from sklearn.metrics import confusion_matrix
y_actual = [0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
y_pred = [0, 1, 1, 0, 0, 0, 1, 1, 1, 1]
confusion_matrix(y_actual,y_pred)array([[1, 2],
[3, 4]])CSI 5180 - Machine Learning for Bioinformatics
Version: Feb 15, 2025 11:00


This book, 4.6 stars rating on Amazon, delves into the evaluation process, particularly focusing on classification algorithms (Japkowicz and Shah 2011).
Nathalie Japkowicz previously served as a professor at the University of Ottawa and is currently affiliated with American University in Washington.
Mohak Shah, who earned his PhD from the University of Ottawa, has held numerous industry roles, including Vice President of AI and Machine Learning at LG Electronics.
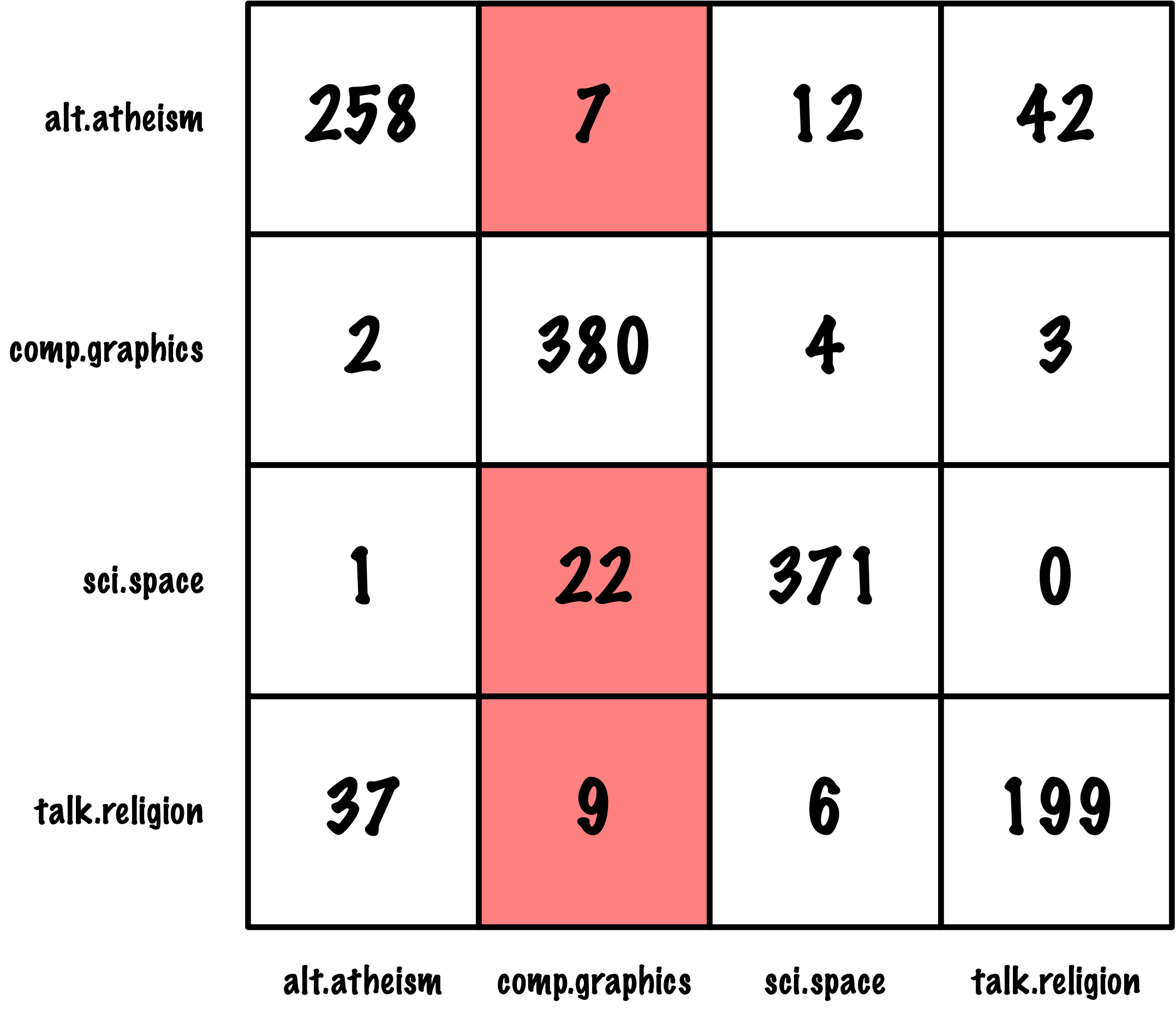
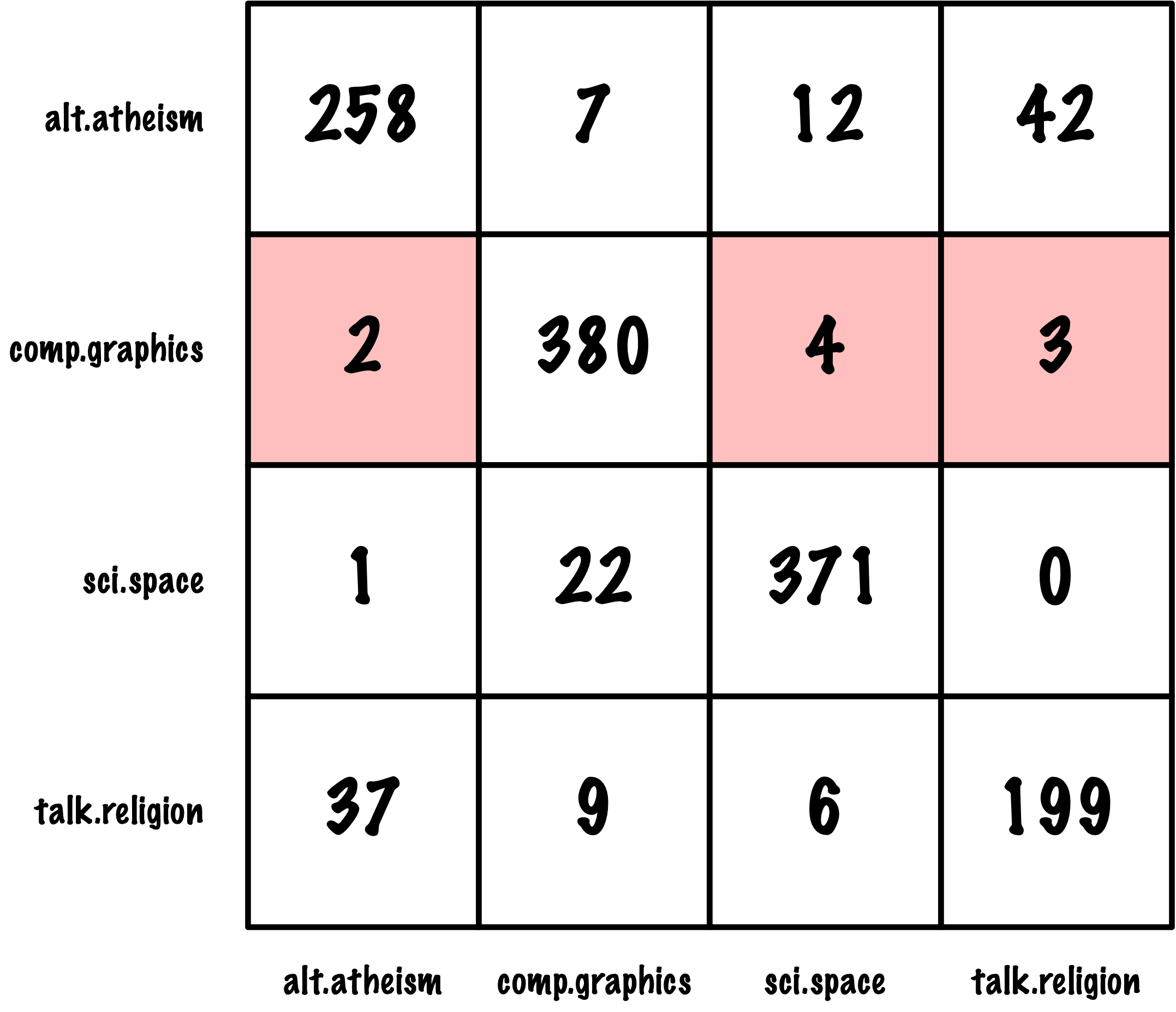
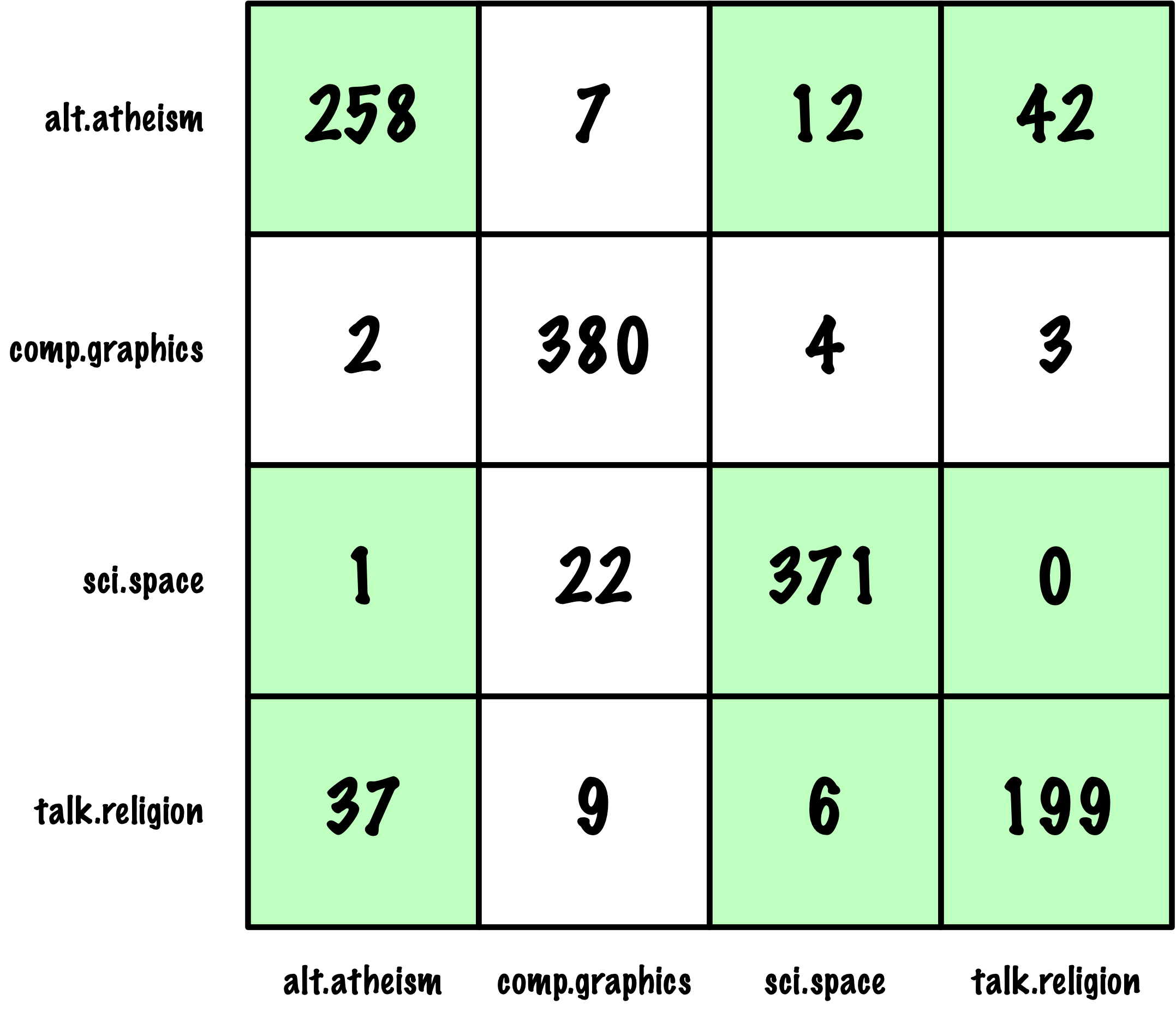
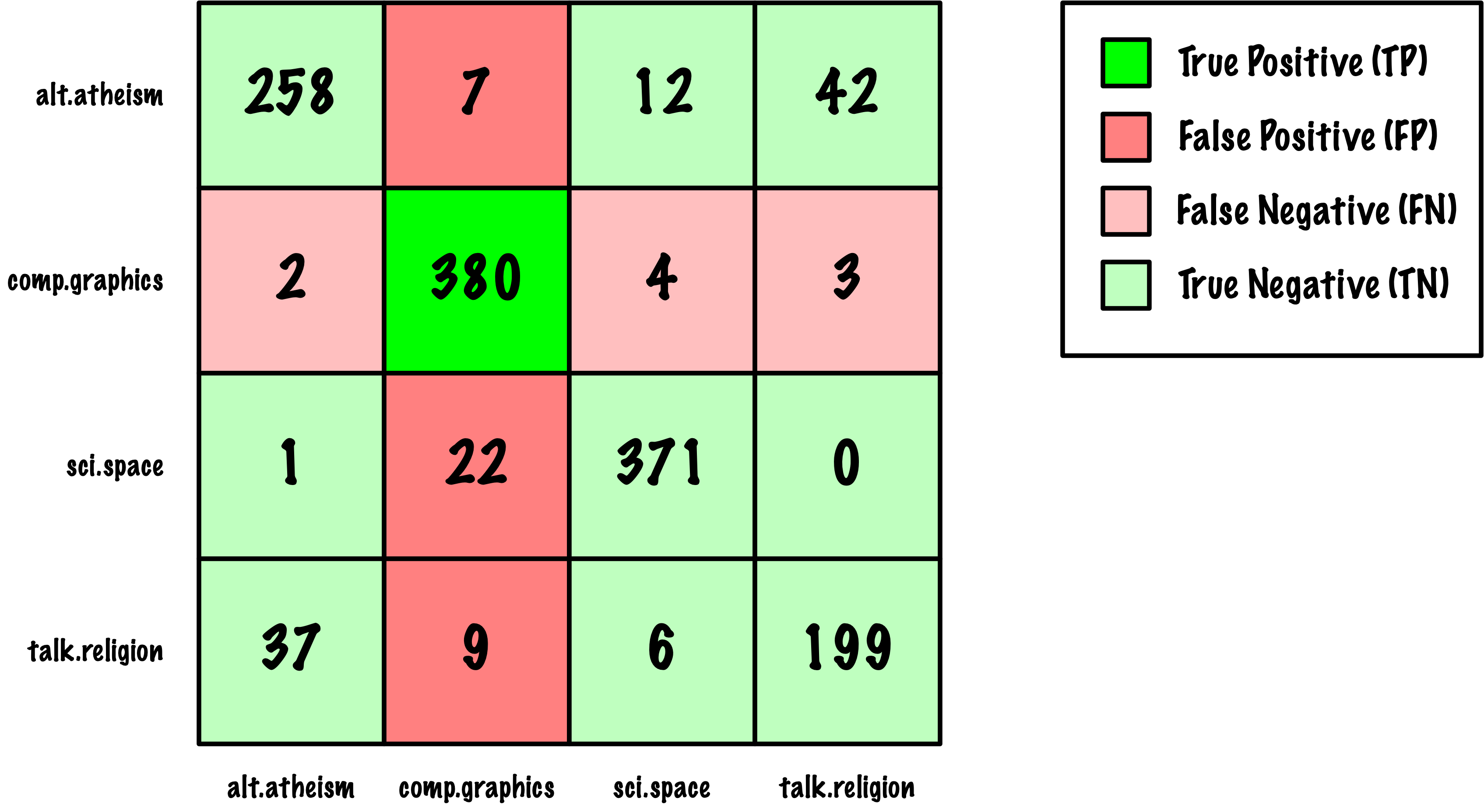
from sklearn.datasets import load_digits
import numpy as np
np.random.seed(42)
digits = load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsRestClassifier
clf = OneVsRestClassifier(LogisticRegression())
clf = clf.fit(X_train, y_train)
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
