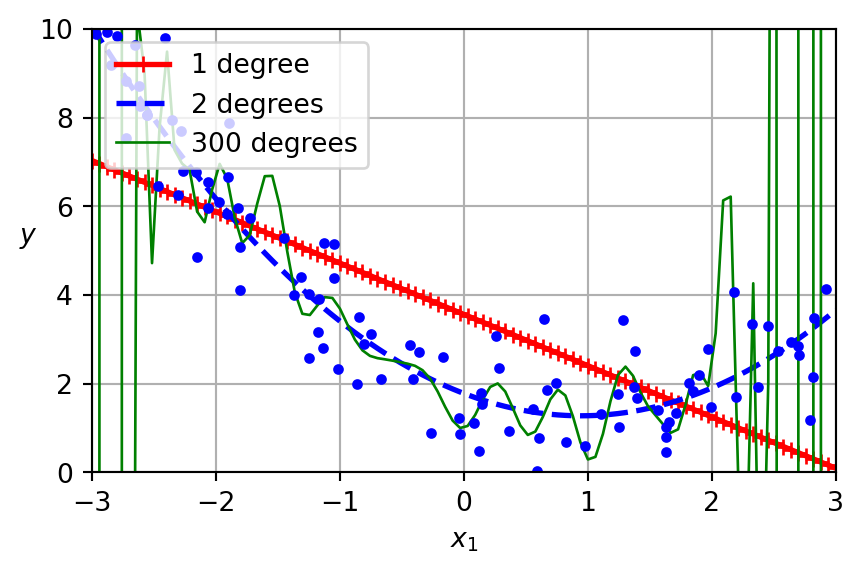
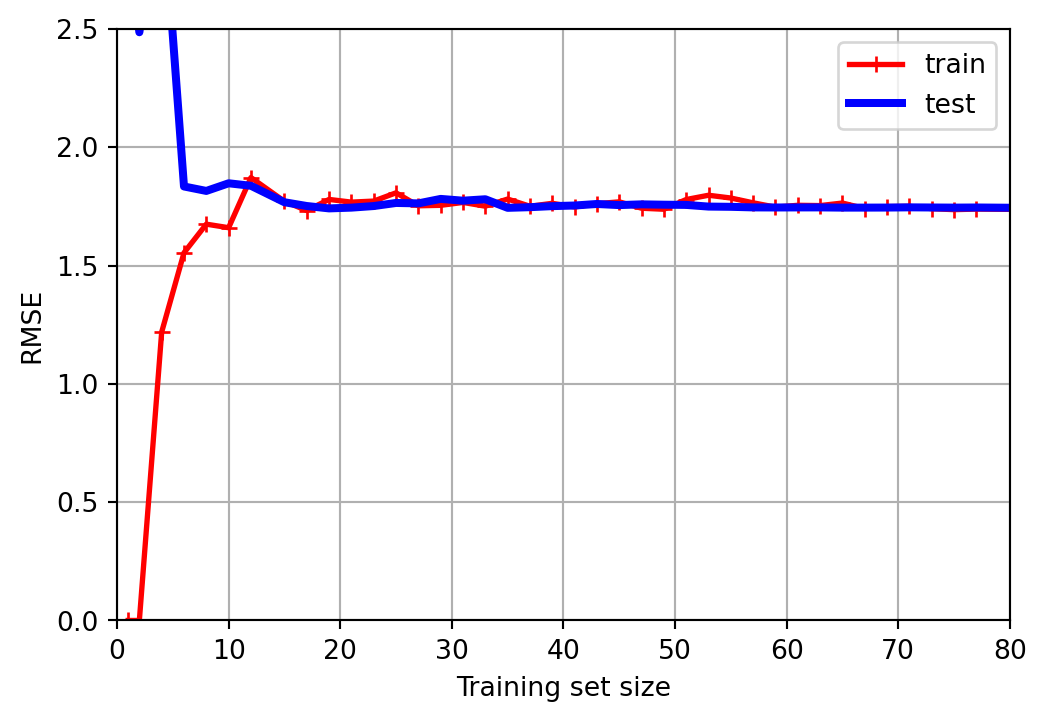
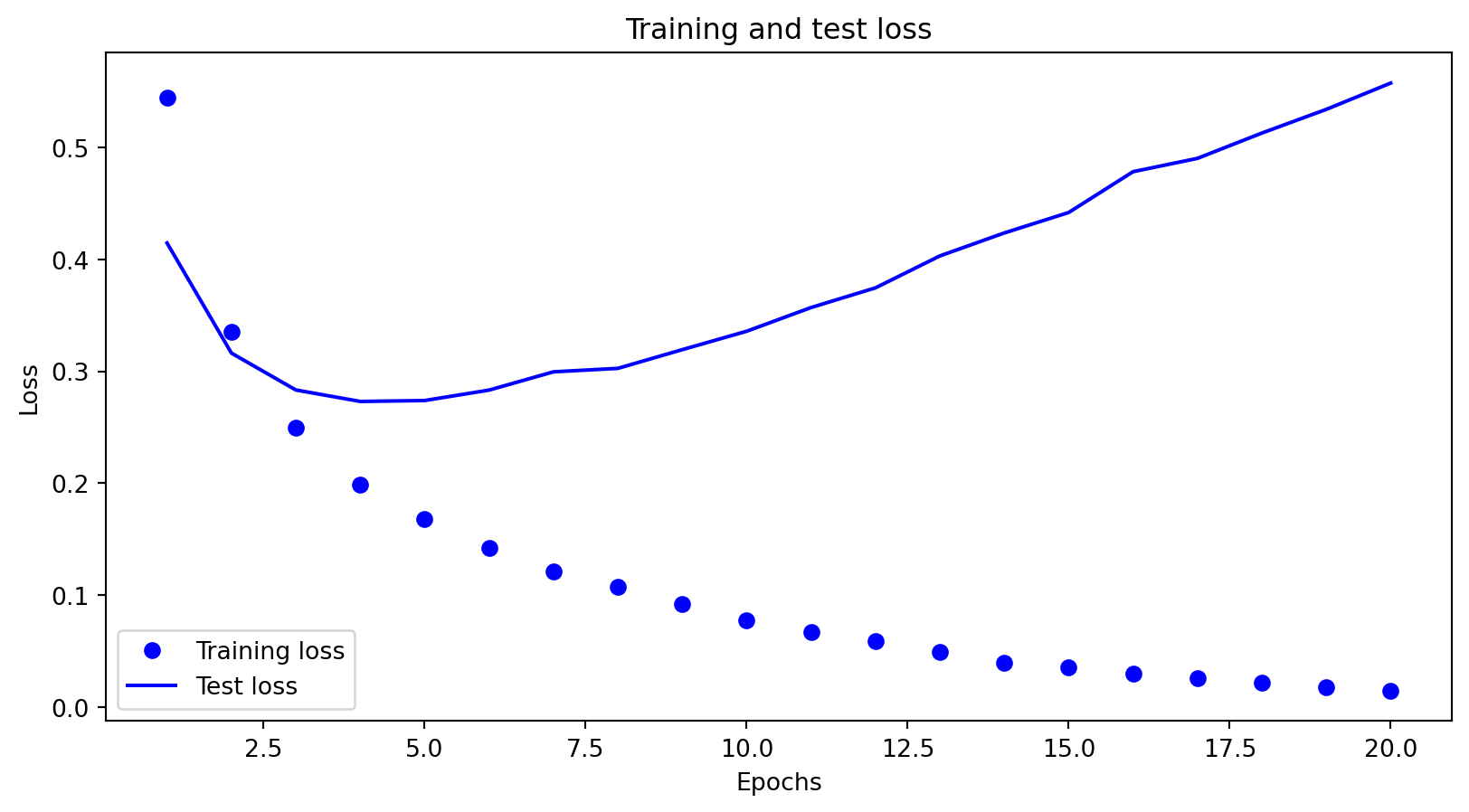
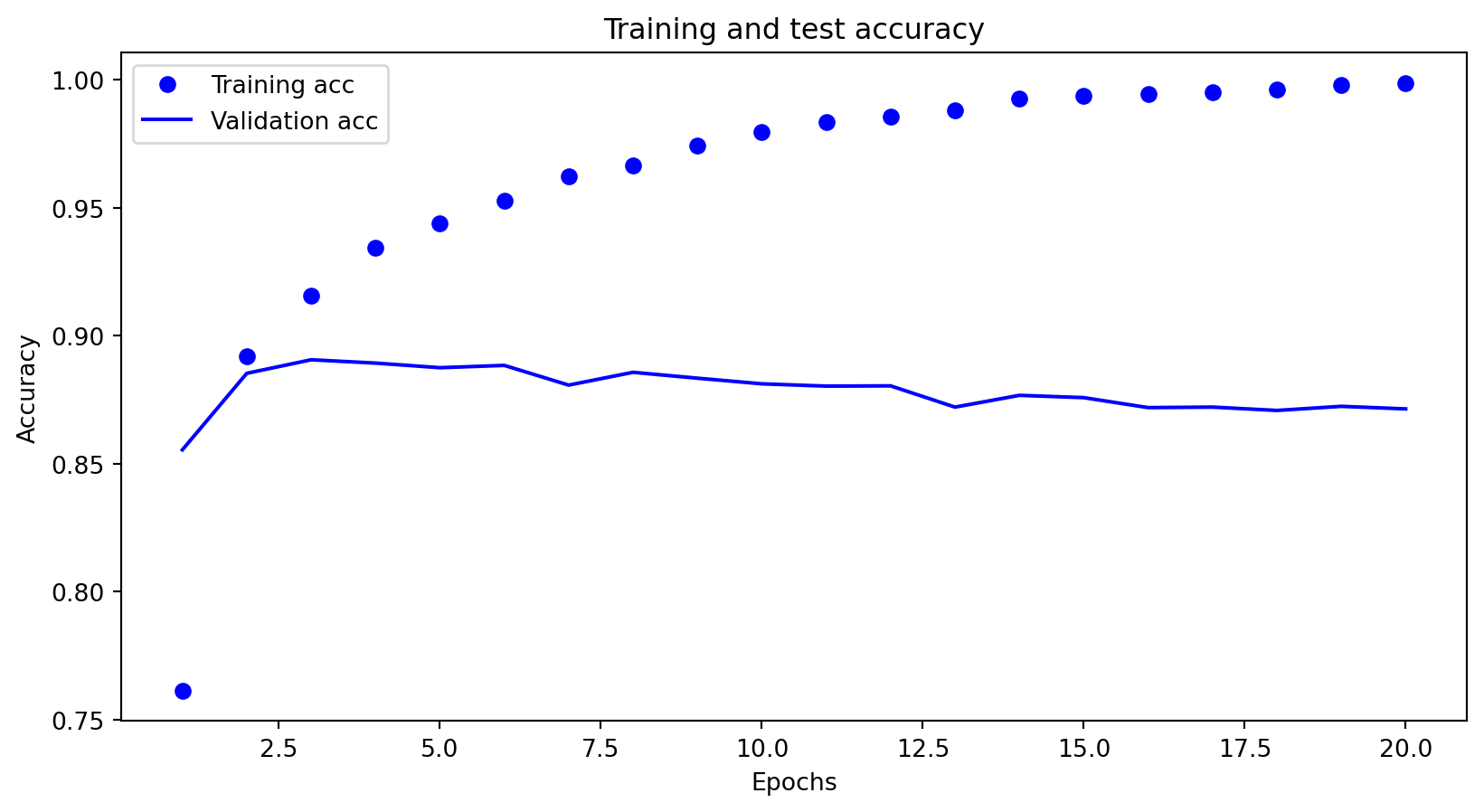
In this lecture, we explore how model complexity influences bias, variance, and generalization by examining underfitting and overfitting through learning curves across various models, including linear, polynomial, tree-based, KNN, and deep networks.
