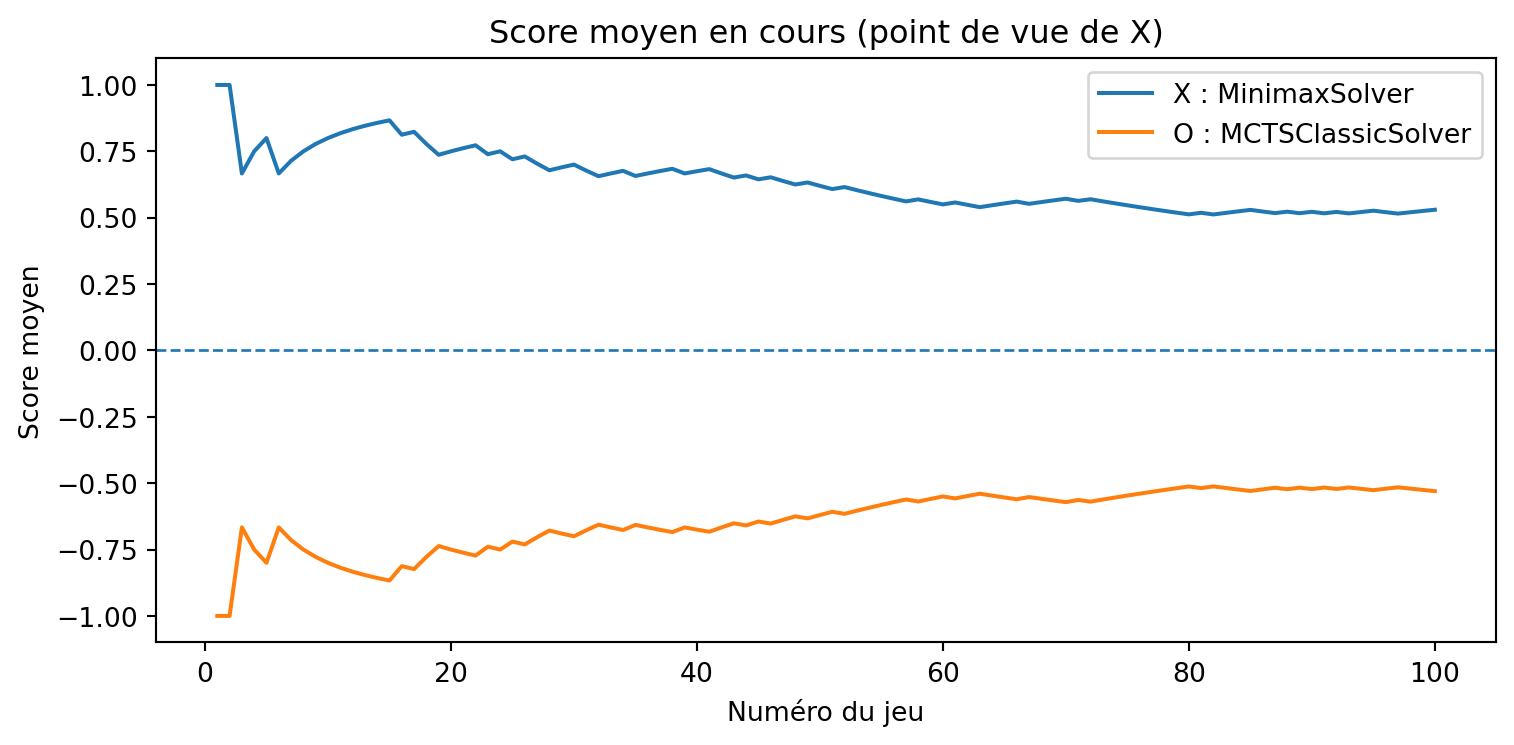
a = MCTSSolver(num_simulations=50, seed=3)b = MinimaxSolver()results, _, _ = evaluate_solvers_with_plot(game, a, b, num_games=375)results
Apprenant vs Minimax
{'X_wins': 0, 'O_wins': 0, 'draws': 375}
Exploration
Incorporer des heuristiques pour détecter quand un coup gagnant est réalisable en un seul mouvement.
