Code
CSI 5180 - Machine Learning for Bioinformatics
Version: Feb 19, 2025 13:30
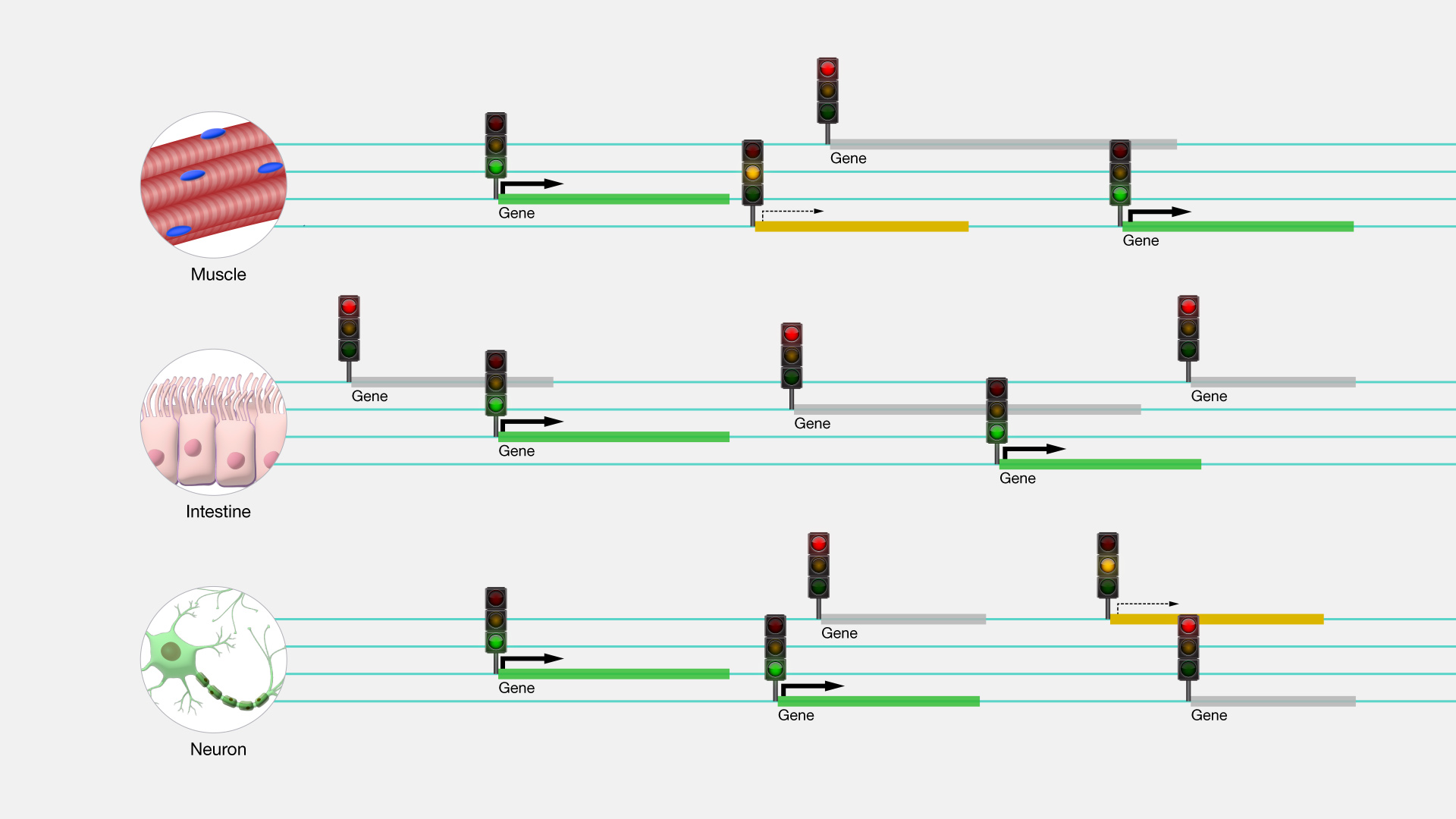
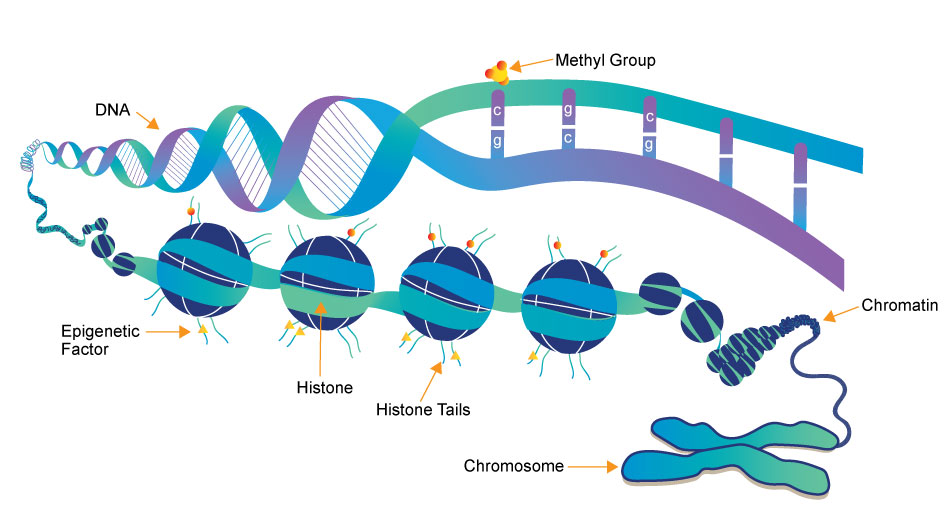
Gene regulation at the National Human Genome Research Institute
Gene regulation is the process used to control the timing, location and amount in which genes are expressed.