Learning Outcomes
Grasp how model complexity affects bias, variance, and generalization.
Analyze learning curves to diagnose underfitting and overfitting.
Model Complexity
Rationale
Optimizing model performance critically depends on the careful selection and tuning of hyperparameters.
These hyperparameters play a pivotal role in regulating the complexity of machine learning models.
Definition
Model complexity in refers to the capacity of a model to capture intricate patterns in the data.
It is determined by the number of parameters or the structure of the model.
Exploration
Code
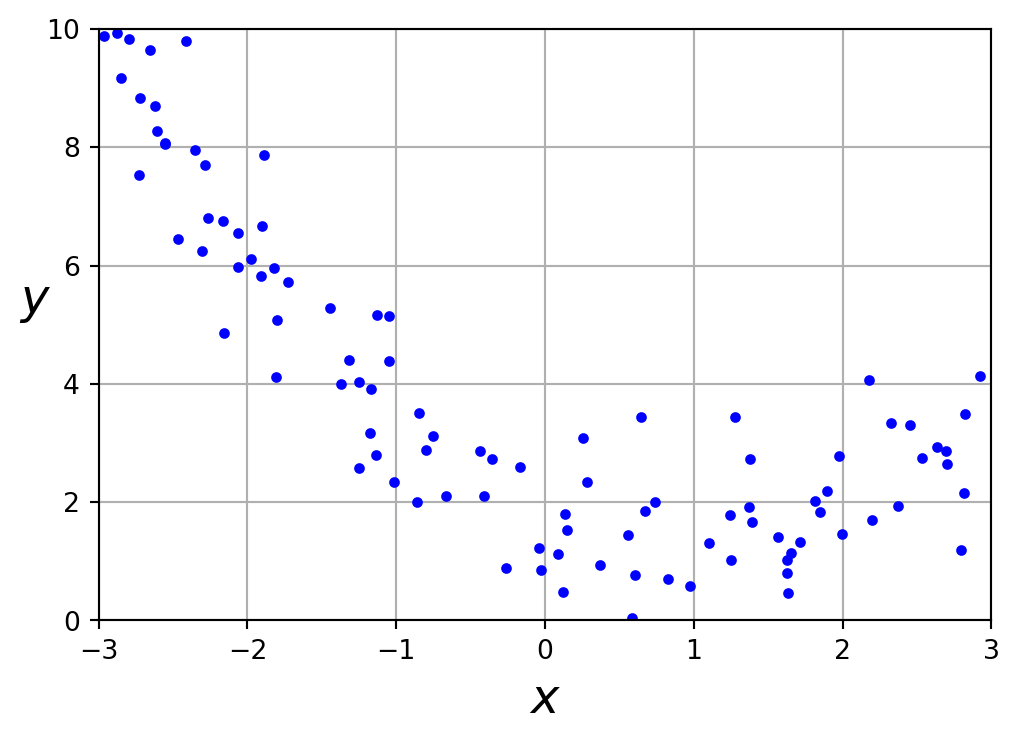
import numpy as npnp.random.seed(42)X =6* np.random.rand(100, 1) -3y =0.5* X **2- X +2+ np.random.randn(100, 1)import matplotlib as mplimport matplotlib.pyplot as pltplt.figure(figsize=(6,4))plt.plot(X, y, "b.")plt.xlabel("$x$", fontsize=18)plt.ylabel("$y$", rotation=0, fontsize=18)plt.axis([-3, 3, 0, 10])plt.grid(True)plt.show()
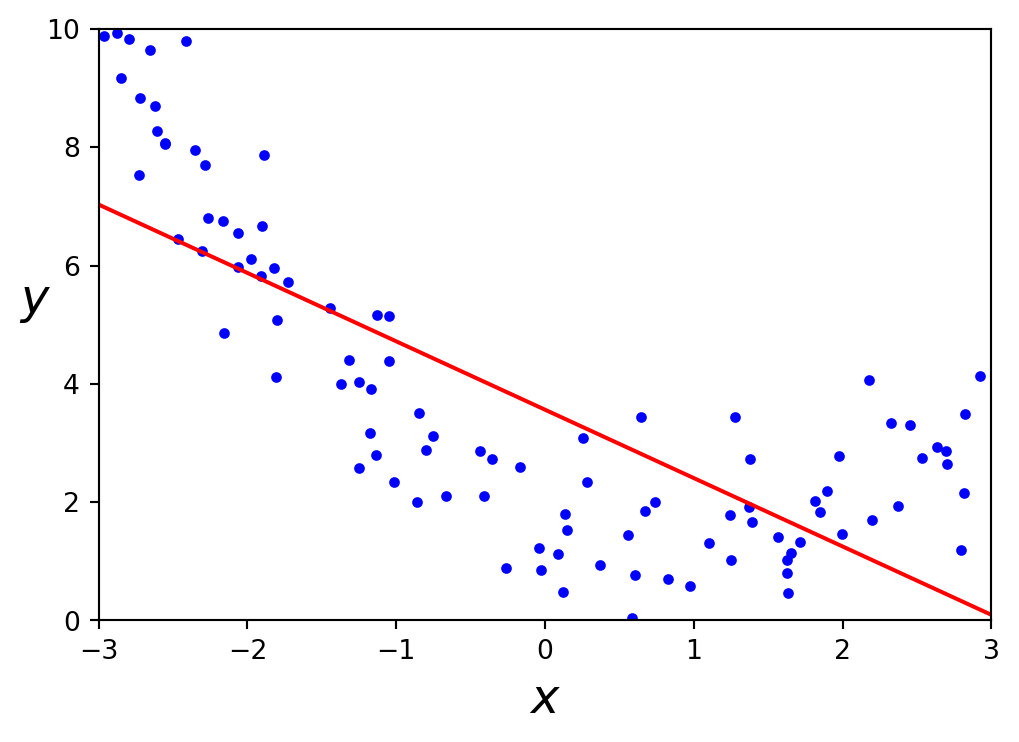
A linear model inadequately represents this dataset.
Definition
Feature engineering is the process of creating, transforming, and selecting variables (attributes) from raw data to improve the performance of machine learning models.
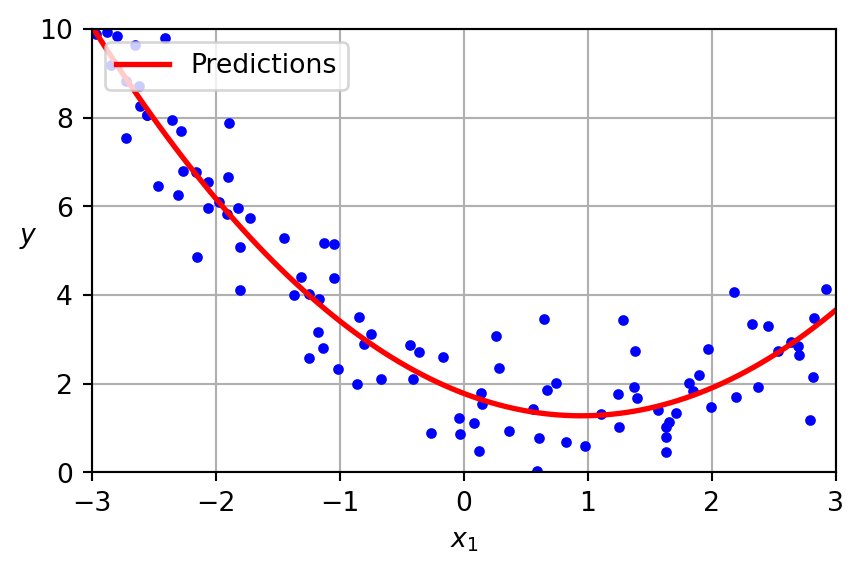
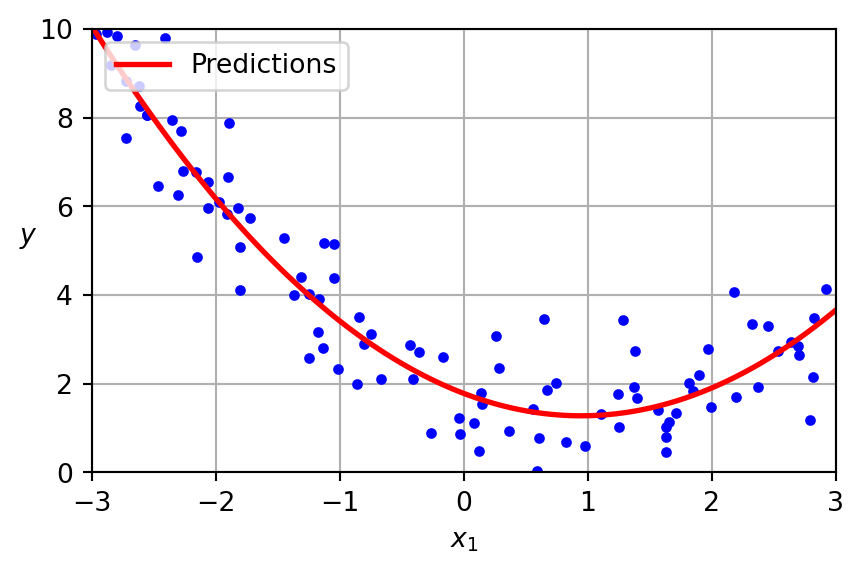
Generate a new feature matrix consisting of all polynomial combinations of the features with degree less than or equal to the specified degree. For example, if an input sample is two dimensional and of the form \([a, b]\), the degree-2 polynomial features are \([1, a, b, a^2, ab, b^2]\).
PolynomialFeatures
Given two features \(a\) and \(b\), PolynomialFeatures with degree=3 would add \(a^2\), \(a^3\), \(b^2\), \(b^3\), as well as, \(ab\), \(a^2b\), \(ab^2\)!