X_test = scaler.transform(X_test)
y_pred = clf.predict(X_test)
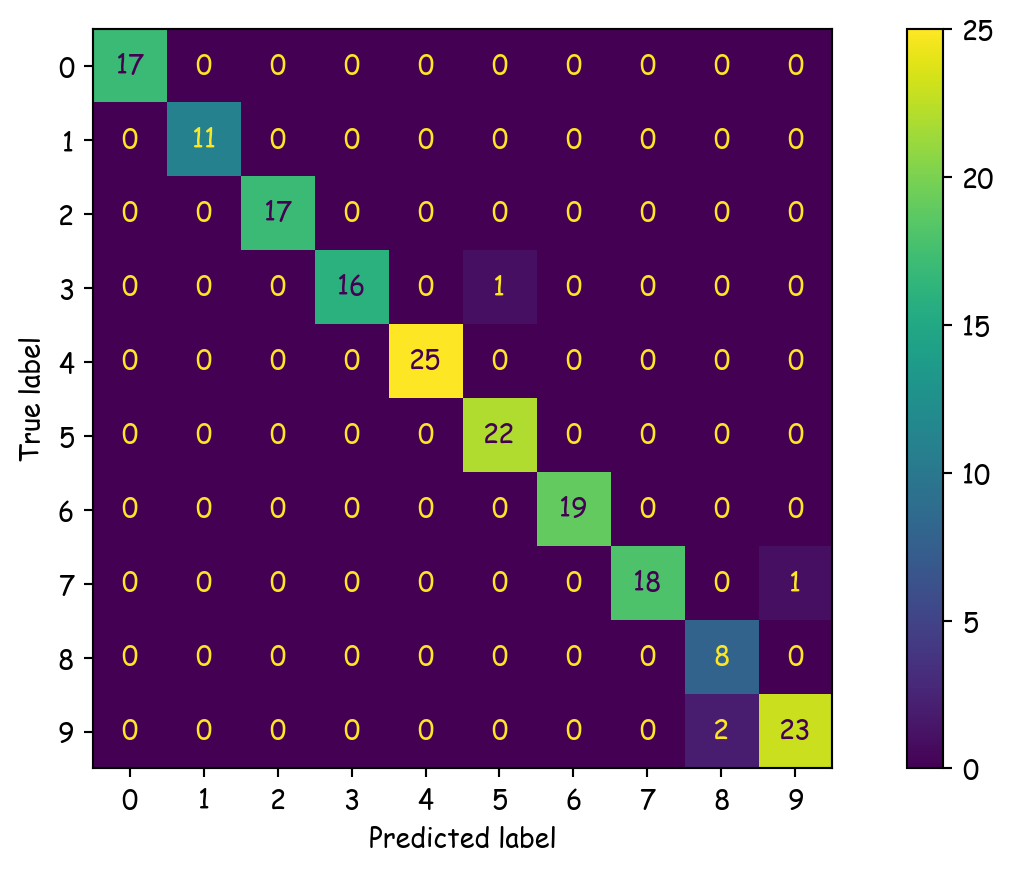
ConfusionMatrixDisplay.from_predictions(y_test, y_pred)
plt.show()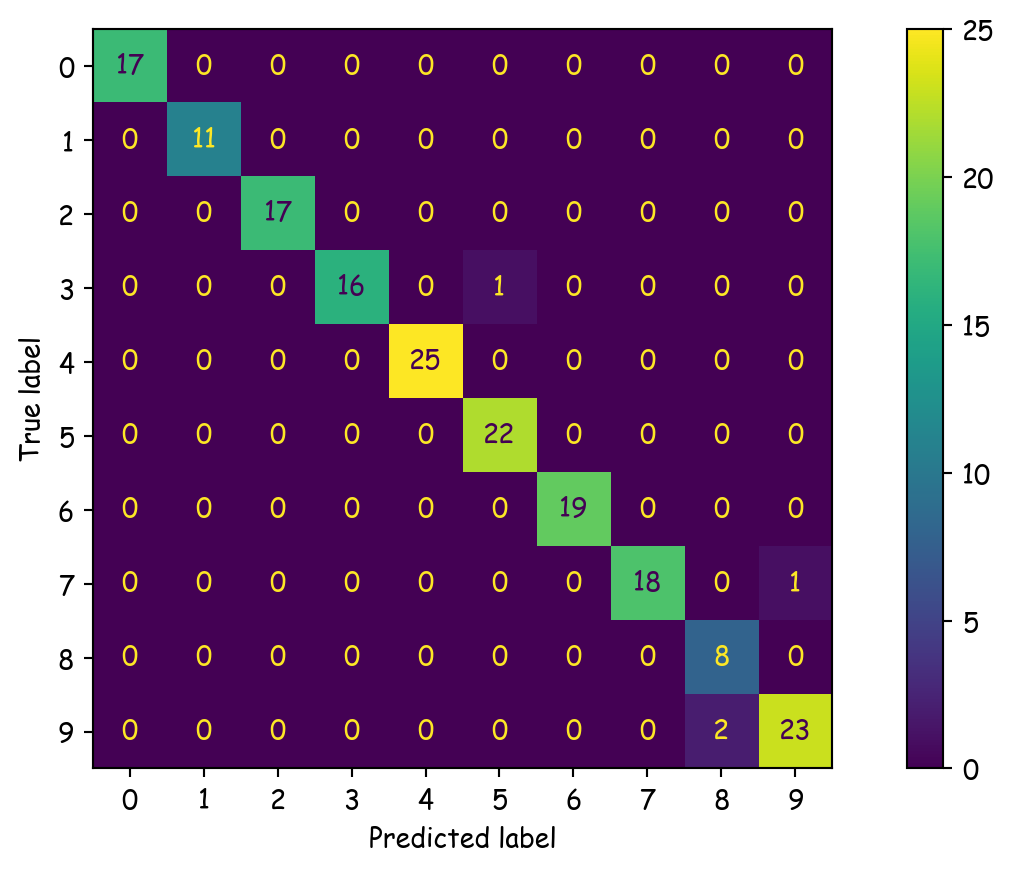
import numpy as np
np.random.seed(42)
from sklearn.datasets import load_digits
digits = load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsRestClassifier
clf = OneVsRestClassifier(LogisticRegression())
clf = clf.fit(X_train, y_train)
X_test = scaler.transform(X_test)
y_pred = clf.predict(X_test)
mask = (y_test == 9) & (y_pred == 8)
X_9_as_8 = X_test[mask]
y_9_as_8 = y_test[mask]