\(y_i\) is the expression level of gene \(i\).
\(x_i = \{x_{i1},\ldots,x_{iP}\}\) is a vector with \(P\) regulatory signals for gene \(i\).
where \(i=1,\ldots,N\).
The learned coefficients identify whether a signal functions as an activator (positive), a repressor (negative), or is irrelevant (zero).
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
# Define the variable and function
t = sp.symbols('t')
f = t**2 + 4*t + 7
# Compute the derivative
f_prime = sp.diff(f, t)
# Lambdify the functions for numerical plotting
f_func = sp.lambdify(t, f, "numpy")
f_prime_func = sp.lambdify(t, f_prime, "numpy")
# Generate t values for plotting
t_vals = np.linspace(-5, 2, 400)
# Get y values for the function and its derivative
f_vals = f_func(t_vals)
f_prime_vals = f_prime_func(t_vals)
# Plot the function and its derivative
plt.plot(t_vals, f_vals, label=r'$f(t) = t^2 + 4t + 7$', color='blue')
plt.plot(t_vals, f_prime_vals, label=r"$f'(t) = 2t + 4$", color='red')
# Add labels and legend
plt.axhline(0, color='black',linewidth=1)
plt.axvline(0, color='black',linewidth=1)
plt.title('Function and Derivative')
plt.xlabel('t')
plt.ylabel(r'$f(t)$')
plt.legend()
# Show the plot
plt.grid(True)
plt.show()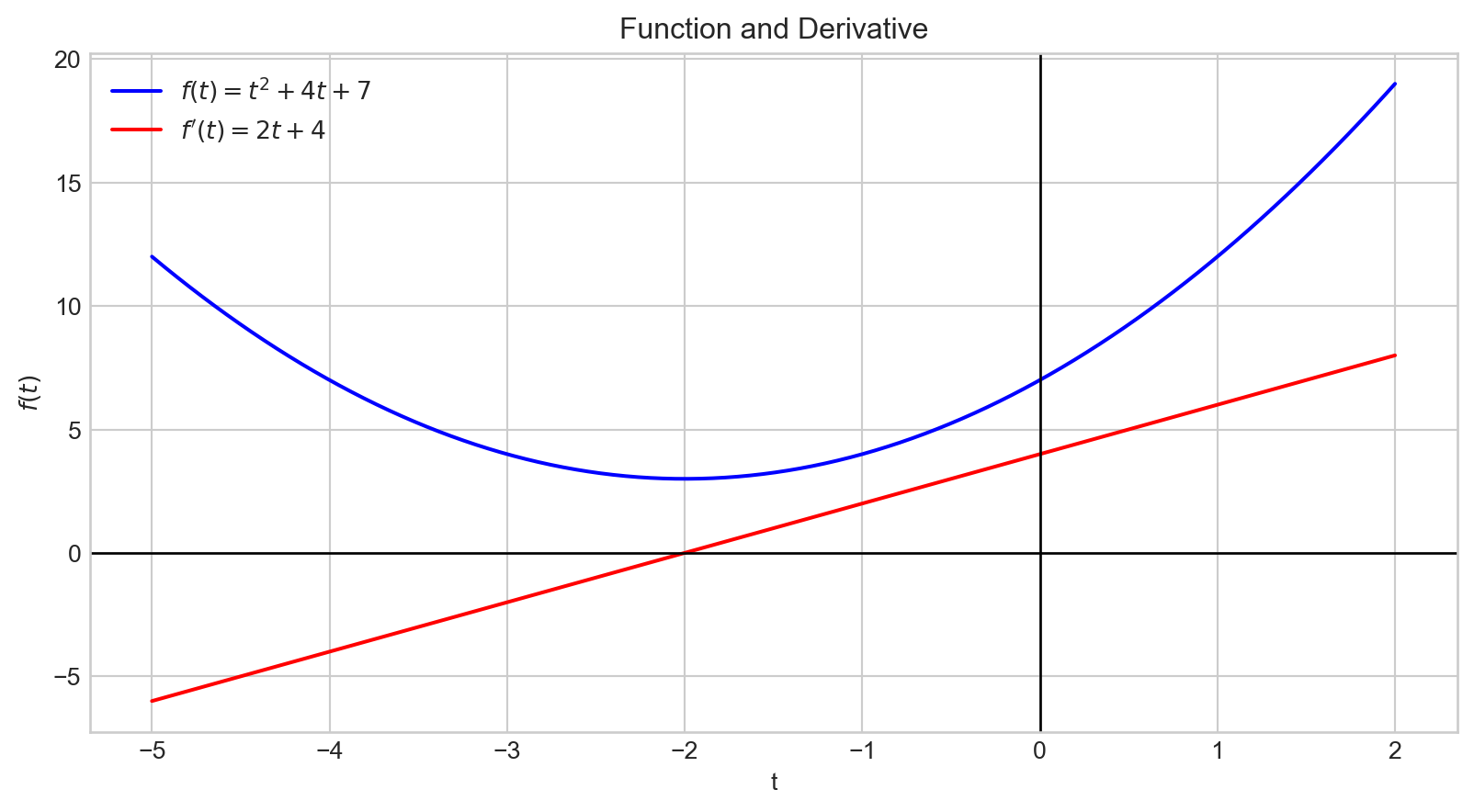
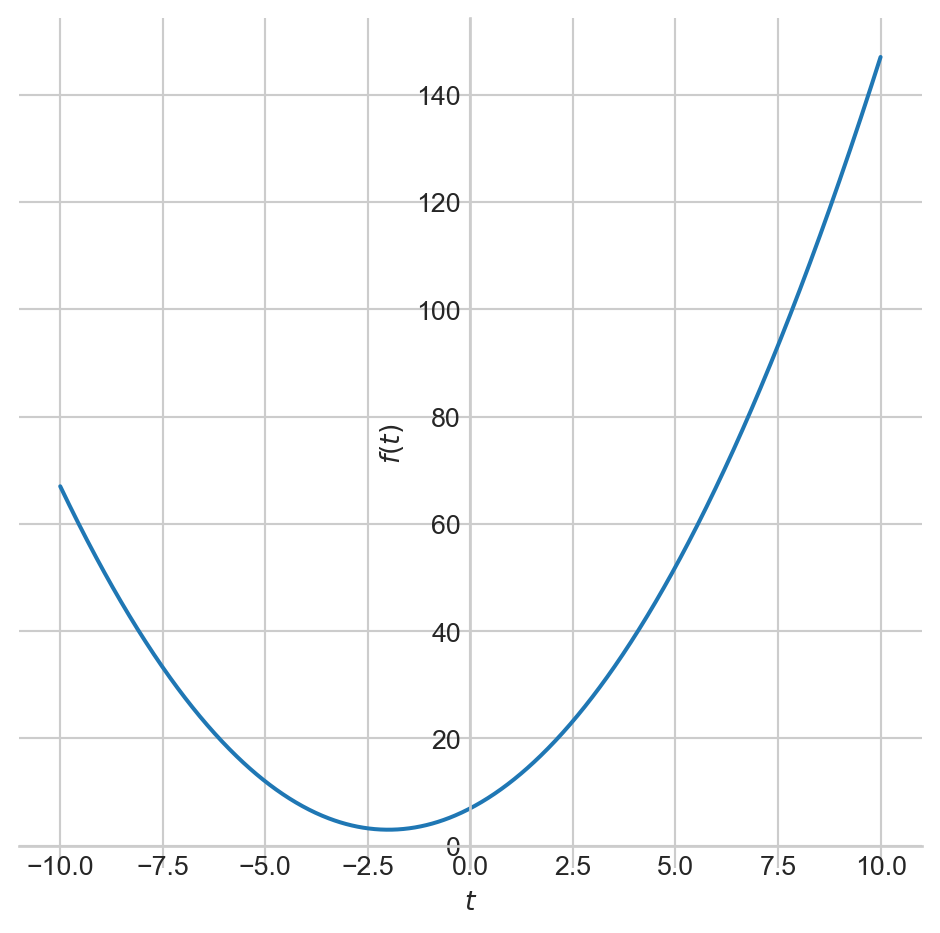
The graph of the derivative, \(f^{'}(t)\), is depicted in red.
The derivative indicates how changes in the input affect the output, \(f(t)\).