Warning
PolynomialFeatures(degree=d) adds \(\frac{(D+d)!}{d!D!}\) features, where \(D\) is the original number of features.
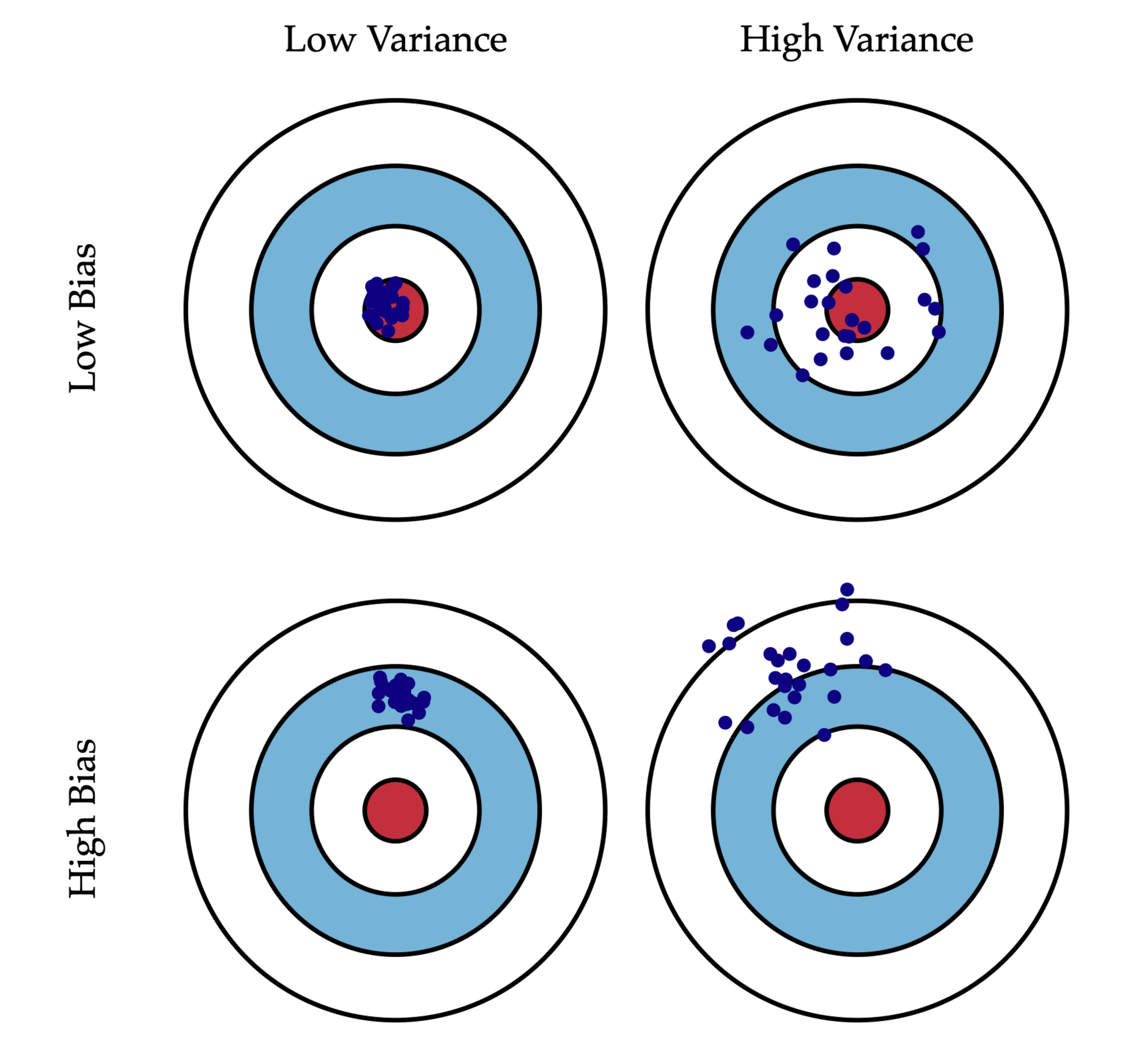
Model selection aims to minimize bias, which arises from overly simplistic models, and variance, which results from overly complex models prone to overfitting.
Ideally, with infinite data, both bias and variance could be reduced to zero.
However, in practice, data is typically noisy, and some irreducible error persists due to unaccounted factors beyond the model’s scope.
Bais-Variance Tradeoff
Bais-Variance Tradeoff
High Bias, Low Variance
Code
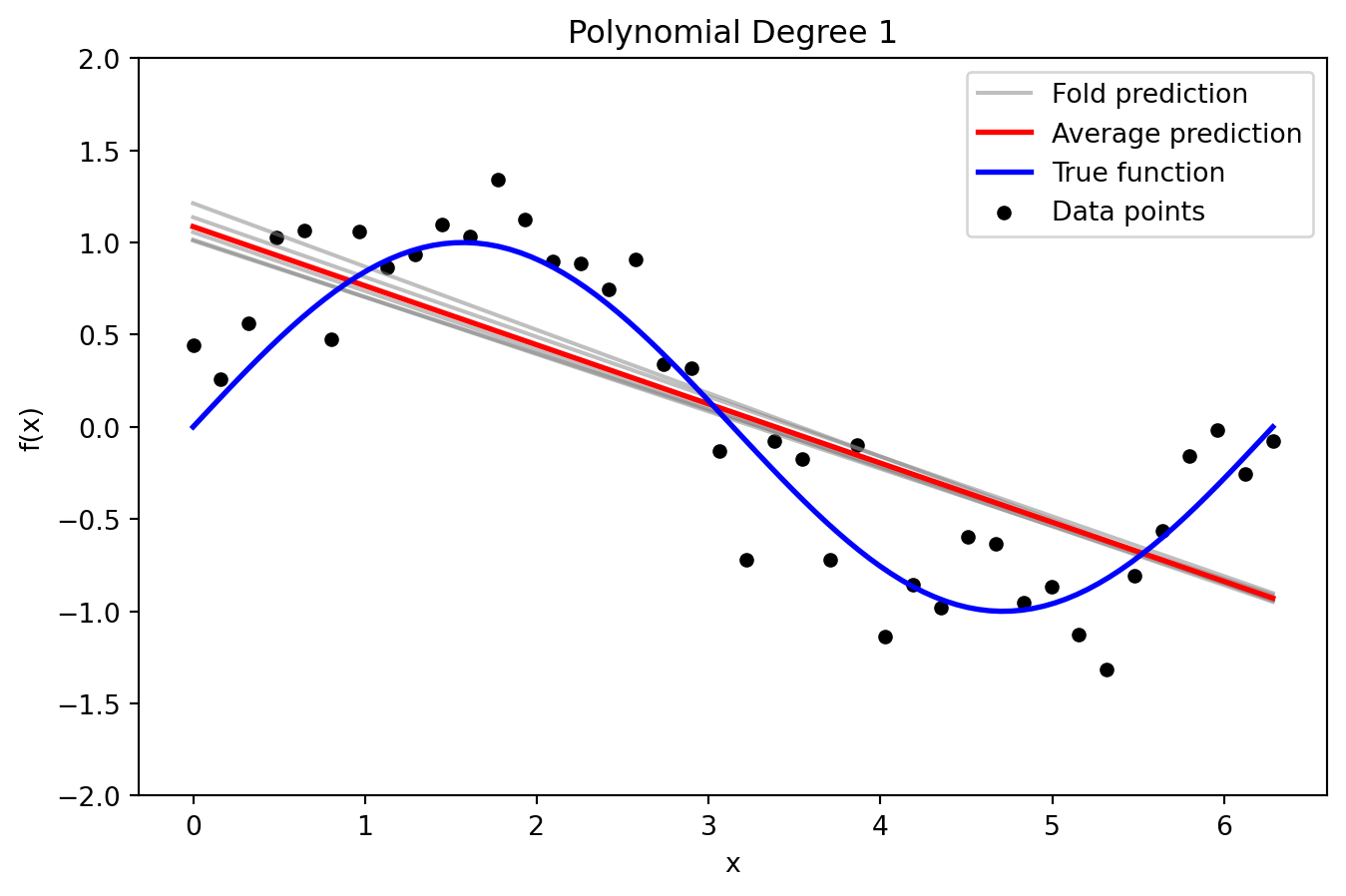
from sklearn.model_selection import KFoldfrom sklearn.metrics import mean_squared_errordef true_function(x):return np.sin(x)def plot_fold_predictions(degree, X, y, X_grid, y_true_grid, n_splits=5, random_state=42):""" For a given polynomial degree, perform KFold cross-validation, plot the individual fold predictions along with the average prediction and the true function (with y-axis limited to [-2, 2]), and return predictions and errors. """ kf = KFold(n_splits=n_splits, shuffle=True, random_state=random_state) fold_predictions = [] # To store predictions on the evaluation grid for each fold fold_errors = [] # To store test errors for each foldfor train_index, test_index in kf.split(X): poly = PolynomialFeatures(degree=degree) X_train_poly = poly.fit_transform(X[train_index]) X_test_poly = poly.transform(X[test_index]) X_grid_poly = poly.transform(X_grid) model = LinearRegression() model.fit(X_train_poly, y[train_index])# Predictions on the dense grid for bias-variance analysis y_pred_grid = model.predict(X_grid_poly) fold_predictions.append(y_pred_grid)# Test error on held-out data y_pred_test = model.predict(X_test_poly) fold_errors.append(mean_squared_error(y[test_index], y_pred_test)) fold_predictions = np.array(fold_predictions) avg_prediction = np.mean(fold_predictions, axis=0)# Plot individual fold predictions with y-axis limited to [-2, 2] plt.figure(figsize=(8, 5))for i inrange(n_splits): plt.plot(X_grid, fold_predictions[i], color='gray', alpha=0.5, label='Fold prediction'if i ==0else"") plt.plot(X_grid, avg_prediction, color='red', linewidth=2, label='Average prediction') plt.plot(X_grid, y_true_grid, color='blue', linewidth=2, label='True