import matplotlib.pyplot as plt
plt.figure(figsize=(4,2))
for index, (image, label) in enumerate(zip(X_9_as_8, y_9_as_8)):
plt.subplot(1, len(X_9_as_8), index + 1)
plt.imshow(np.reshape(image, (8,8)), cmap=plt.cm.gray)
plt.title(f'y = {label}')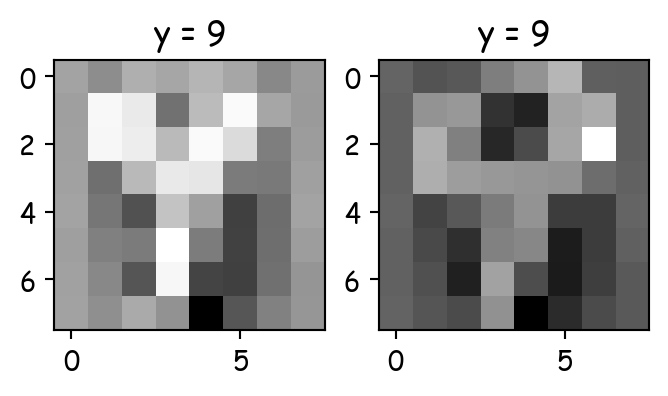
from sklearn.metrics import ConfusionMatrixDisplay
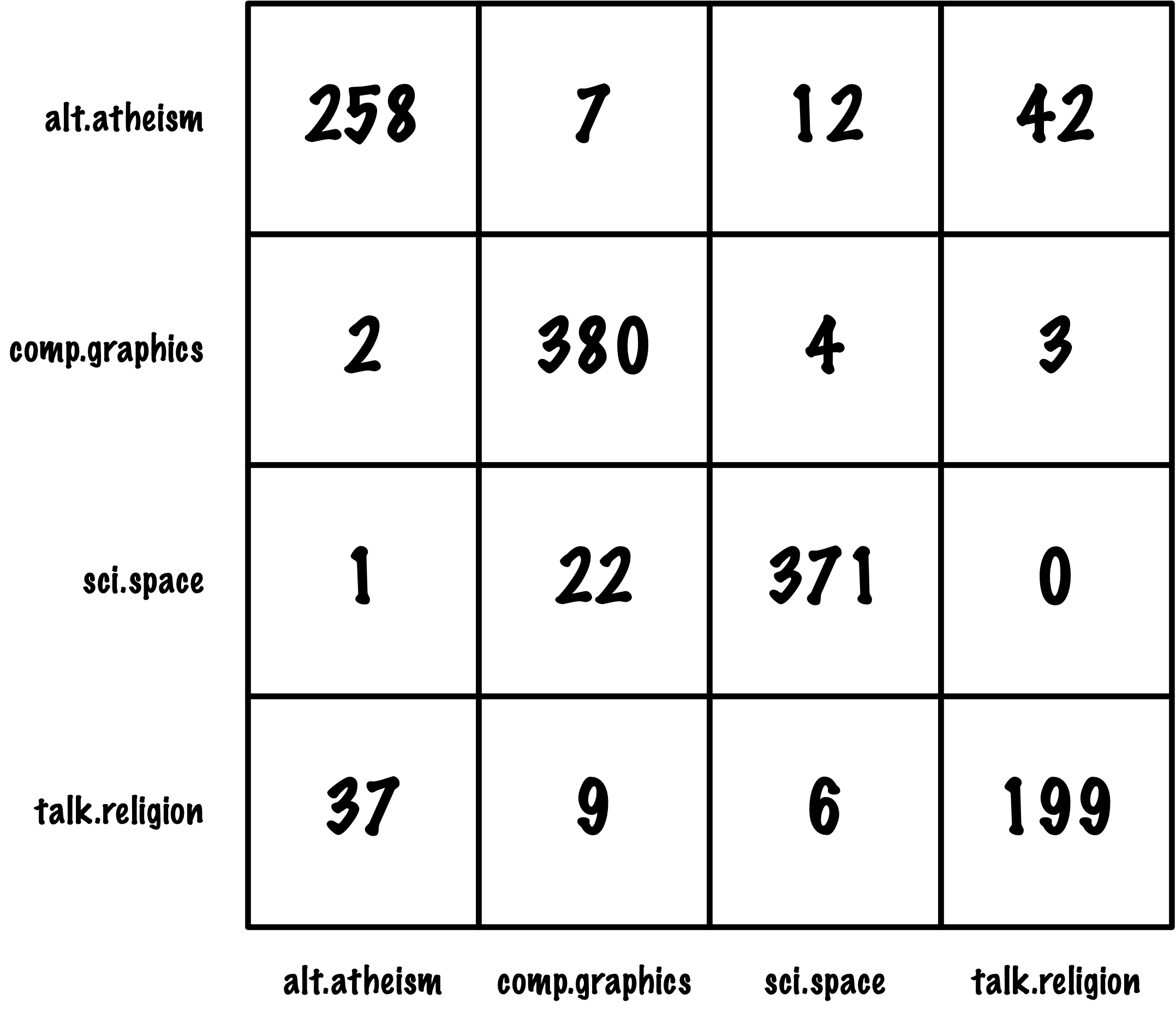
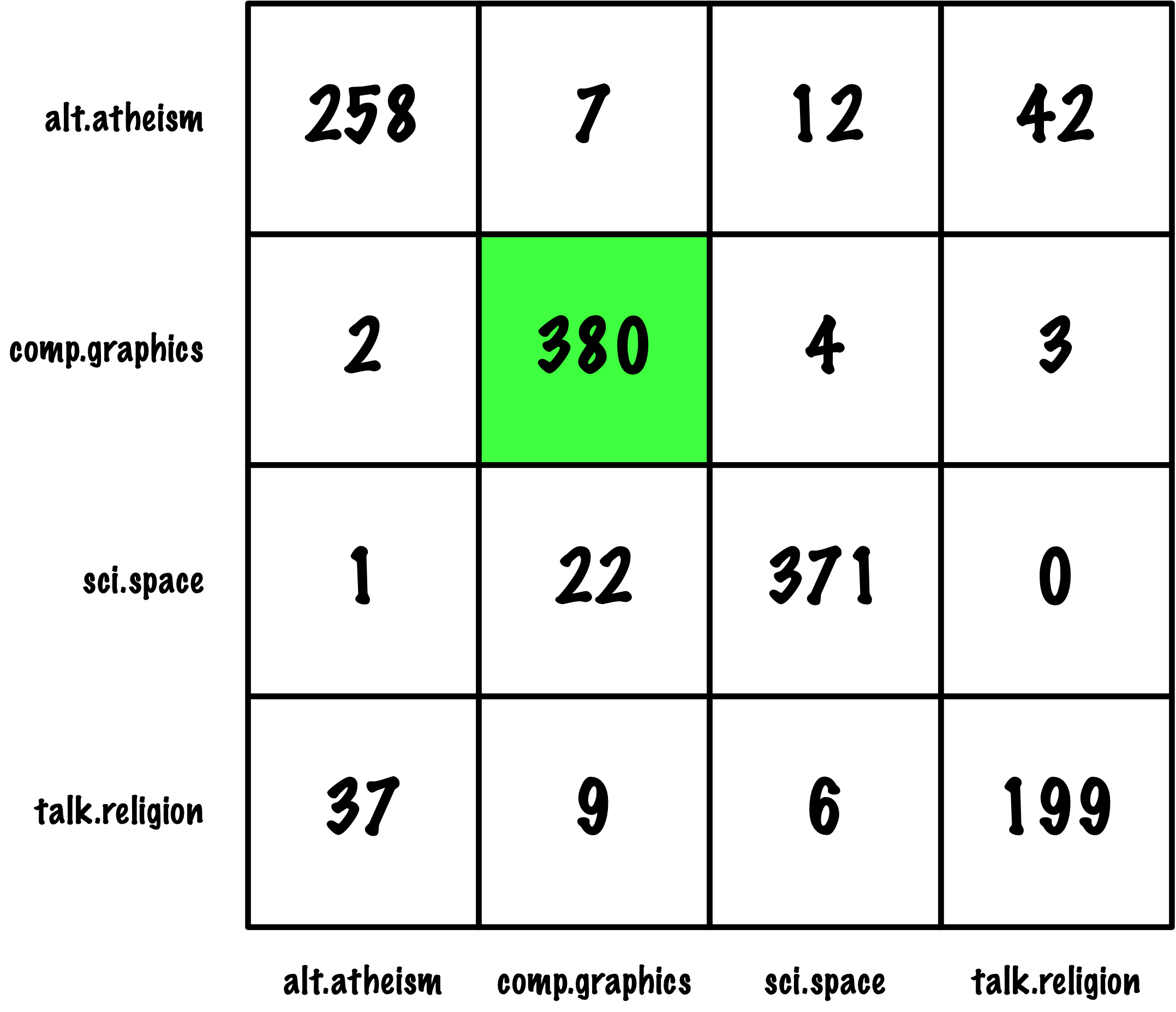
# Sample data
y_true = ['Cat'] * 42 + ['Dog'] * 7 + ['Fox'] * 11
y_pred = ['Cat'] * 39 + ['Dog'] * 1 + ['Fox'] * 2 + \
['Cat'] * 4 + ['Dog'] * 3 + ['Fox'] * 0 + \