The magnitude of the derivative at \(t = -2\) is \(0\).
This point corresponds to the minimum of our function.
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
# Define the variable and function
t = sp.symbols('t')
f = t**2 + 4*t + 7
# Compute the derivative
f_prime = sp.diff(f, t)
# Lambdify the functions for numerical plotting
f_func = sp.lambdify(t, f, "numpy")
f_prime_func = sp.lambdify(t, f_prime, "numpy")
# Generate t values for plotting
t_vals = np.linspace(-5, 2, 400)
# Get y values for the function and its derivative
f_vals = f_func(t_vals)
f_prime_vals = f_prime_func(t_vals)
# Plot the function and its derivative
plt.plot(t_vals, f_vals, label=r'$f(t) = t^2 + 4t + 7$', color='blue')
plt.plot(t_vals, f_prime_vals, label=r"$f'(t) = 2t + 4$", color='red')
# Add labels and legend
plt.axhline(0, color='black',linewidth=1)
plt.axvline(0, color='black',linewidth=1)
plt.title('Function and Derivative')
plt.xlabel('t')
plt.ylabel('y')
plt.legend()
# Show the plot
plt.grid(True)
plt.show()
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
# Define the variable and function
t = sp.symbols('t')
f = t**2 + 4*t + 7
# Compute the derivative
f_prime = sp.diff(f, t)
# Lambdify the functions for numerical plotting
f_func = sp.lambdify(t, f, "numpy")
f_prime_func = sp.lambdify(t, f_prime, "numpy")
# Generate t values for plotting
t_vals = np.linspace(-5, 2, 400)