Expérimenter avec la variation du nombre d’itérations et de la constante\(C\).
Recherche arborescente de Monte Carlo
Où nous en sommes maintenant : MCTS simple
Nous savons déjà :
Un arbre de recherche des positions du Tic-Tac-Toe
Les nœuds stockent :
Le nombre de visites
Le résultat moyen des parties depuis cette position
MCTS utilise cet arbre pour choisir les mouvements
Recherche arborescente de Monte Carlo
Dans notre code actuel :
Sélection : suivre l’arbre (UCT) vers les nœuds prometteurs
Expansion : ajouter un nouveau nœud enfant
Simulation : jouer des mouvements aléatoires jusqu’à la fin de la partie
Rétropropagation : renvoyer le résultat final dans l’arbre
Recherche arborescente de Monte Carlo
Cela fonctionne très bien pour le Tic-Tac-Toe, mais :
Les simulations aléatoires peuvent être lentes et bruyantes dans des jeux plus grands
L’arbre ne “sait” rien avant que la recherche ne commence
Ajouter un réseau de politique
Objectif : donner à MCTS une meilleure idée des mouvements à explorer en premier.
Nouveau composant : réseau de politique
Entrée : une position sur le plateau
Sortie : une probabilité pour chaque mouvement légal
“Dans cette position, le mouvement A semble à 40 %, le mouvement B à 30 %, le mouvement C à 10 %, …”
Ajouter un réseau de politique
Utilisation dans MCTS :
Dans un nouveau nœud (lorsque nous développons un état) :
Appeler le réseau de politique sur le plateau
Stocker les probabilités de mouvements comme priors pour ce nœud
Pendant la sélection :
MCTS utilise toujours les comptes de visites de l’arbre
Mais maintenant, il utilise aussi les priors de politique pour préférer les mouvements qui semblent bons selon le réseau
Ajouter un réseau de valeur
Objectif : éviter les longues simulations aléatoires et obtenir une estimation directe de la qualité d’une position.
Nouveau composant : réseau de valeur
Entrée : une position sur le plateau
Sortie : un seul nombre :
Proche de +1 si X est susceptible de gagner
Proche de -1 si O est susceptible de gagner
Environ 0 pour un match nul probable
Ajouter un réseau de valeur
Utilisation dans MCTS :
À un nœud feuille (frontière de l’arbre) :
Au lieu de faire une simulation aléatoire :
Appeler le réseau de valeur sur le plateau
Utiliser sa sortie comme valeur de la feuille
Rétropropager cette valeur dans l’arbre
AlphaTicTacToe
Assembler le tout (style AlphaGo “AlphaTicTacToe”) :
MCTS + réseau de politique :
Guide les mouvements à explorer
MCTS + réseau de valeur :
Évalue les positions sans simulations aléatoires
Au fil du temps, les deux réseaux peuvent être entraînés à partir de parties d’exemples (par exemple, auto-jeu) :
Le réseau de politique apprend les “bons mouvements”
Le réseau de valeur apprend les “bonnes positions”
Prologue
Logique et apprentissage
Le dernier devoir
Transformer l’économie canadienne avec l’IA
Rédigez une proposition de 1 à 2 pages sur un domaine économiquement pertinent et répondez aux questions suivantes :
Quel(s) algorithme(s) du cours CSI 4506 est/sont approprié(s) ? Pourquoi ?
Qu’est-ce qui rend le problème computationalement difficile ?
Quelles données seraient nécessaires ?
Comment évalueriez-vous le succès ?
Résumé
La recherche arborescente de Monte Carlo (MCTS) est un algorithme de recherche utilisé pour la prise de décision dans des jeux complexes.
MCTS fonctionne en quatre étapes principales : Sélection, Expansion, Déroulement (Simulation) et Rétropropagation.