function') plt.scatter(X, y, color='black', s=20, label='Data points') plt.ylim(-2, 2) plt.title(f'Polynomial Degree {degree}') plt.xlabel('x') plt.ylabel('f(x)') plt.legend() plt.show()return fold_predictions, avg_prediction, fold_errors# --- Data Generation with Increased Noise and Reduced Sample Size ---np.random.seed(0)n_samples =40# Reduced sample size increases model sensitivity to training dataX = np.linspace(0, 2* np.pi, n_samples).reshape(-1, 1)noise_std =0.25# Increased noise level amplifies prediction variabilityy = true_function(X).ravel() + np.random.normal(0, noise_std, size=n_samples)# Create a dense evaluation grid and compute the true function valuesX_grid = np.linspace(0, 2* np.pi, 100).reshape(-1, 1)y_true_grid = true_function(X_grid).ravel()# --- Plot Individual Fold Predictions for Selected Degrees ---_ = plot_fold_predictions(1, X, y, X_grid, y_true_grid, n_splits=5)
Low Bias, High Variance
Code
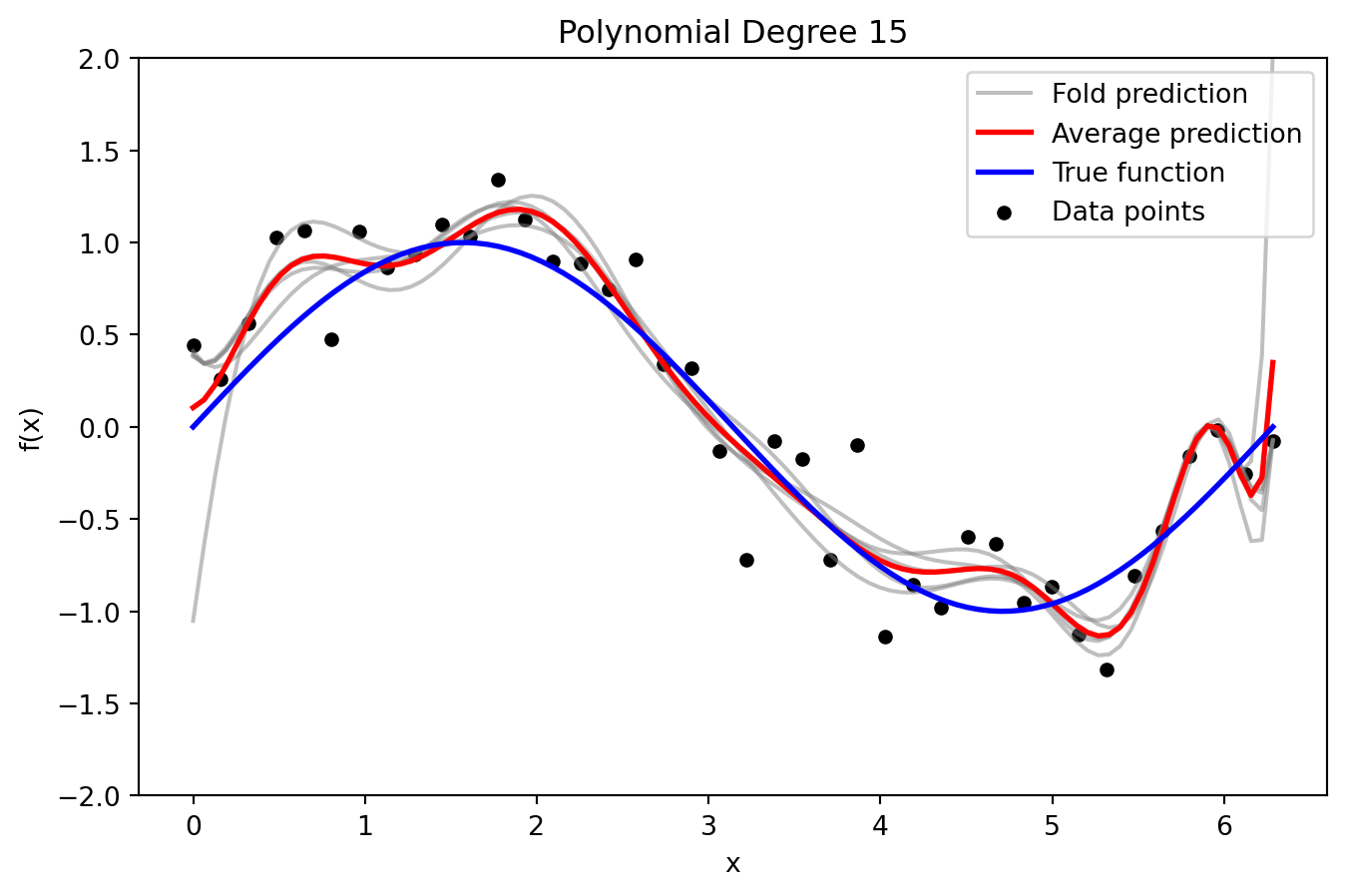
_ = plot_fold_predictions(15, X, y, X_grid, y_true_grid, n_splits=5)
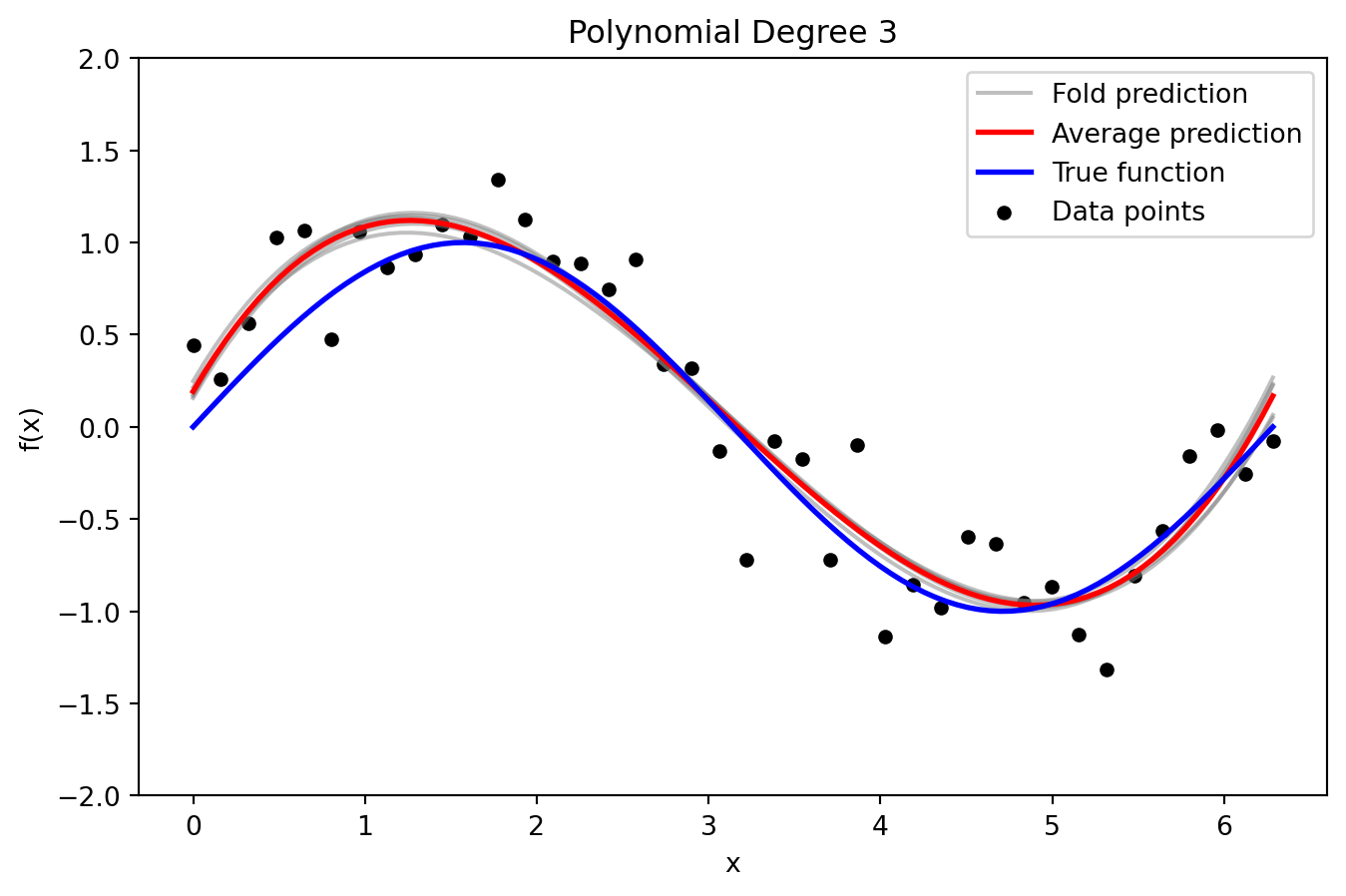
Just Right
Code
_ = plot_fold_predictions(3, X, y, X_grid, y_true_grid, n_splits=5)
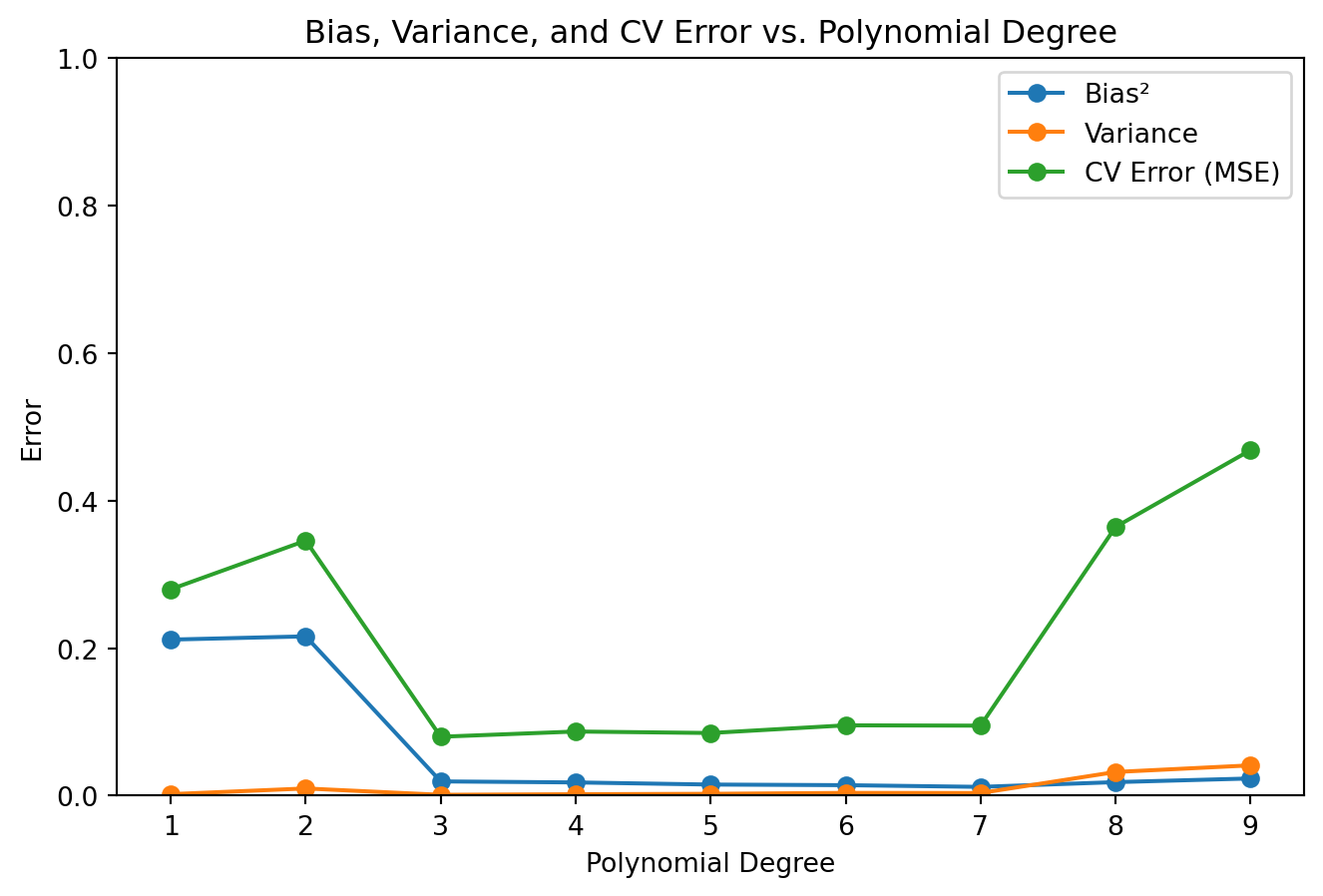
Bias, Variance, and CV Error
Code
# --- Compute Bias², Variance, and CV Error Across Degrees 1 to 10 ---degrees =range(1, 10)bias_list = []variance_list = []cv_error_list = []for degree in degrees: kf = KFold(n_splits=5, shuffle=True, random_state=42) fold_predictions = [] fold_errors = []for train_index, test_index in kf.split(X): poly = PolynomialFeatures(degree=degree) X_train_poly = poly.fit_transform(X[train_index]) X_test_poly = poly.transform(X[test_index]) X_grid_poly = poly.transform(X_grid) model = LinearRegression() model.fit(X_train_poly, y[train_index]) y_pred_grid = model.predict(X_grid_poly) fold_predictions.append(y_pred_grid) y_pred_test = model.predict(X_test_poly) fold_errors.append(mean_squared_error(y[test_index], y_pred_test)) fold_predictions = np.array(fold_predictions) mean_prediction = np.mean(fold_predictions, axis=0)# Bias²: Average squared difference between the average prediction and the true function bias_sq = np.mean((mean_prediction - y_true_grid)**2)# Variance: Average variance of the predictions across the evaluation grid variance = np.mean(np.var(fold_predictions, axis=0))# CV Error: Mean of the MSE on held-out test