# Get y values for the function and its derivative
f_vals = f_func(t_vals)
f_prime_vals = f_prime_func(t_vals)
# Plot the function and its derivative
plt.plot(t_vals, f_vals, label=r'$f(t) = t^2 + 4t + 7$', color='blue')
plt.plot(t_vals, f_prime_vals, label=r"$f'(t) = 2t + 4$", color='red')
# Fill the area below the derivative where it's negative
plt.fill_between(t_vals, f_prime_vals, where=(f_prime_vals > 0), color='red', alpha=0.3)
# Add labels and legend
plt.axhline(0, color='black',linewidth=1)
plt.axvline(0, color='black',linewidth=1)
plt.title('Function and Derivative')
plt.xlabel('t')
plt.ylabel('y')
plt.legend()
# Show the plot
plt.grid(True)
plt.show()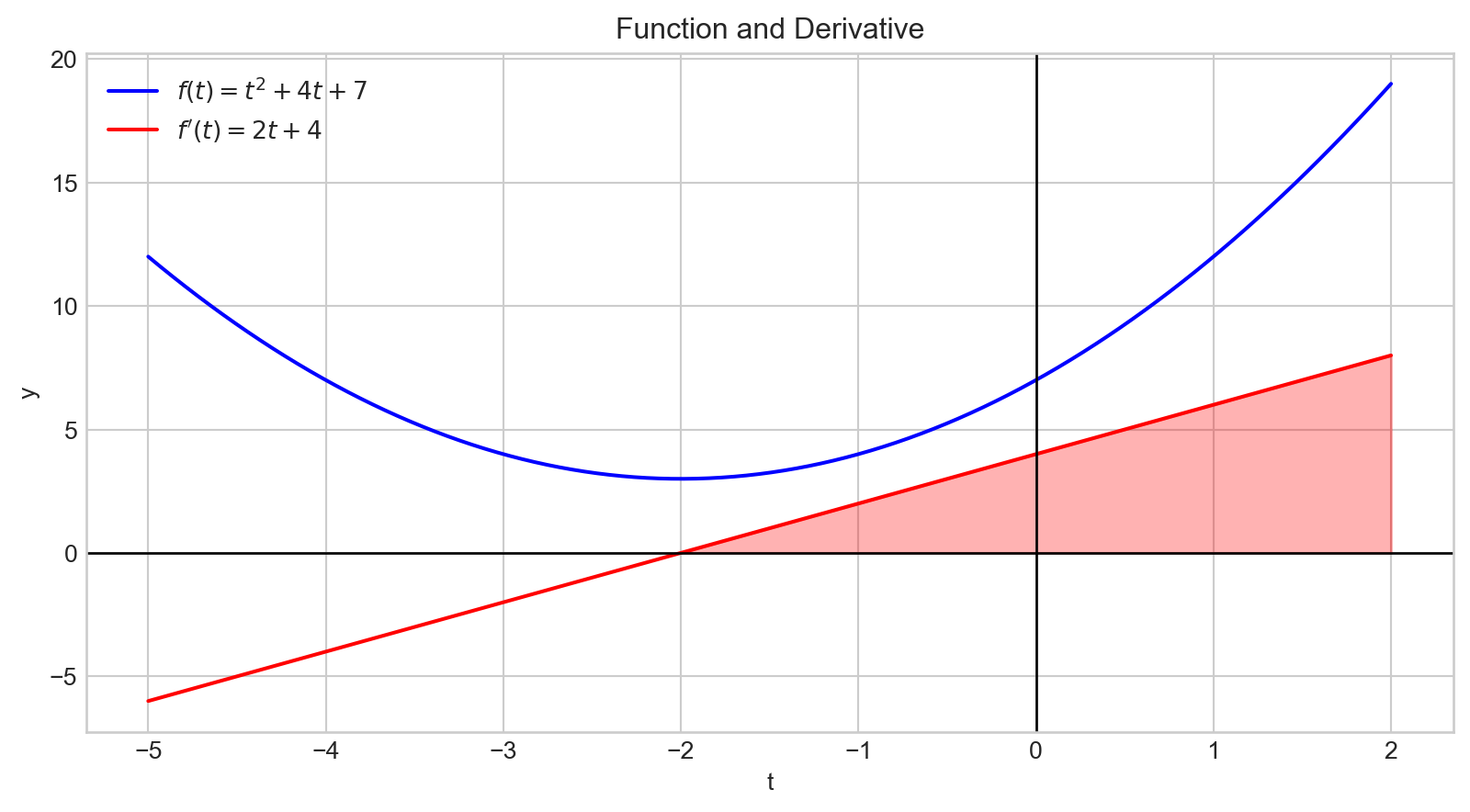
A positive derivative indicates that increasing the input variable will increase the output value.
Additionally, the magnitude of the derivative quantifies how rapidly the output changes.
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
# Define the variable and function
t = sp.symbols('t')
f = t**2 + 4*t + 7
# Compute the derivative
f_prime = sp.diff(f, t)
# Lambdify the functions for numerical plotting
f_func = sp.lambdify(t, f, "numpy")
f_prime_func = sp.lambdify(t, f_prime, "numpy")
# Generate t values for plotting
t_vals = np.linspace(-5, 2, 400)
# Get y values for the function and its derivative
f_vals = f_func(t_vals)
f_prime_vals = f_prime_func(t_vals)
# Plot the function and its derivative
plt.plot(t_vals, f_vals, label=r'$f(t) = t^2 + 4t + 7$', color='blue')