Il équilibre exploration et exploitation en utilisant la formule UCB1, qui guide la sélection des nœuds en fonction du nombre de visites et des scores.
MCTS maintient un arbre de recherche explicite, mettant à jour les valeurs des nœuds de manière itérative en fonction des simulations.
L’algorithme a des applications variées, y compris dans les jeux d’IA, la conception de médicaments, le routage de circuits et la conduite autonome.
Introduit en 2008, MCTS a gagné en importance grâce à son utilisation dans AlphaGo en 2016.
Contrairement aux algorithmes traditionnels comme \(A^\star\), MCTS utilise des politiques dynamiques et exploite tous les nœuds visités pour la prise de décision.
Mettre en œuvre MCTS implique de suivre les statistiques des nœuds et d’appliquer la formule UCB1 pour guider la recherche.
Un exemple pratique de MCTS est démontré à travers l’implémentation du Tic-Tac-Toe.
Une exploration plus approfondie inclut l’intégration de MCTS avec des modèles d’apprentissage profond comme AlphaZero et MuZero.
Consultez le site web du cours pour obtenir des informations sur l’examen final.
Références
Besta, Maciej, Julia Barth, Eric Schreiber, Ales Kubicek, Afonso Catarino, Robert Gerstenberger, Piotr Nyczyk, et al. 2025. « Reasoning Language Models: A Blueprint ». https://arxiv.org/abs/2501.11223.
Chaslot, Guillaume, Sander Bakkes, Istvan Szita, et Pieter Spronck. 2008. « Monte-Carlo Tree Search: a new framework for game AI ». In Proceedings of the Fourth AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, 216‑17. AIIDE’08. Stanford, California: AAAI Press.
Kemmerling, Marco, Daniel Lütticke, et Robert H. Schmitt. 2024. « Beyond games: a systematic review of neural Monte Carlo tree search applications ». Applied Intelligence 54 (1): 1020‑46. https://doi.org/10.1007/s10489-023-05240-w.
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.
Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, et al. 2016. « Mastering the game of Go with deep neural networks and tree search ». Nature 529 (7587): 484‑89. https://doi.org/10.1038/nature16961.
Annexe
Intégration numérique
Code
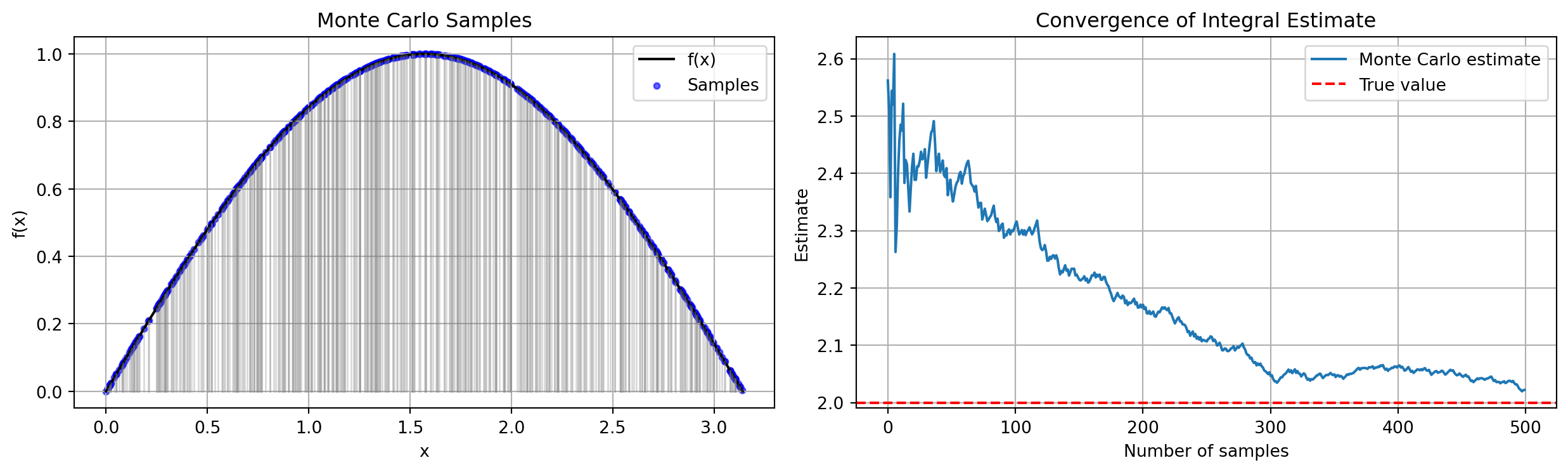