['Cat'] * 5 + ['Dog'] * 1 + ['Fox'] * 5
ConfusionMatrixDisplay.from_predictions(y_true, y_pred)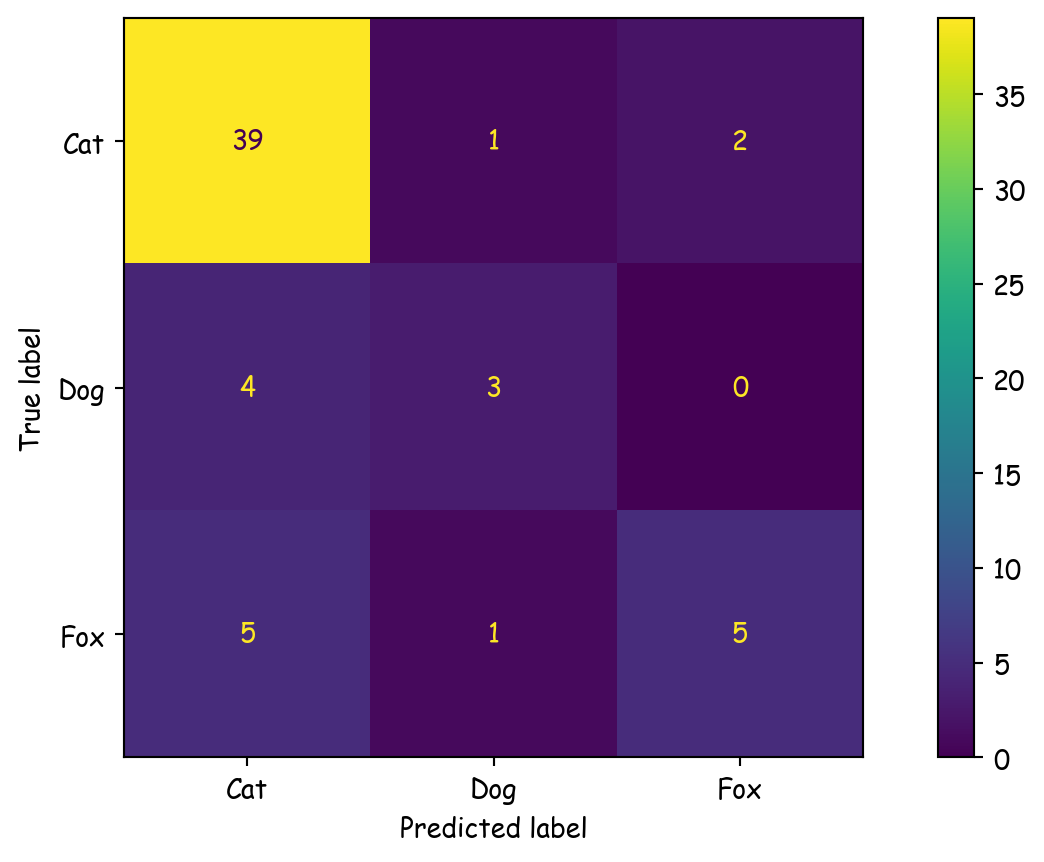
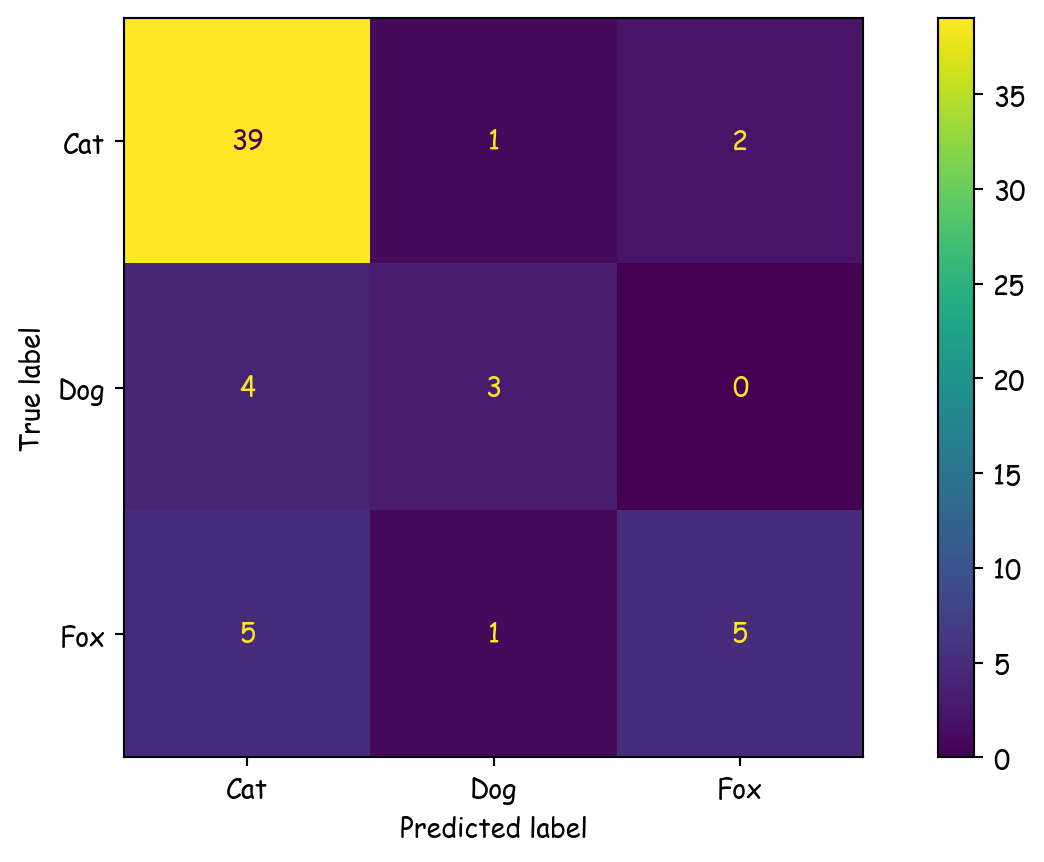
precision recall f1-score support
Cat 0.81 0.93 0.87 42
Dog 0.60 0.43 0.50 7
Fox 0.71 0.45 0.56 11
accuracy 0.78 60
macro avg 0.71 0.60 0.64 60
weighted avg 0.77 0.78 0.77 60
Micro recall: 0.78
Macro recall: 0.60
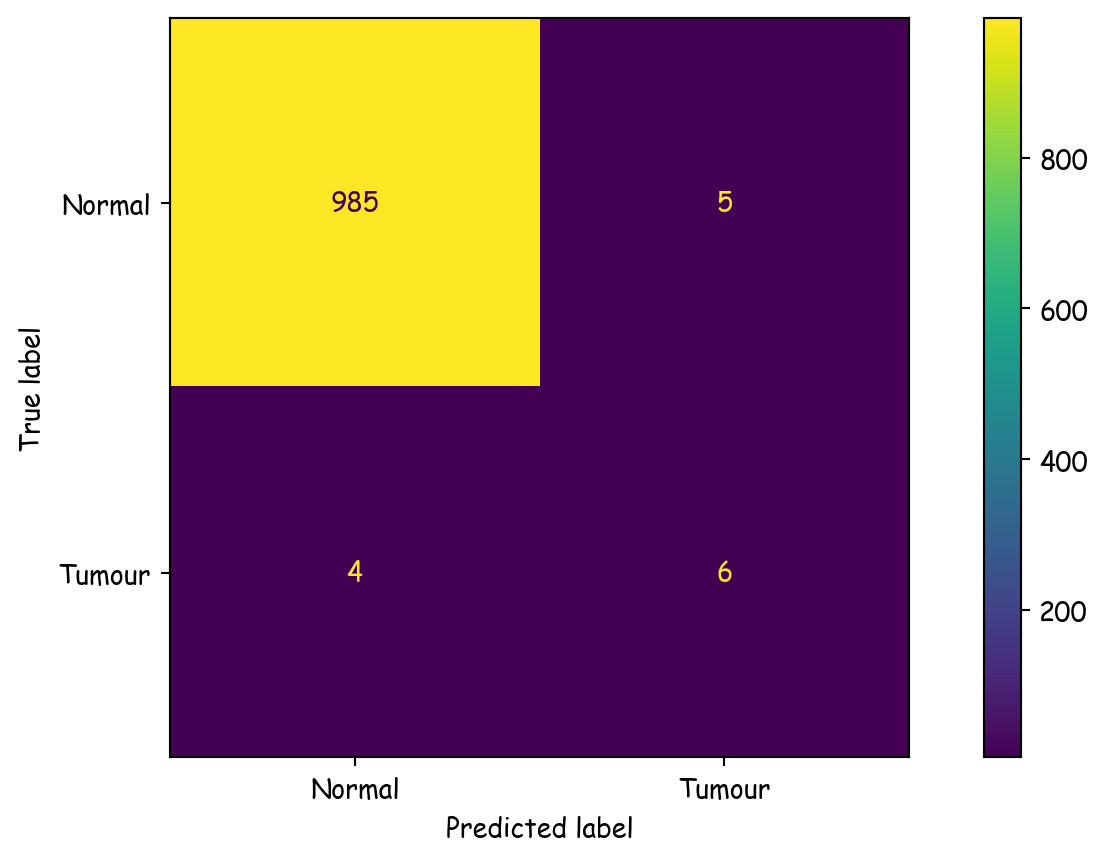
Consider a medical dataset, such as those involving diagnostic tests or imaging, comprising 990 normal samples and 10 abnormal (tumor) samples. This represents the ground truth.