plt.plot(t_vals, f_prime_vals, label=r"$f'(t) = 2t + 4$", color='red')
# Fill the area below the derivative where it's negative
plt.fill_between(t_vals, f_prime_vals, where=(f_prime_vals < 0), color='red', alpha=0.3)
# Add labels and legend
plt.axhline(0, color='black',linewidth=1)
plt.axvline(0, color='black',linewidth=1)
plt.title('Function and Derivative')
plt.xlabel('t')
plt.ylabel('y')
plt.legend()
# Show the plot
plt.grid(True)
plt.show()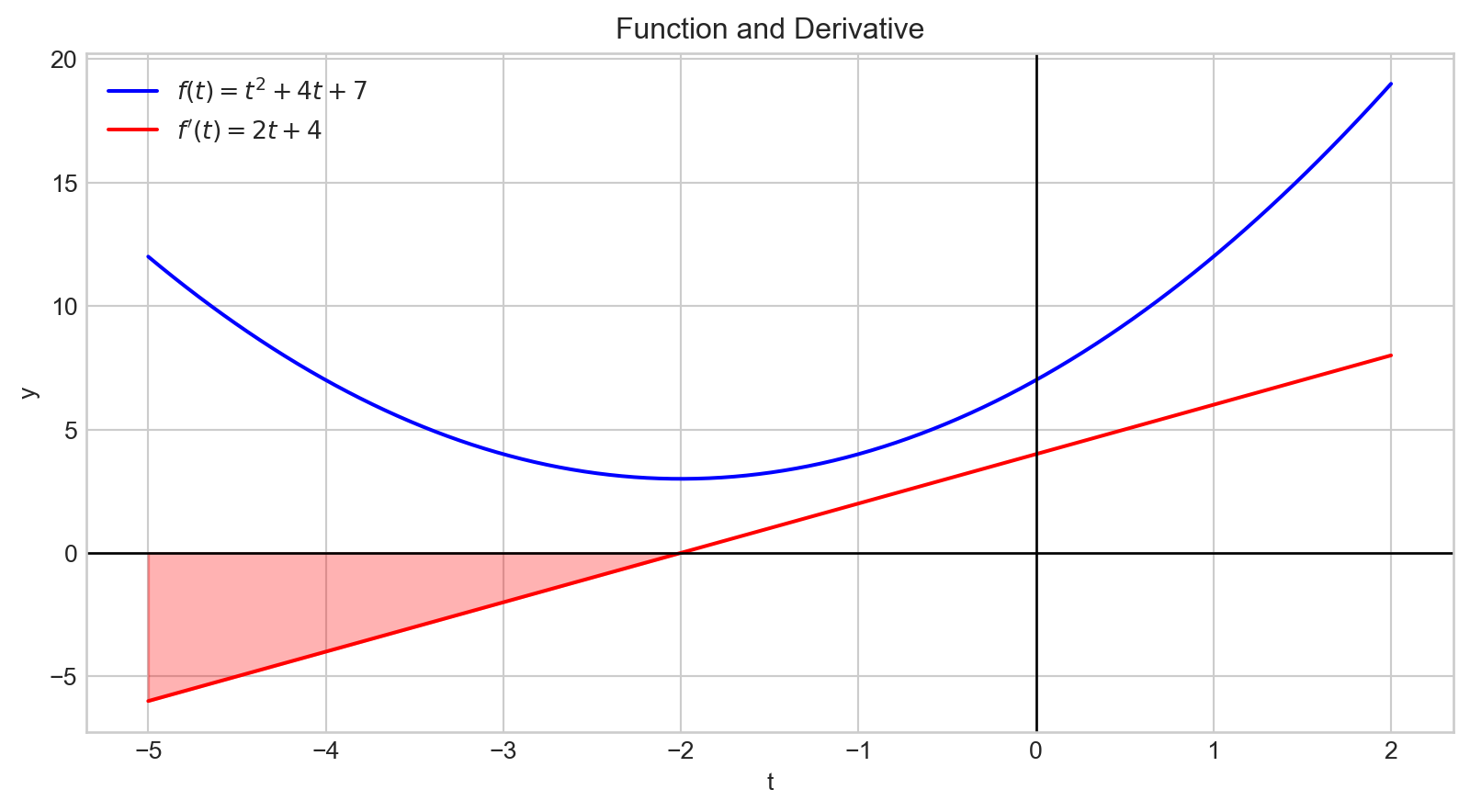
A negative derivative indicates that increasing the input variable will decrease the output value.
Additionally, the magnitude of the derivative quantifies how rapidly the output changes.
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
# Define the variable and function
t = sp.symbols('t')
f = t**2 + 4*t + 7
# Compute the derivative
f_prime = sp.diff(f, t)
# Lambdify the functions for numerical plotting
f_func = sp.lambdify(t, f, "numpy")
f_prime_func = sp.lambdify(t, f_prime, "numpy")
# Generate t values for plotting
t_vals = np.linspace(-5, 2, 400)
# Get y values for the function and its derivative
f_vals = f_func(t_vals)
f_prime_vals = f_prime_func(t_vals)
# Plot the function and its derivative
plt.plot(t_vals, f_vals, label=r'$J$', color='blue')
plt.plot(t_vals, f_prime_vals, label=r"$\frac {\partial}{\partial \theta_j}J(\theta)$", color='red')