import randomimport mathimport numpy as npimport matplotlib.pyplot as pltdef monte_carlo_integrate_visual_with_sticks(f, a, b, n_samples, seed=None):""" Monte Carlo integration visualization. Shows the function curve, sampled points, and vertical lines ("sticks"). Also plots convergence of the Monte Carlo estimate. """if seed isnotNone: np.random.seed(seed) xs = np.random.uniform(a, b, size=n_samples) ys = f(xs) cumulative_avg = np.cumsum(ys) / np.arange(1, n_samples +1) estimates = (b - a) * cumulative_avg fig, ax = plt.subplots(1, 2, figsize=(13, 4))# ----- Left panel: samples + vertical lines ----- X = np.linspace(a, b, 400) ax[0].plot(X, f(X), color="black", label="f(x)")# Vertical linesfor x_i, y_i inzip(xs, ys): ax[0].plot([x_i, x_i], [0, y_i], color="gray", alpha=0.3, linewidth=1)# Sampled points ax[0].scatter(xs, ys, s=12, color="blue", alpha=0.6, label="Samples") ax[0].set_title("Monte Carlo Samples") ax[0].set_xlabel("x") ax[0].set_ylabel("f(x)") ax[0].grid(True) ax[0].legend()# ----- Right panel: convergence ----- true_value =2.0# ∫₀^π sin(x) dx ax[1].plot(estimates, label="Monte Carlo estimate") ax[1].axhline(true_value, linestyle="--", color="red", label="True value") ax[1].set_title("Convergence of Integral Estimate") ax[1].set_xlabel("Number of samples") ax[1].set_ylabel("Estimate") ax[1].grid(True) ax[1].legend() plt.tight_layout() plt.show()return estimates[-1]def main(): f = np.sin a, b =0.0, math.pi n_samples =500 estimate = monte_carlo_integrate_visual_with_sticks(f, a, b, n_samples, seed=123)print(f"Final estimate ≈ {estimate:.6f} (true = 2.0)")main()
Final estimate ≈ 2.022106 (true = 2.0)
Intégration numérique
Code
def monte_carlo_integrate(f, a, b, n_samples, seed=None):""" Estimate ∫_a^b f(x) dx using simple Monte Carlo integration. Parameters ---------- f : callable Function to integrate. a, b : float Integration bounds (a < b). n_samples : int Number of random samples to draw. seed : int or None Optional seed for reproducibility. Returns ------- estimate : float Monte Carlo estimate of the integral. """if seed isnotNone: random.seed(seed) total =0.0for _ inrange(n_samples): x = random.uniform(a, b) total += f(x)return (b - a) * total / n_samplesdef main():# Example: integrate f(x) = sin(x) on [0, π] f = math.sin a, b =0.0, math.pifor n in [100, 1_000, 10_000, 100_000]: estimate = monte_carlo_integrate(f, a, b, n, seed=0)print(f"n = {n:6d} → estimate ≈ {estimate:.6f} (delta = {abs(2.0- estimate):.6f})")main()
n = 100 → estimate ≈ 2.080957 (delta = 0.080957)
n = 1000 → estimate ≈ 1.992136 (delta = 0.007864)
n = 10000 → estimate ≈ 2.007041 (delta = 0.007041)
n = 100000 → estimate ≈ 1.996149 (delta = 0.003851)