Loading the dataset
Plotting the first five examples
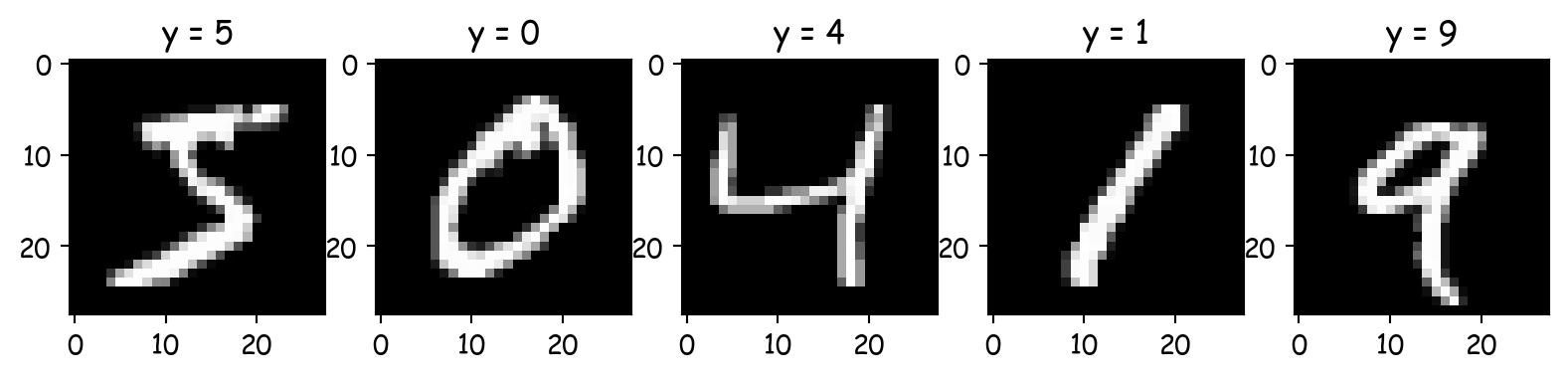
These images have dimensions of \(28 \times 28\) pixels.
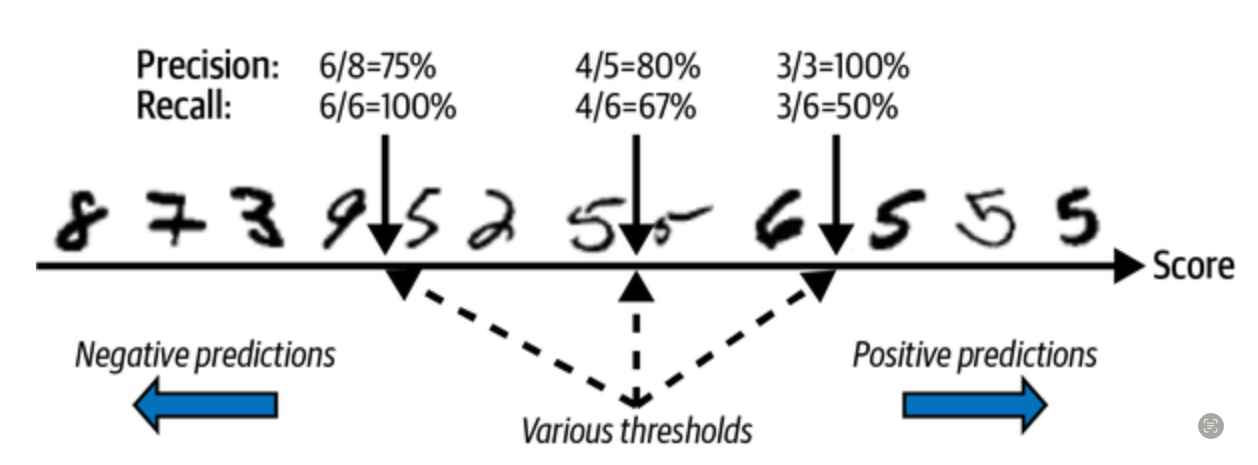
from sklearn.model_selection import cross_val_predict
y_scores = cross_val_predict(clf, X_train, y_train, cv=3, method="decision_function")
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train, y_scores)
threshold = 3000
plt.figure(figsize=(8, 4)) # extra code – it's not needed, just formatting
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)
plt.vlines(threshold, 0, 1.0, "k", "dotted", label="threshold")
# extra code – this section just beautifies and saves Figure 3–5
idx = (thresholds >= threshold).argmax() # first index ≥ threshold
plt.plot(thresholds[idx], precisions[idx], "bo")
plt.plot(thresholds[idx], recalls[idx], "go")
plt.axis([-50000, 50000, 0, 1])
plt.grid()
plt.xlabel("Threshold")
plt.legend(loc="center right")
plt.show()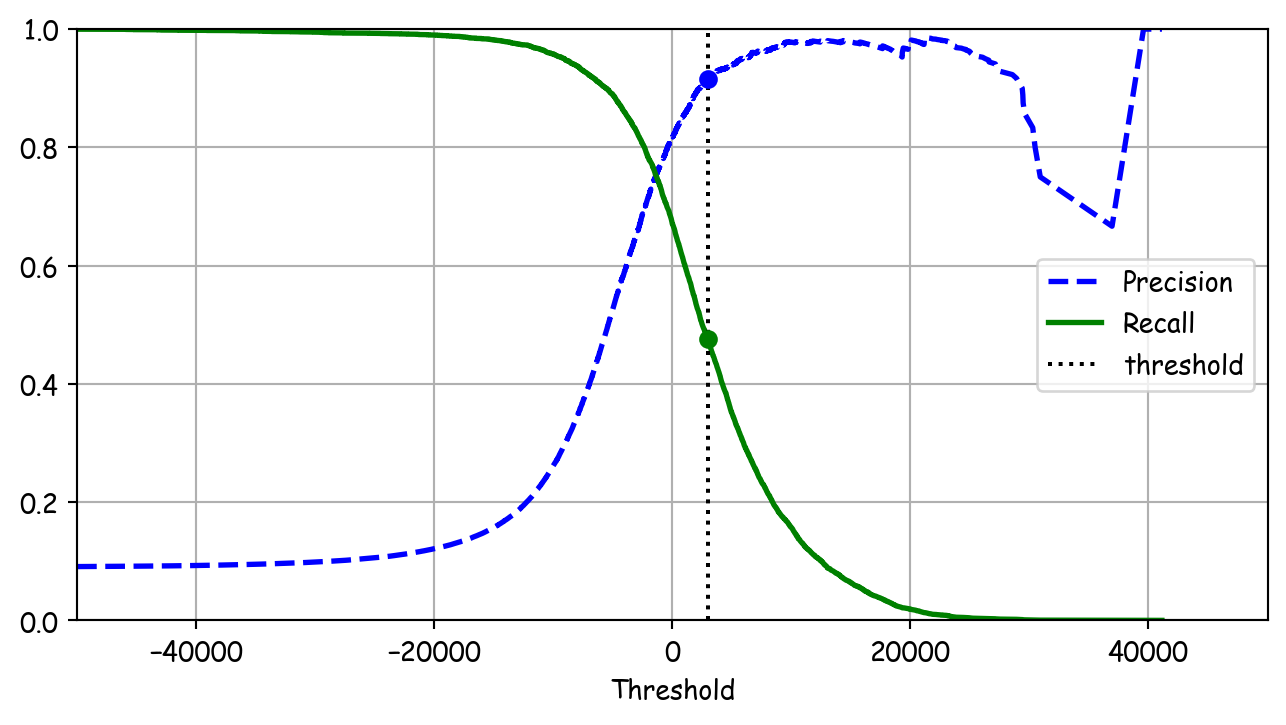
import matplotlib.patches as patches # extra code – for the curved arrow
plt.figure(figsize=(5, 5)) # extra code – not needed, just formatting
plt.plot(recalls, precisions, linewidth=2, label="Precision/Recall Curve")
# extra code – just beautifies and saves Figure 3–6
plt.plot([recalls[idx], recalls[idx]], [0., precisions[idx]], "k:")
plt.plot([0.0, recalls[idx]], [precisions[idx], precisions[idx]], "k:")
plt.plot([recalls[idx]], [precisions[idx]], "ko",
label="Point at threshold 3,000")
plt.gca().add_patch(patches.FancyArrowPatch(
(0.79, 0.60), (0.61, 0.78),
connectionstyle="arc3,rad=.2",
arrowstyle="Simple, tail_width=1.5, head_width=8, head_length=10",
color="#444444"))
plt.text(0.56, 0.62, "Higher\nthreshold", color="#333333")