# Add labels and legend
plt.axhline(0, color='black',linewidth=1)
plt.axvline(0, color='black',linewidth=1)
plt.title('Function and Derivative')
plt.xlabel(r'$\theta_j$')
plt.ylabel(r'$J$')
plt.legend()
# Show the plot
plt.grid(True)
plt.show()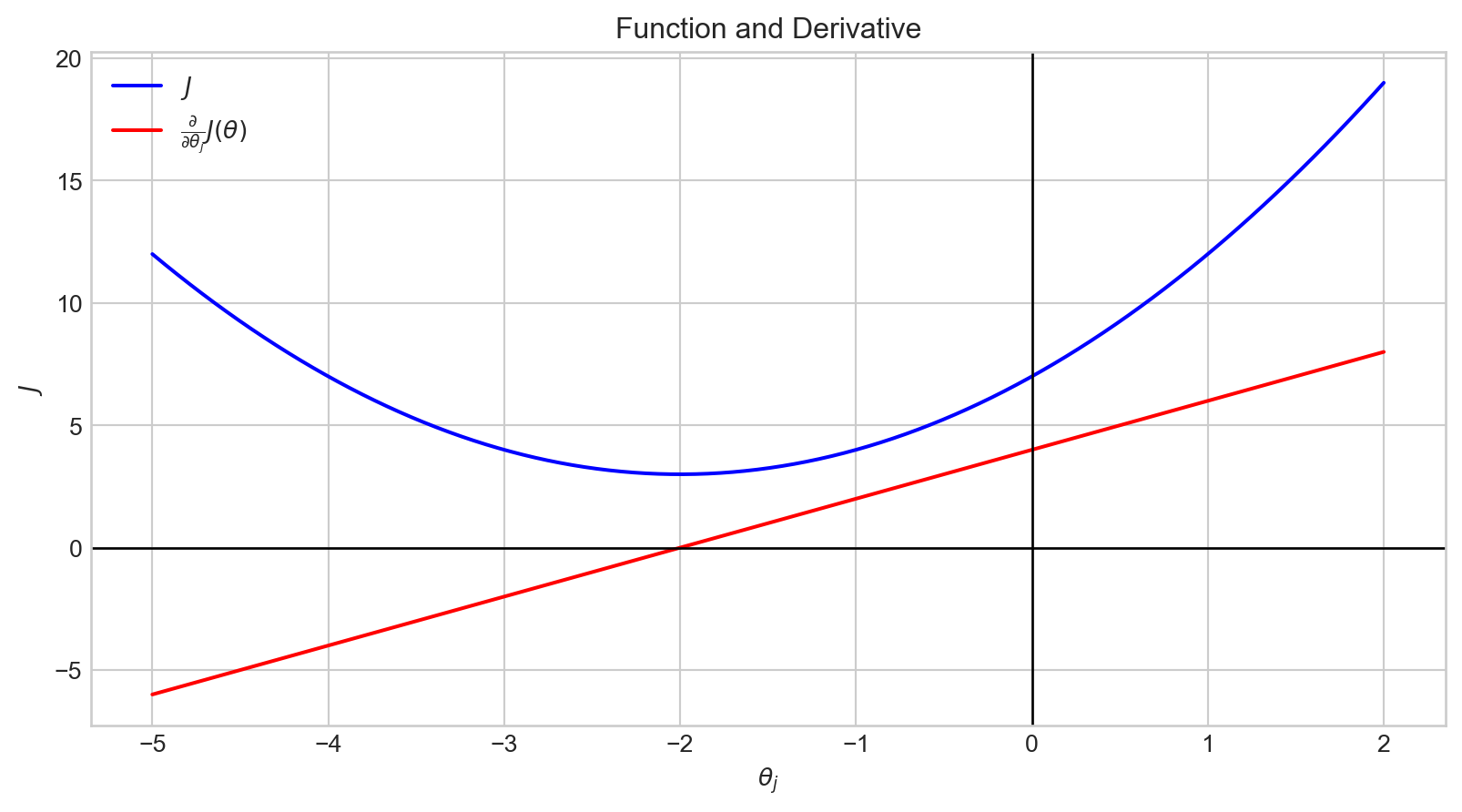
When the value of \(\theta_j\) is in the range \([- \inf, -2)\), \(\frac {\partial}{\partial \theta_j}J(\theta)\) has a negative value.
Therefore, \(- \alpha \frac {\partial}{\partial \theta_j}J(\theta)\) is positive.
Accordingly, the value of \(\theta_j\) is increased.
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
# Define the variable and function
t = sp.symbols('t')
f = t**2 + 4*t + 7
# Compute the derivative
f_prime = sp.diff(f, t)
# Lambdify the functions for numerical plotting
f_func = sp.lambdify(t, f, "numpy")
f_prime_func = sp.lambdify(t, f_prime, "numpy")
# Generate t values for plotting
t_vals = np.linspace(-5, 2, 400)
# Get y values for the function and its derivative
f_vals = f_func(t_vals)
f_prime_vals = f_prime_func(t_vals)
# Plot the function and its derivative
plt.plot(t_vals, f_vals, label=r'$J$', color='blue')
plt.plot(t_vals, f_prime_vals, label=r"$\frac {\partial}{\partial \theta_j}J(\theta)$", color='red')
# Add labels and legend
plt.axhline(0, color='black',linewidth=1)
plt.axvline(0, color='black',linewidth=1)
plt.title('Function and Derivative')
plt.xlabel(r'$\theta_j$')
plt.ylabel(r'$J$')
plt.legend()
# Show the plot
plt.grid(True)