sets cv_error = np.mean(fold_errors) bias_list.append(bias_sq) variance_list.append(variance) cv_error_list.append(cv_error)# --- Plot Bias², Variance, and CV Error vs. Polynomial Degree ---plt.figure(figsize=(8, 5))plt.plot(degrees, bias_list, marker='o', label='Bias²')plt.plot(degrees, variance_list, marker='o', label='Variance')plt.plot(degrees, cv_error_list, marker='o', label='CV Error (MSE)')plt.title('Bias, Variance, and CV Error vs. Polynomial Degree')plt.xlabel('Polynomial Degree')plt.ylabel('Error')plt.ylim(0, 1)plt.legend()plt.show()
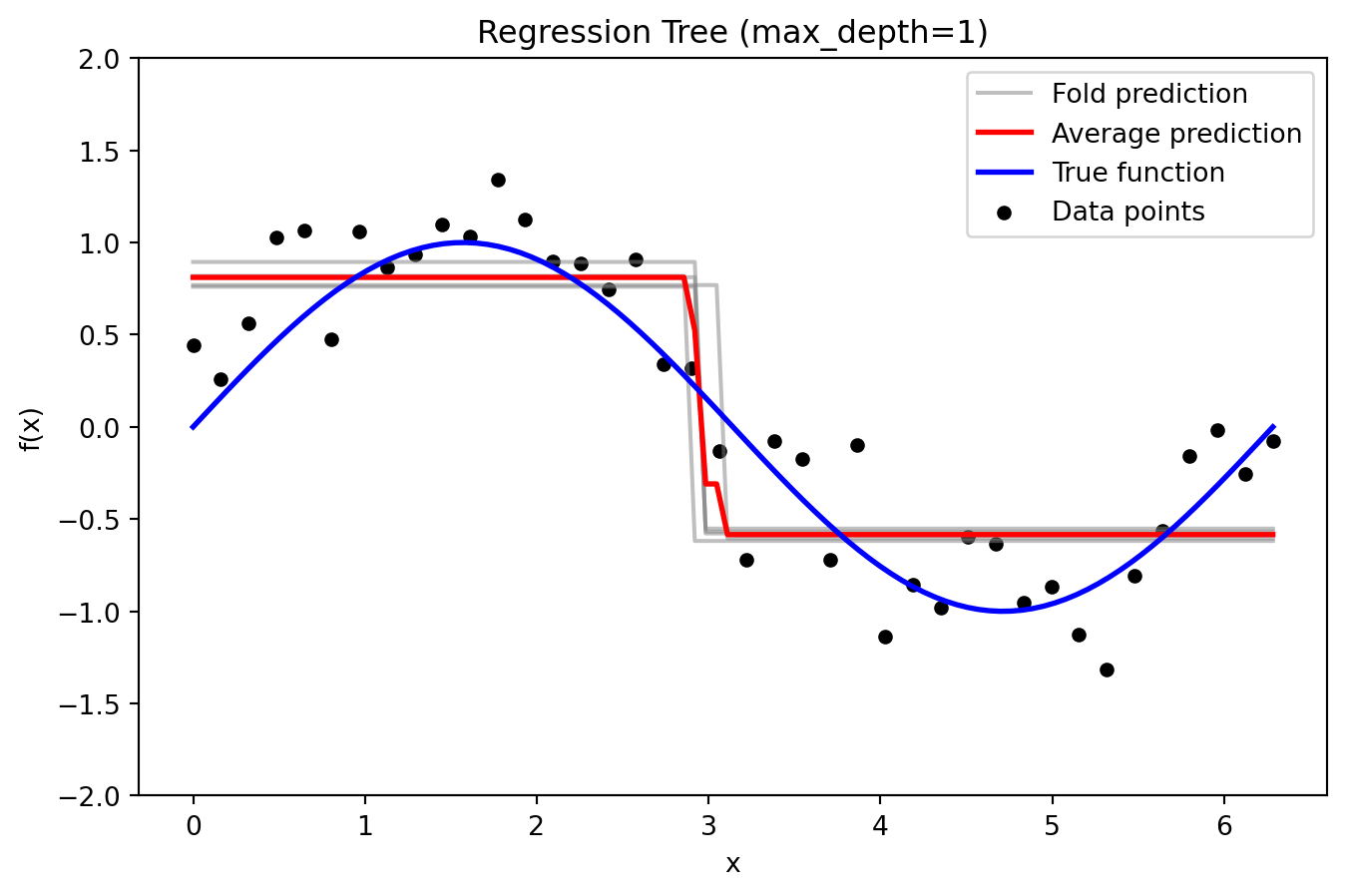
Regression Tree
Code
from sklearn.tree import DecisionTreeRegressordef plot_tree_fold_predictions(max_depth, X, y, X_grid, y_true_grid, n_splits=5, random_state=42):""" For a given tree max_depth, perform KFold cross-validation with a DecisionTreeRegressor, plot the individual fold predictions along with the average prediction and the true function. The y-axis is limited to [-2, 2] for clarity. """ kf = KFold(n_splits=n_splits, shuffle=True, random_state=random_state) fold_predictions = [] # Store predictions on the evaluation grid for each fold fold_errors = [] # Store test errors for each foldfor train_index, test_index in kf.split(X): X_train = X[train_index] X_test = X[test_index] model = DecisionTreeRegressor(max_depth=max_depth, random_state=random_state) model.fit(X_train, y[train_index])# Prediction on a dense evaluation grid y_pred_grid = model.predict(X_grid) fold_predictions.append(y_pred_grid)# Test error on held-out data y_pred_test = model.predict(X_test) fold_errors.append(mean_squared_error(y[test_index], y_pred_test)) fold_predictions = np.array(fold_predictions) avg_prediction = np.mean(fold_predictions, axis=0) plt.figure(figsize=(8, 5))for i inrange(n_splits): plt.plot(X_grid, fold_predictions[i], color='gray', alpha=0.5, label='Fold prediction'if i ==0else"") plt.plot(X_grid, avg_prediction, color='red', linewidth=2, label='Average prediction') plt.plot(X_grid, y_true_grid, color='blue', linewidth=2, label='True function') plt.scatter(X, y, color='black', s=20, label='Data points') plt.ylim(-2, 2) plt.title(f'Regression Tree (max_depth={max_depth})') plt.xlabel('x') plt.ylabel('f(x)') plt.legend() plt.show()return fold_predictions, avg_prediction, fold_errors# --- Plot Individual Fold Predictions for Selected Tree Depths ---_ = plot_tree_fold_predictions(1, X, y, X_grid, y_true_grid, n_splits=5)