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.axis([0, 1, 0, 1])
plt.grid()
plt.legend(loc="lower left")
plt.show()
idx_for_90_precision = (precisions >= 0.90).argmax()
threshold_for_90_precision = thresholds[idx_for_90_precision]
y_train_pred_90 = (y_scores >= threshold_for_90_precision)
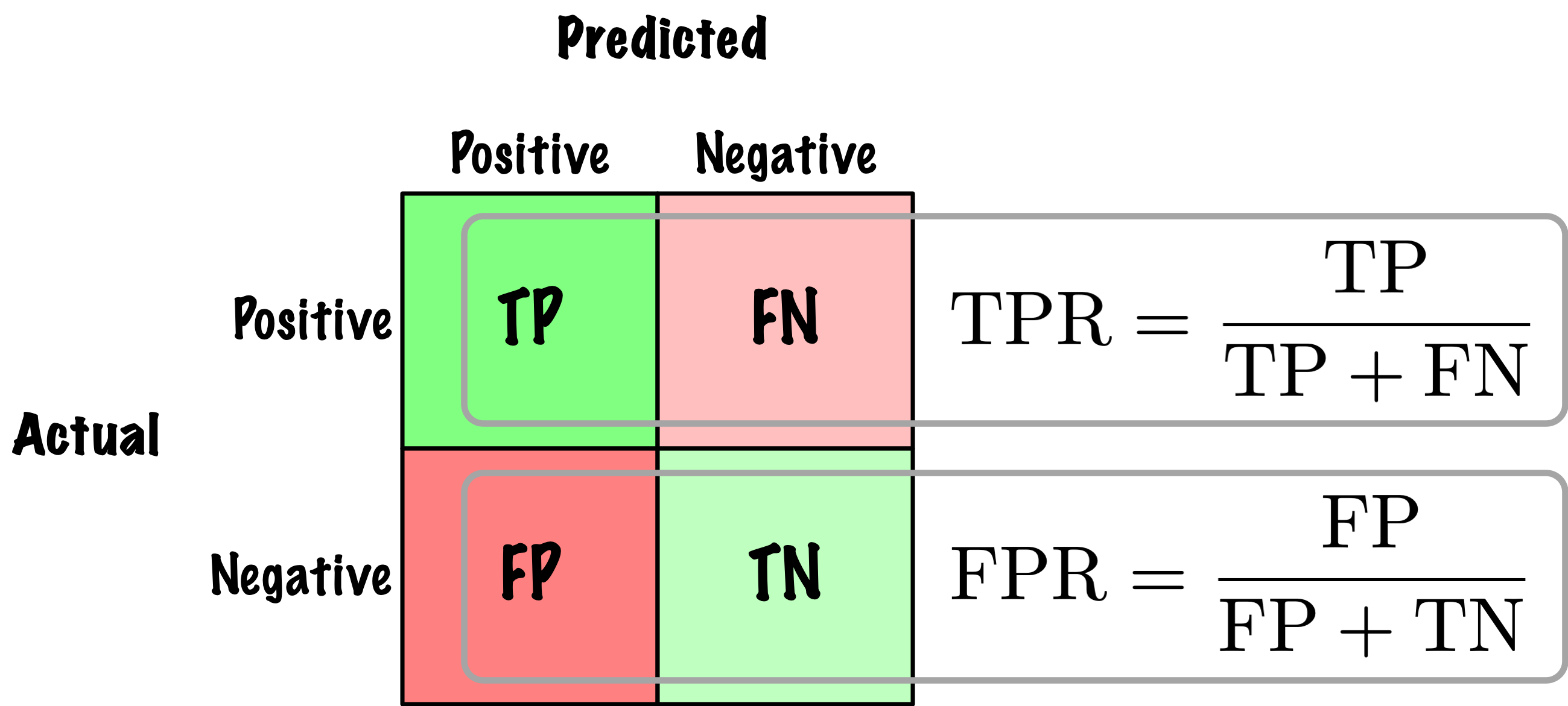
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train, y_scores)
idx_for_threshold_at_90 = (thresholds <= threshold_for_90_precision).argmax()
tpr_90, fpr_90 = tpr[idx_for_threshold_at_90], fpr[idx_for_threshold_at_90]
plt.figure(figsize=(5, 5)) # extra code – not needed, just formatting
plt.plot(fpr, tpr, linewidth=2, label="ROC curve")
plt.plot([0, 1], [0, 1], 'k:', label="Random classifier's ROC curve")
plt.plot([fpr_90], [tpr_90], "ko", label="Threshold for 90% precision")
# extra code – just beautifies and saves Figure 3–7
plt.gca().add_patch(patches.FancyArrowPatch(
(0.20, 0.89), (0.07, 0.70),
connectionstyle="arc3,rad=.4",
arrowstyle="Simple, tail_width=1.5, head_width=8, head_length=10",
color="#444444"))
plt.text(0.12, 0.71, "Higher\nthreshold", color="#333333")
plt.xlabel('False Positive Rate (Fall-Out)')
plt.ylabel('True Positive Rate (Recall)')
plt.grid()
plt.axis([0, 1, 0, 1])
plt.legend(loc="lower right", fontsize=13)
plt.show()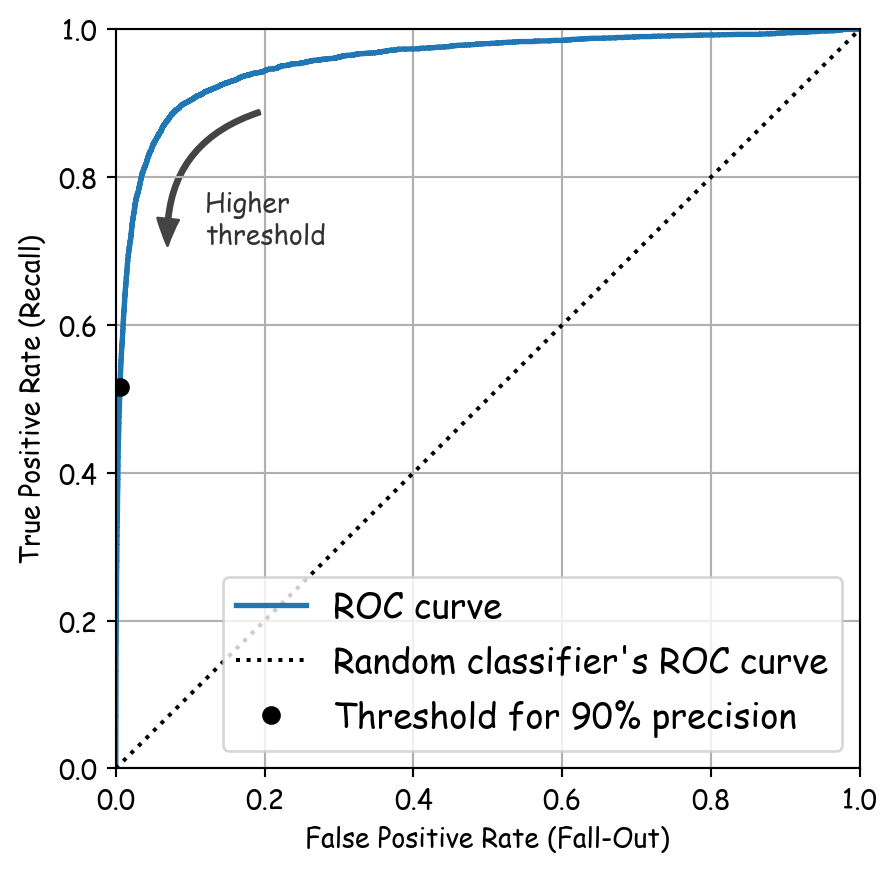
from sklearn.metrics import roc_auc_score
y_pred_prob_lr = lr.predict_proba(X_test)[:, 1]
y_pred_prob_knn = knn.predict_proba(X_test)[:, 1]
y_pred_prob_dt = dt.predict_proba(X_test)[:, 1]
y_pred_prob_rf = rf.predict_proba(X_test)[:, 1]
# Compute ROC curves
fpr_lr, tpr_lr, _ = roc_curve(y_test, y_pred_prob_lr)
fpr_knn, tpr_knn, _ = roc_curve(y_test, y_pred_prob_knn)