plt.show()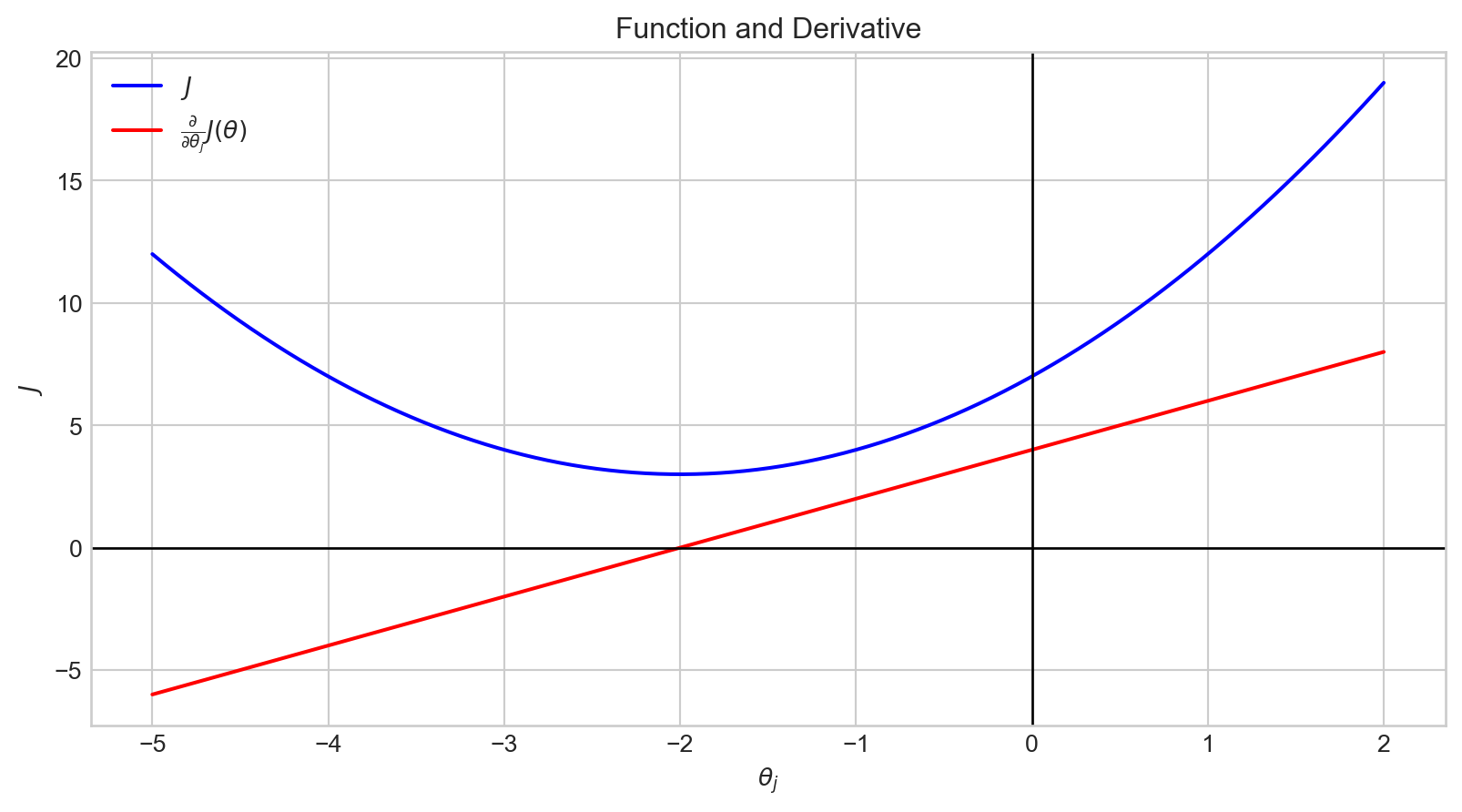
When the value of \(\theta_j\) is in the range \((-2, \infty]\), \(\frac {\partial}{\partial \theta_j}J(\theta)\) has a positive value.
Therefore, \(- \alpha \frac {\partial}{\partial \theta_j}J(\theta)\) is negative.
Accordingly, the value of \(\theta_j\) is decreased.

# 1. Define the symbolic variable and the function
x = sp.Symbol('x', real=True)
f_expr = 2*x**3 + 4*x**2 - 5*x + 1
# 2. Compute the derivative of f
f_prime_expr = sp.diff(f_expr, x)
# 3. Convert symbolic expressions to Python functions
f = sp.lambdify(x, f_expr, 'numpy')
f_prime = sp.lambdify(x, f_prime_expr, 'numpy')
# 4. Generate a range of x-values
x_vals = np.linspace(-4, 2, 1000)
# 5. Compute f and f' over this range
y_vals = f(x_vals)
y_prime_vals = f_prime(x_vals)
# 6. Prepare LaTeX strings for legend
f_label = rf'$f(x) = {sp.latex(f_expr)}$'
f_prime_label = rf'$f^\prime(x) = {sp.latex(f_prime_expr)}$'
# 7. Plot f and f', with equations in the legend
plt.figure(figsize=(8, 4))
plt.plot(x_vals, y_vals, label=f_label)
plt.plot(x_vals, y_prime_vals, label=f_prime_label)
# 8. Shade the region between x-axis and f'(x) for the entire domain
plt.fill_between(x_vals, y_prime_vals, 0, color='gray', alpha=0.2, interpolate=True,
label='Region between 0 and f\'(x)')
# 9. Add reference line, labels, legend, etc.
plt.axhline(0, color='black', linewidth=0.5)