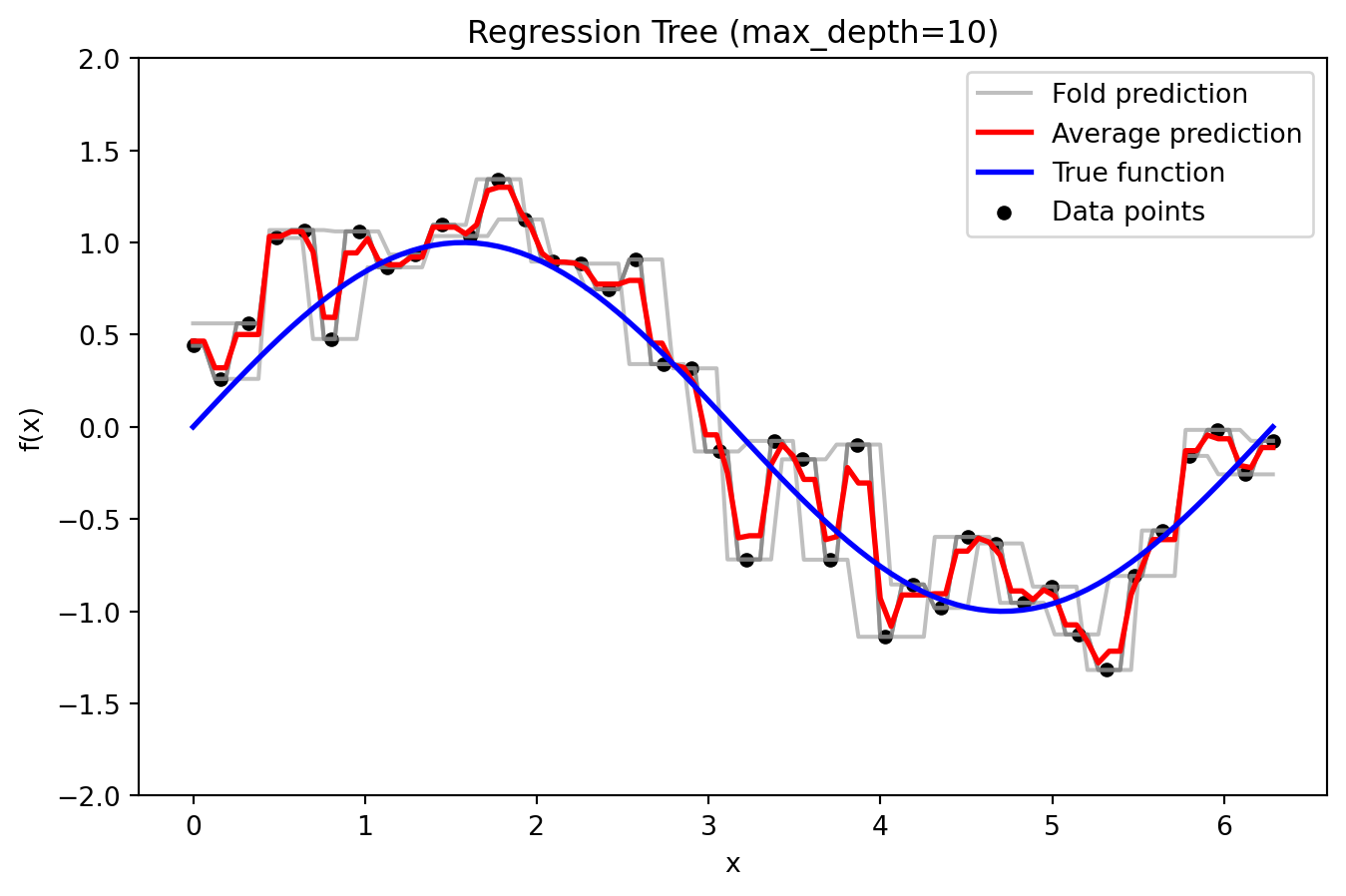
Regression Tree
Code
_ = plot_tree_fold_predictions(10, X, y, X_grid, y_true_grid, n_splits=5)
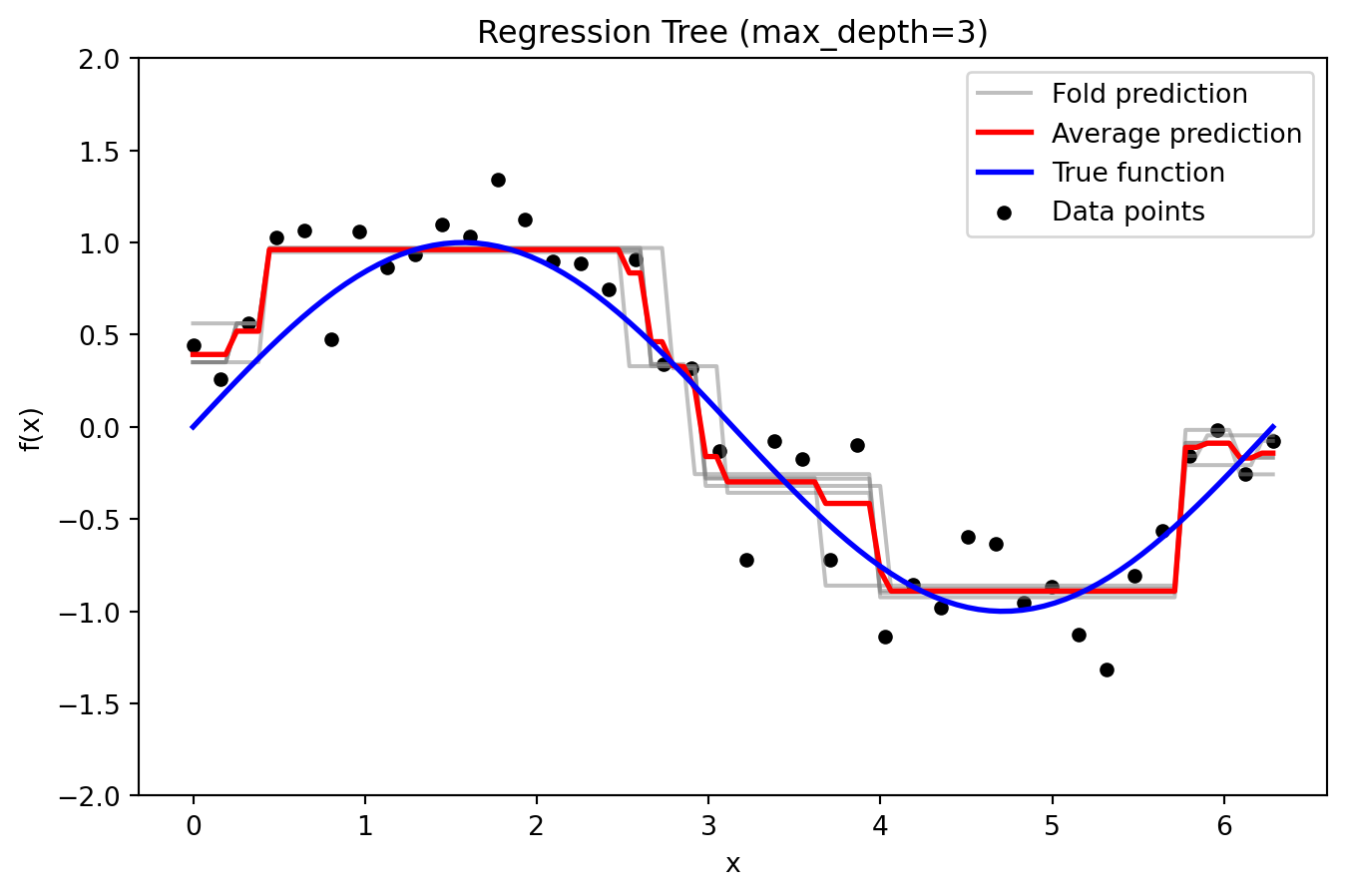
Regression Tree
Code
_ = plot_tree_fold_predictions(3, X, y, X_grid, y_true_grid, n_splits=5)
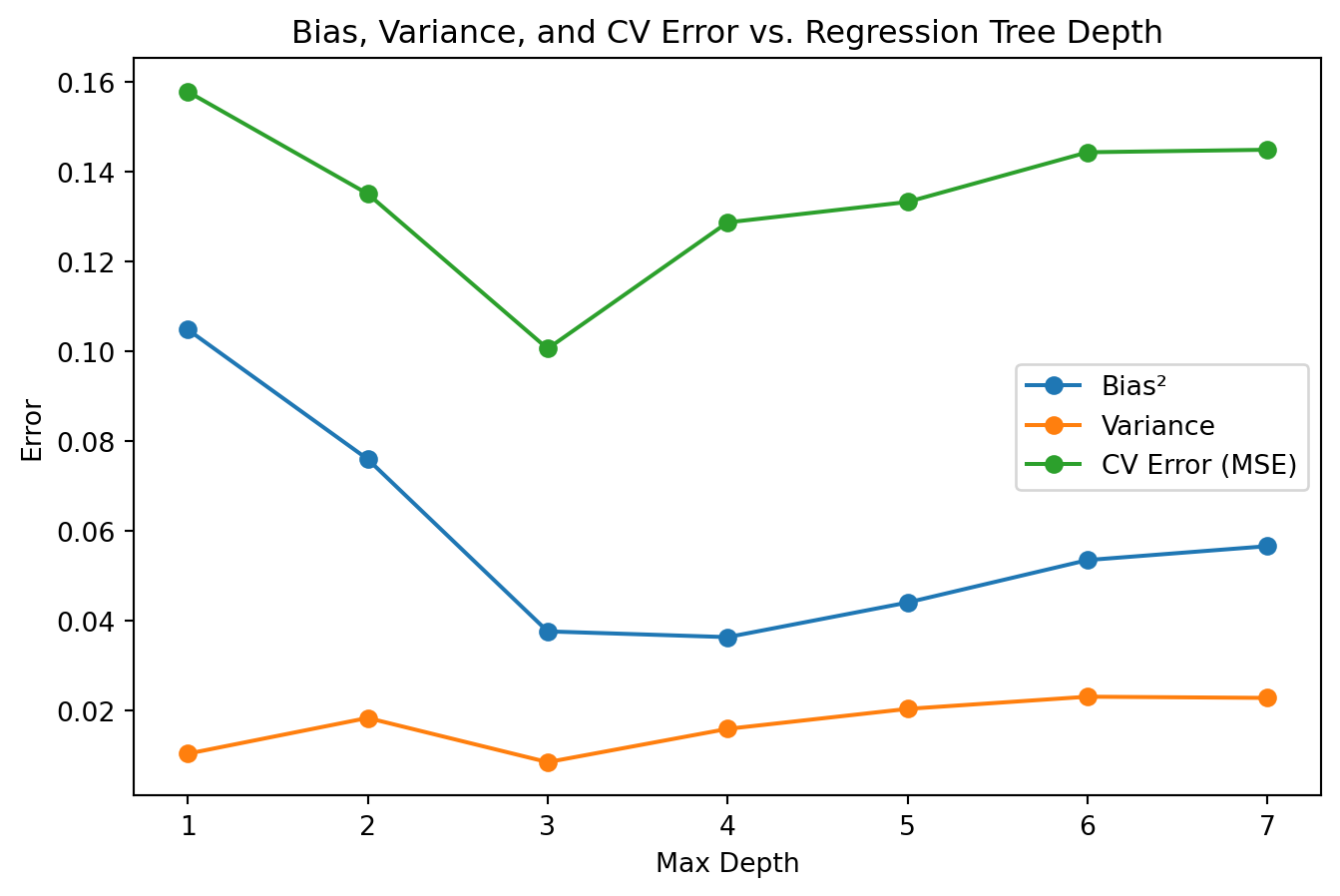
Bias, Variance, and CV Error
Code
# --- Compute Bias², Variance, and CV Error vs. Tree Depth ---max_depths =range(1, 8)bias_list = []variance_list = []cv_error_list = []for depth in max_depths: kf = KFold(n_splits=5, shuffle=True, random_state=42) fold_predictions = [] fold_errors = []for train_index, test_index in kf.split(X): X_train = X[train_index] X_test = X[test_index] model = DecisionTreeRegressor(max_depth=depth, random_state=42) model.fit(X_train, y[train_index]) y_pred_grid = model.predict(X_grid) fold_predictions.append(y_pred_grid) y_pred_test = model.predict(X_test) fold_errors.append(mean_squared_error(y[test_index], y_pred_test)) fold_predictions = np.array(fold_predictions) mean_prediction = np.mean(fold_predictions, axis=0)# Bias²: Mean squared difference between the average prediction and the true function bias_sq = np.mean((mean_prediction - y_true_grid)**2)# Variance: Average variance of predictions across the evaluation grid variance = np.mean(np.var(fold_predictions, axis=0))# CV Error: Average test error over folds cv_error = np.mean(fold_errors) bias_list.append(bias_sq) variance_list.append(variance) cv_error_list.append(cv_error)plt.figure(figsize=(8, 5))plt.plot(max_depths, bias_list, marker='o', label='Bias²')plt.plot(max_depths, variance_list, marker='o', label='Variance')plt.plot(max_depths, cv_error_list, marker='o', label='CV Error (MSE)')plt.title('Bias, Variance, and CV Error vs. Regression Tree Depth')plt.xlabel('Max Depth')plt.ylabel('Error')# plt.ylim(0, 1)plt.legend()plt.show()
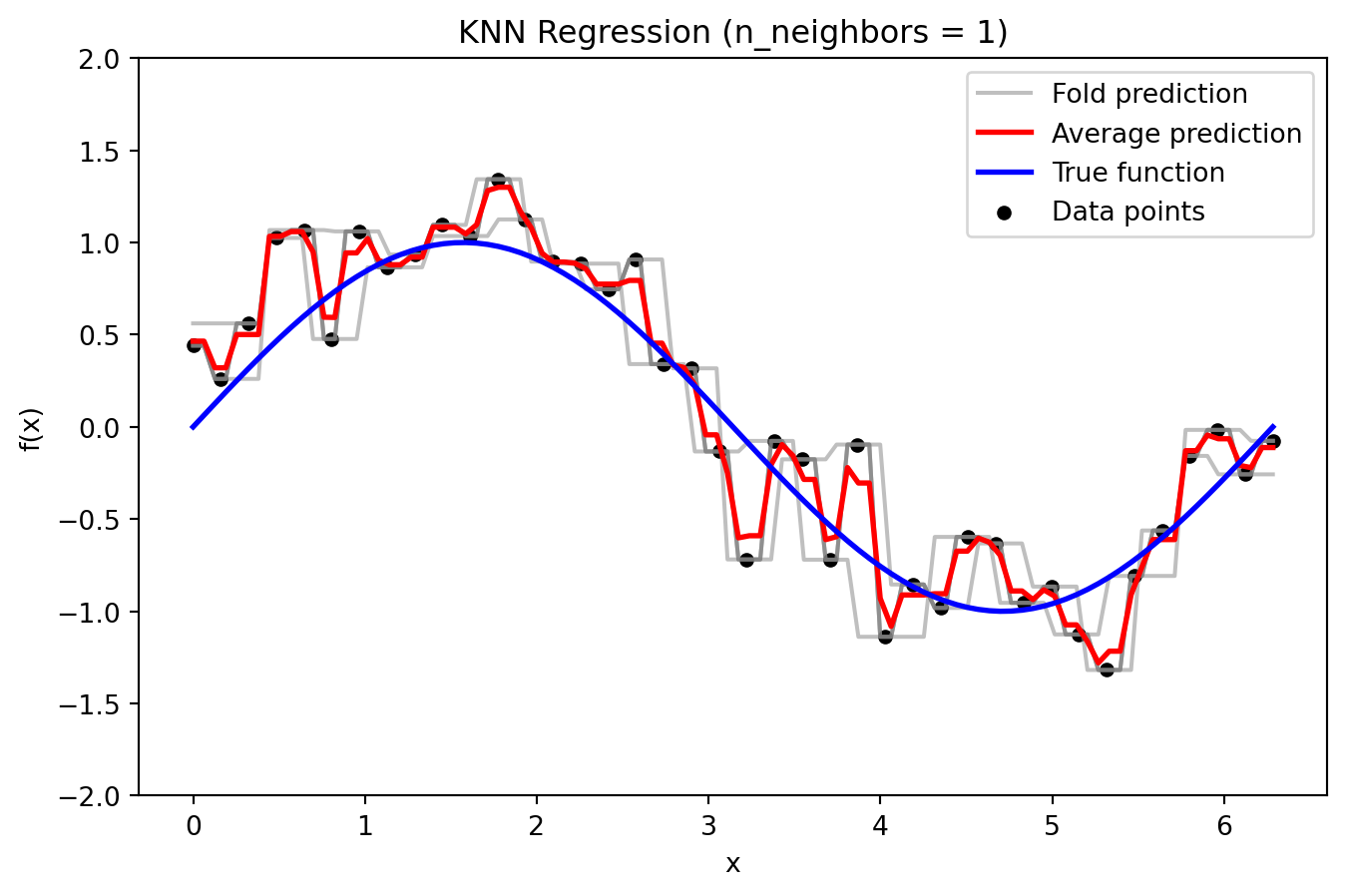
KNN Regression
Code
from sklearn.neighbors import KNeighborsRegressordef plot_knn_fold_predictions(n_neighbors, X, y, X_grid, y_true_grid, n_splits=5, random_state=42):""" For a given number of neighbors, perform KFold cross-validation using KNeighborsRegressor, plot the predictions from each fold along with the average prediction and the true function. The y-axis is limited