fpr_dt, tpr_dt, _ = roc_curve(y_test, y_pred_prob_dt)
fpr_rf, tpr_rf, _ = roc_curve(y_test, y_pred_prob_rf)
# Compute AUC scores
auc_lr = roc_auc_score(y_test, y_pred_prob_lr)
auc_knn = roc_auc_score(y_test, y_pred_prob_knn)
auc_dt = roc_auc_score(y_test, y_pred_prob_dt)
auc_rf = roc_auc_score(y_test, y_pred_prob_rf)
# Plot ROC curves
plt.figure(figsize=(5, 5)) # plt.figure()
plt.plot(fpr_lr, tpr_lr, color='blue', label=f'Logistic Regression (AUC = {auc_lr:.2f})')
plt.plot(fpr_knn, tpr_knn, color='green', label=f'K-Nearest Neighbors (AUC = {auc_knn:.2f})')
plt.plot(fpr_dt, tpr_dt, color='orange', label=f'Decision Tree (AUC = {auc_dt:.2f})')
plt.plot(fpr_rf, tpr_rf, color='purple', label=f'Random Forest (AUC = {auc_rf:.2f})')
plt.plot([0, 1], [0, 1], color='red', linestyle='--') # Diagonal line for random chance
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curves for Logistic Regression, KNN, Decision Tree, and Random Forest')
plt.legend(loc="lower right")
plt.show()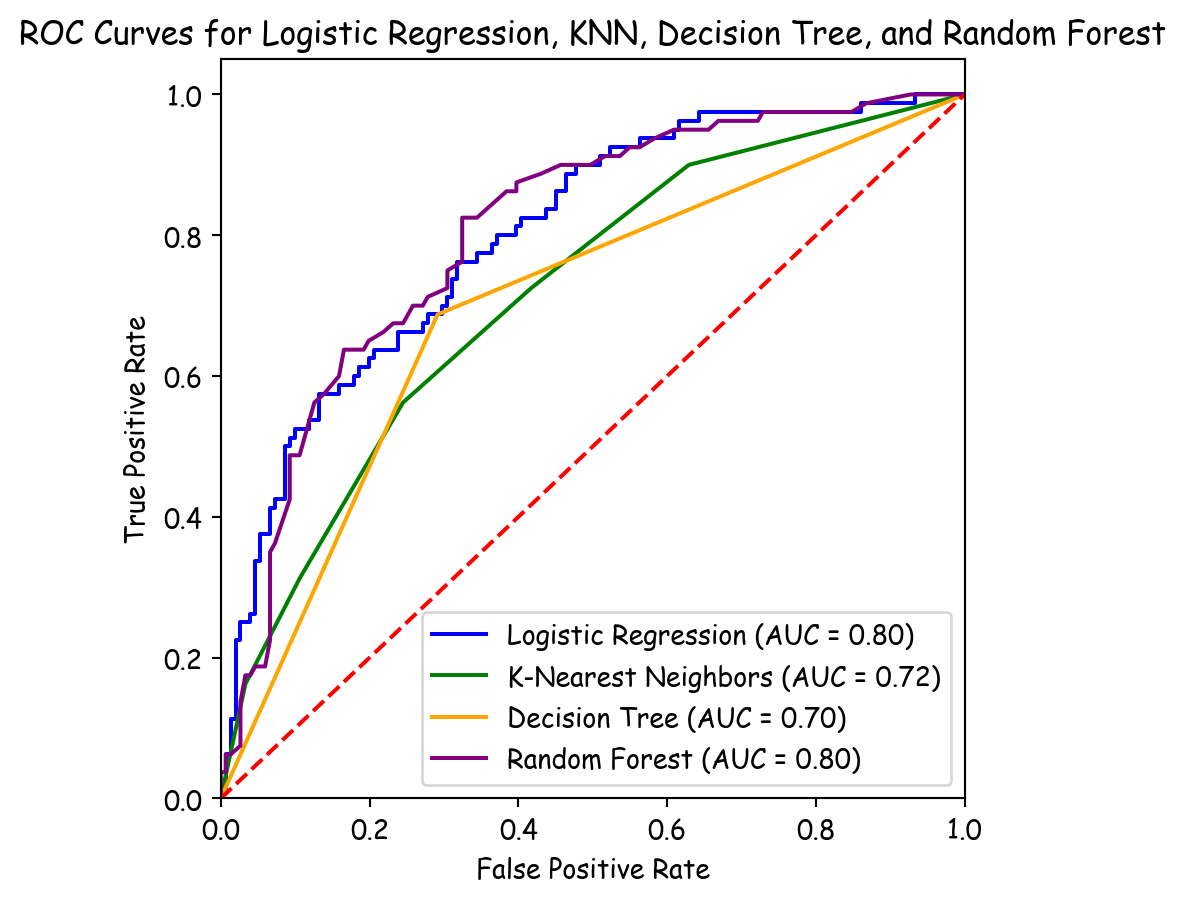
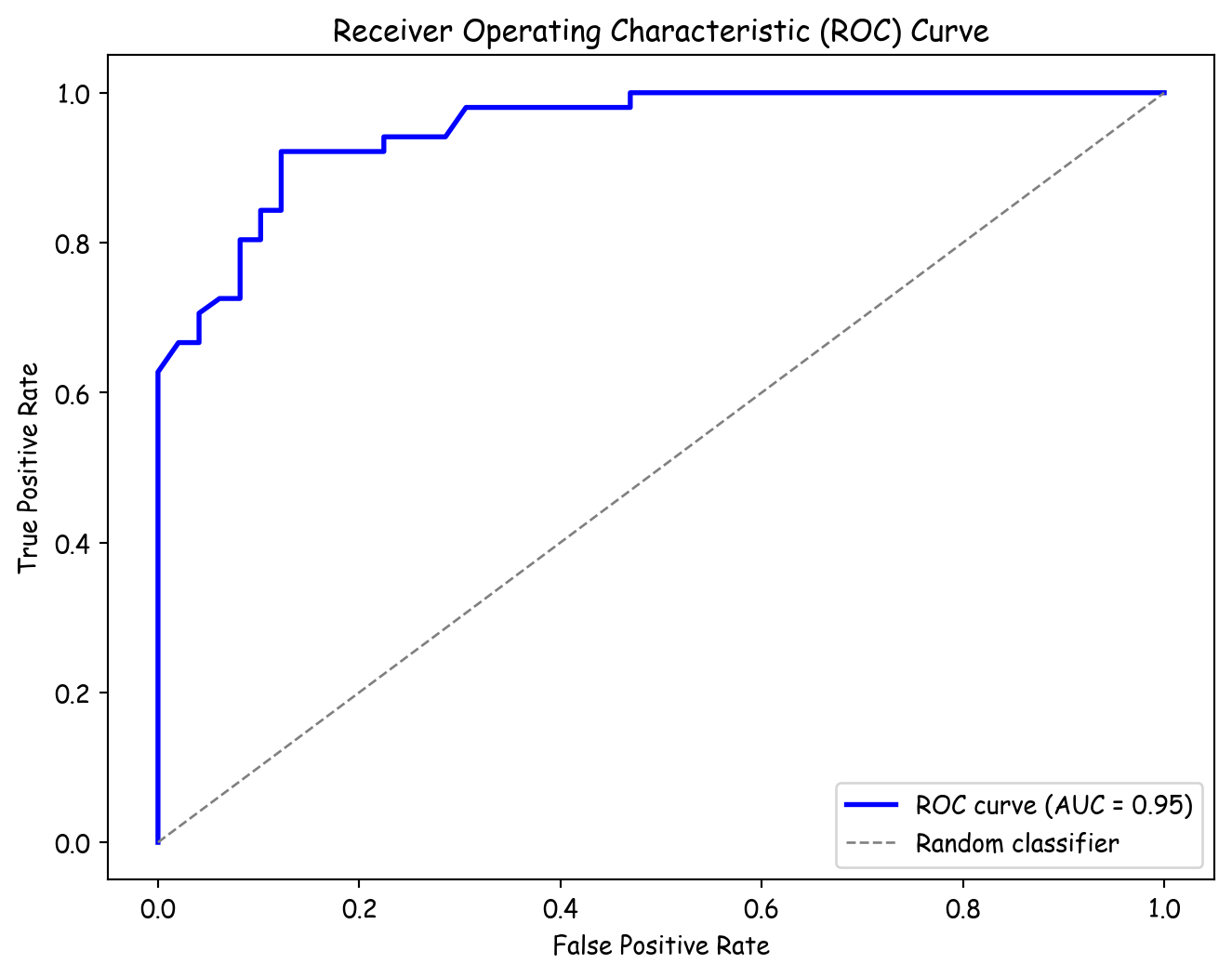
# Compute predicted probabilities for the positive class
y_probs = predict_probabilities(theta, X_intercept)
# Define a set of threshold values between 0 and 1 (e.g., 100 equally spaced thresholds)
thresholds = np.linspace(0, 1, 100)
# Compute the ROC curve (FPR and TPR for each threshold)
fpr, tpr = compute_roc_curve(y, y_probs, thresholds)
auc_value = compute_auc(fpr, tpr)
# Plot the ROC curve
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', lw=2, label='ROC curve (AUC = %0.2f)' % auc_value)
plt.plot([0, 1], [0, 1], color='gray', lw=1, linestyle='--', label='Random classifier')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show()