plt.title(rf'Function and its Derivative with Shading for $f^\prime(x)$')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid(True)
plt.show()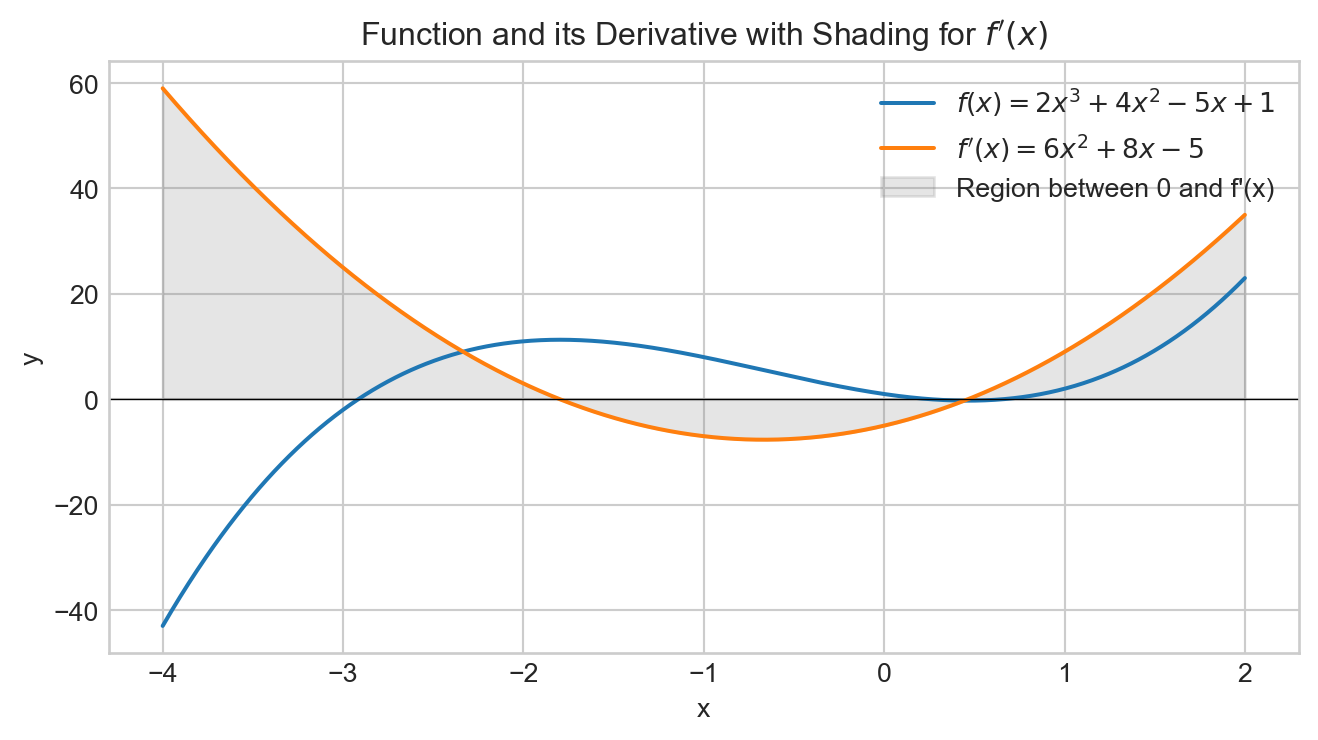
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x**2
def grad_f(x):
return 2*x
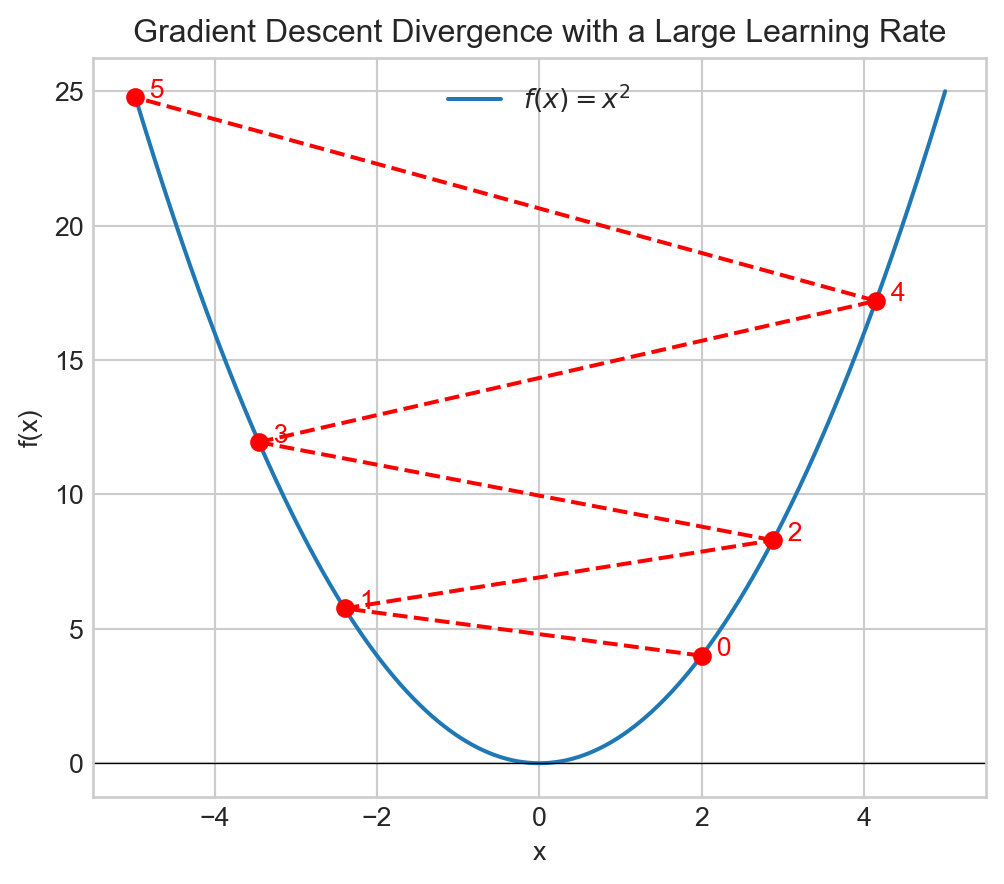
# Initial guess, learning rate, and number of gradient-descent steps
x_current = 2.0
learning_rate = 1.1 # Too large => divergence
num_iterations = 5 # We'll do five updates
# Store each x value in a list (trajectory) for plotting
trajectory = [x_current]
# Perform gradient descent
for _ in range(num_iterations):
g = grad_f(x_current)
x_current = x_current - learning_rate * g
trajectory.append(x_current)
# Prepare data for plotting
x_vals = np.linspace(-5, 5, 1000)
y_vals = f(x_vals)
# Plot the function f(x)
plt.figure(figsize=(6, 5))
plt.plot(x_vals, y_vals, label=r"$f(x) = x^2$")
plt.axhline(0, color='black', linewidth=0.5)
# Plot the trajectory, labeling each iteration
for i, x_t in enumerate(trajectory):
y_t = f(x_t)
# Plot the point
plt.plot(x_t, y_t, 'ro')
# Label the iteration number
plt.text(x_t, y_t, f" {i}", color='red')
# Connect consecutive points
if i > 0:
x_prev = trajectory[i - 1]
y_prev = f(x_prev)
plt.plot([x_prev, x_t], [y_prev, y_t], 'r--')
# Final touches
plt.title("Gradient Descent Divergence with a Large Learning Rate")
plt.xlabel("x")
plt.ylabel("f(x)")
plt.legend()
plt.grid(True)
plt.show()