to [-2, 2] for clarity. """ kf = KFold(n_splits=n_splits, shuffle=True, random_state=random_state) fold_predictions = [] # Store predictions on the evaluation grid for each fold fold_errors = [] # Store test errors for each foldfor train_index, test_index in kf.split(X): X_train = X[train_index] X_test = X[test_index] model = KNeighborsRegressor(n_neighbors=n_neighbors) model.fit(X_train, y[train_index])# Prediction on a dense evaluation grid for bias-variance analysis y_pred_grid = model.predict(X_grid) fold_predictions.append(y_pred_grid)# Test error on held-out data y_pred_test = model.predict(X_test) fold_errors.append(mean_squared_error(y[test_index], y_pred_test)) fold_predictions = np.array(fold_predictions) avg_prediction = np.mean(fold_predictions, axis=0)# Plot individual fold predictions plt.figure(figsize=(8, 5))for i inrange(n_splits): plt.plot(X_grid, fold_predictions[i], color='gray', alpha=0.5, label='Fold prediction'if i ==0else"") plt.plot(X_grid, avg_prediction, color='red', linewidth=2, label='Average prediction') plt.plot(X_grid, y_true_grid, color='blue', linewidth=2, label='True function') plt.scatter(X, y, color='black', s=20, label='Data points') plt.ylim(-2, 2) plt.title(f'KNN Regression (n_neighbors = {n_neighbors})') plt.xlabel('x') plt.ylabel('f(x)') plt.legend() plt.show()return fold_predictions, avg_prediction, fold_errors# --- Plot Individual Fold Predictions for Selected Values of k ---_ = plot_knn_fold_predictions(1, X, y, X_grid, y_true_grid, n_splits=5)
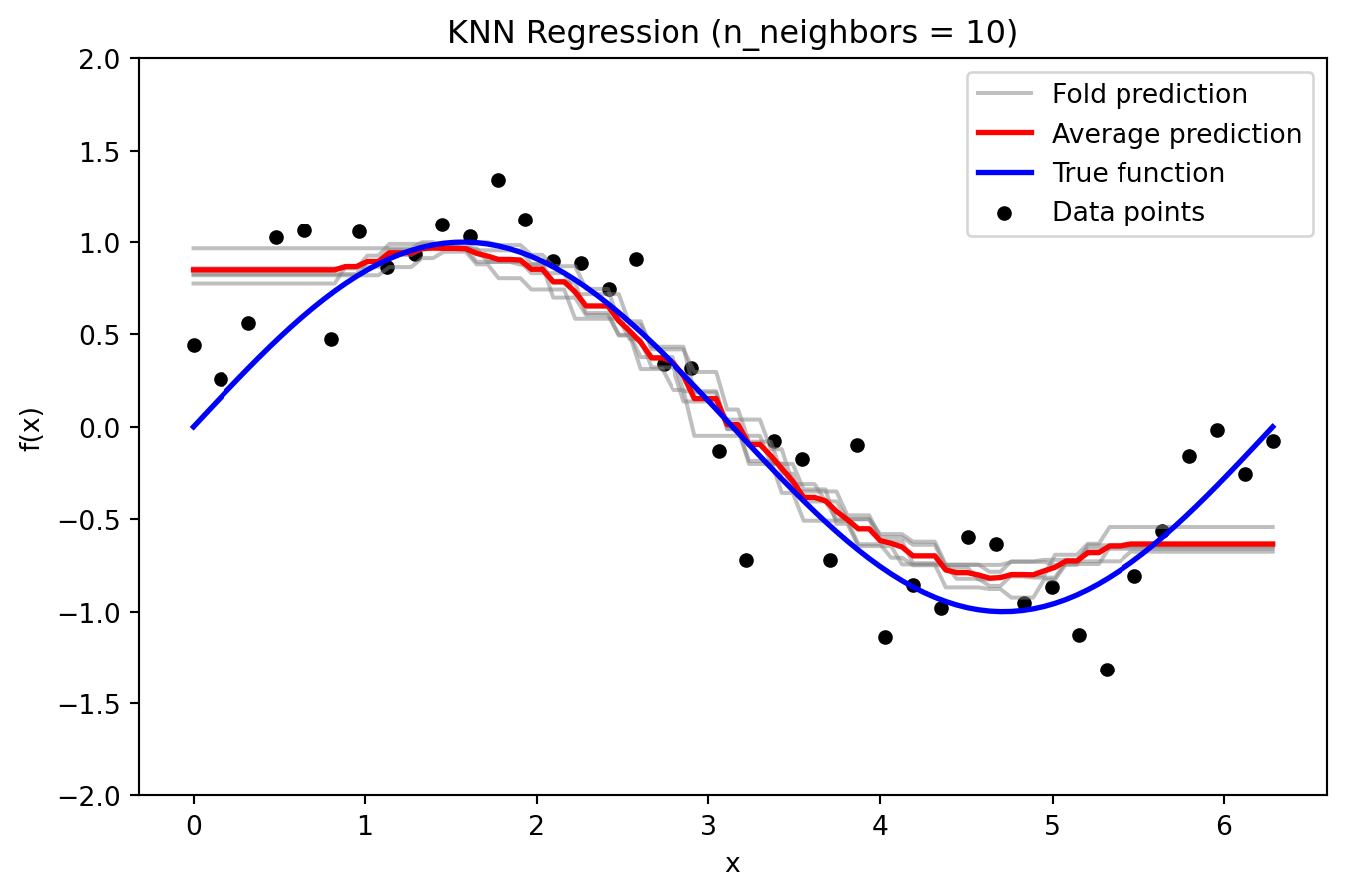
KNN Regression
Code
_ = plot_knn_fold_predictions(10, X, y, X_grid, y_true_grid, n_splits=5)
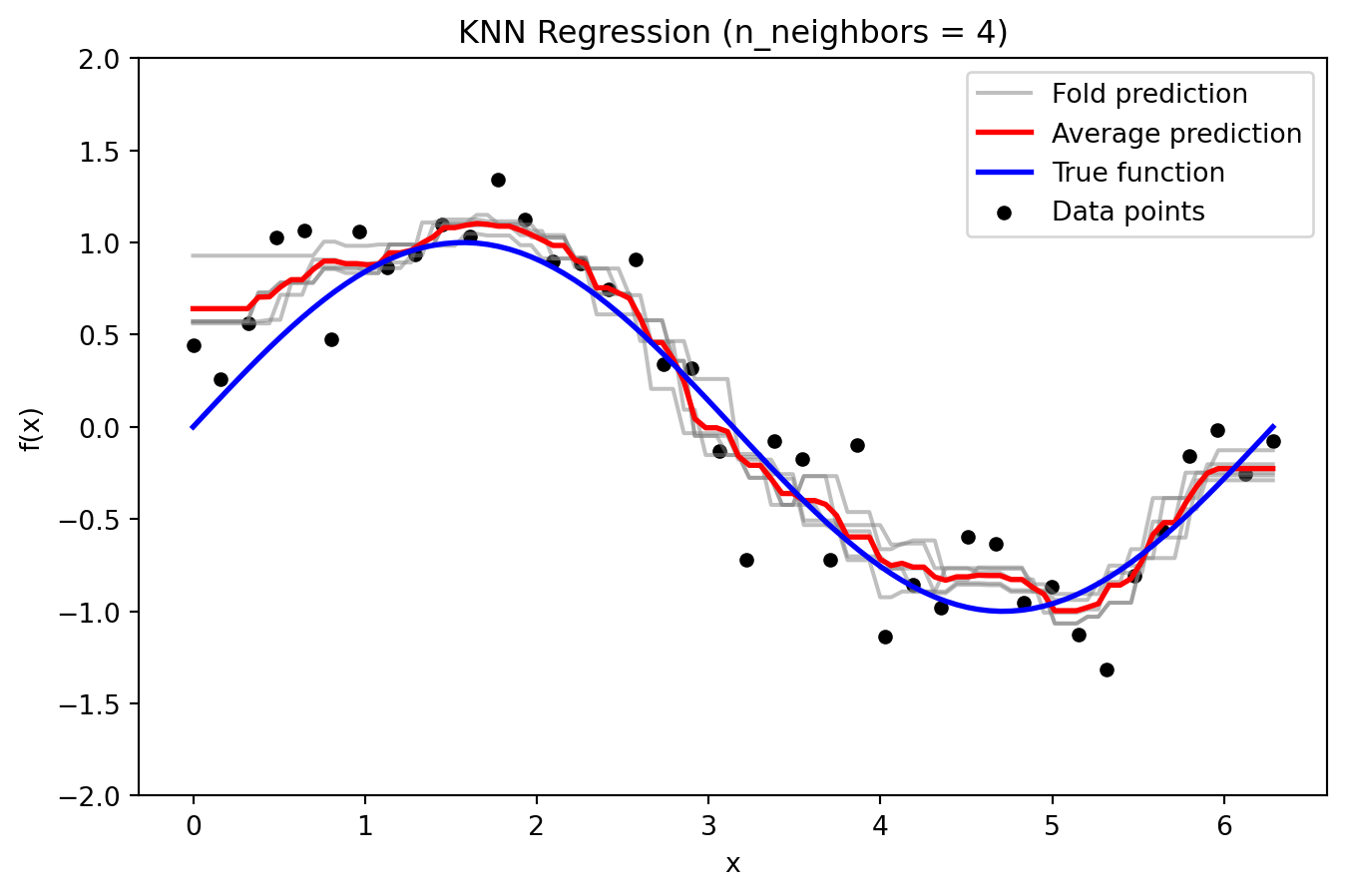
KNN Regression
Code
_ = plot_knn_fold_predictions(4, X, y, X_grid, y_true_grid, n_splits=5)
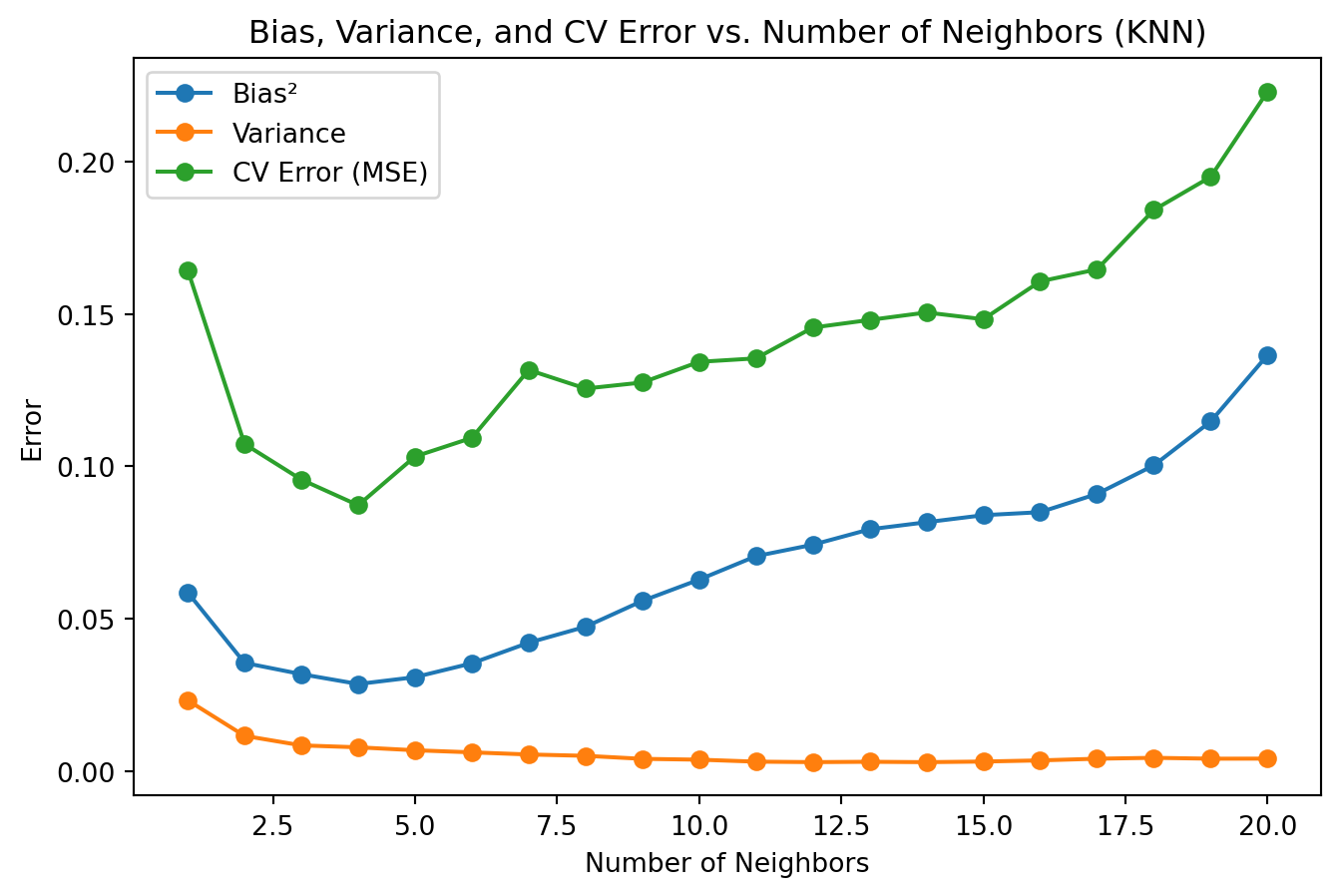
Bias, Variance, and CV Error
Code
# --- Compute Bias², Variance, and CV Error vs. Number of Neighbors ---neighbors_range =range(1, 21) # Vary k from 1 to 20bias_list = []variance_list = []cv_error_list = []for k in neighbors_range: kf = KFold(n_splits=5, shuffle=True, random_state=42) fold_predictions = [] fold_errors = []for train_index, test_index in kf.split(X): X_train = X[train_index] X_test = X[test_index] model = KNeighborsRegressor(n_neighbors=k) model.fit(X_train, y[train_index]) y_pred_grid = model.predict(X_grid) fold_predictions.append(y_pred_grid) y_pred_test = model.predict(X_test) fold_errors.append(mean_squared_error(y[test_index], y_pred_test)) fold_predictions = np.array(fold_predictions) mean_prediction = np.mean(fold_predictions, axis=0)# Bias²: Mean squared difference between the average prediction and the true function bias_sq = np.mean((mean_prediction - y_true_grid)**2)# Variance: Average variance of predictions across the evaluation grid variance = np.mean(np.var(fold_predictions, axis=0))# CV Error: Average MSE on the held-out test sets cv_error = np.mean(fold_errors) bias_list.append(bias_sq) variance_list.append(variance) cv_error_list.append(cv_error)# --- Plot Bias², Variance, and CV Error vs. Number of Neighbors ---plt.figure(figsize=(8, 5))plt.plot(neighbors_range, bias_list, marker='o', label='Bias²')plt.plot(neighbors_range, variance_list, marker='o', label='Variance')plt.plot(neighbors_range, cv_error_list, marker='o', label='CV Error (MSE)')plt.title('Bias, Variance, and CV Error vs. Number of Neighbors (KNN)')plt.xlabel('Number of Neighbors')plt.ylabel('Error')# plt.ylim(0, 1)plt.legend()plt.show()
Prologue
Summary
Evaluated model complexity and its impact on performance.
Illustrated underfitting, overfitting, and the bias–variance tradeoff.
Demonstrated learning curves and cross-validation across diverse models (linear, polynomial, tree, KNN, deep nets).
Next lecture
Machine Learning Engineering
References
Ambroise, Christophe, and Geoffrey J. McLachlan. 2002. “Selection bias in gene extraction on the basis of microarray gene-expression data.”Proceedings of the National Academy of Sciences 99 (10): 6562–66. https://doi.org/10.1073/pnas.102102699.
Chollet, François. 2017. Deep Learning with Python. Manning Publications.
Géron, Aurélien. 2022. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 3rd ed. O’Reilly Media, Inc.
Libbrecht, Maxwell W, and William Stafford Noble. 2015. “Machine learning applications in genetics and genomics.”Nature Reviews Genetics 16 (6): 321–32. https://doi.org/10.1038/nrg3920.
Statnikov, Alexander, Constantin F. Aliferis, Ioannis Tsamardinos, Douglas Hardin, and Shawn Levy. 2004. “A comprehensive evaluation of multicategory classification methods for microarray gene expression cancer diagnosis.”Bioinformatics 21 (5): 631–43. https://doi.org/10.1093/bioinformatics/bti033.