This lecture provides an in‐depth introduction to deep learning training with a focus on its applications in bioinformatics. It covers the key models and repositories used in genomics—such as Kipoi, Hugging Face, and DragoNN—while explaining the fundamental components of neural networks including layers, activation functions, and the universal approximation theorem. The lecture then delves into the mechanics of training neural networks, detailing the forward pass, backpropagation, gradient descent, and techniques for overcoming challenges like vanishing and exploding gradients through proper weight initialization, dropout, and early stopping.
Learning Objectives
Understand the core architecture and components of deep neural networks.
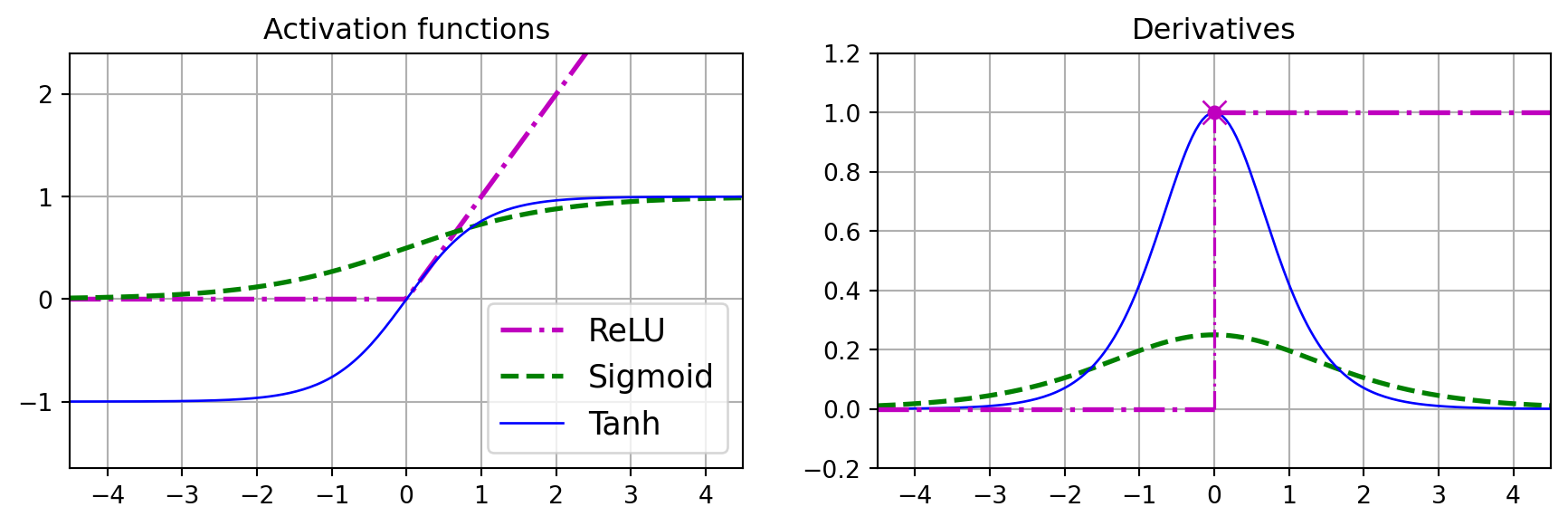
Explain the role and differences among activation functions and their impact on training.
Describe the backpropagation algorithm and its significance in updating network weights.
Identify common challenges in training deep networks and the strategies used to overcome them.
Recognize key genomics-specific deep learning resources and repositories.
Models for Genomics
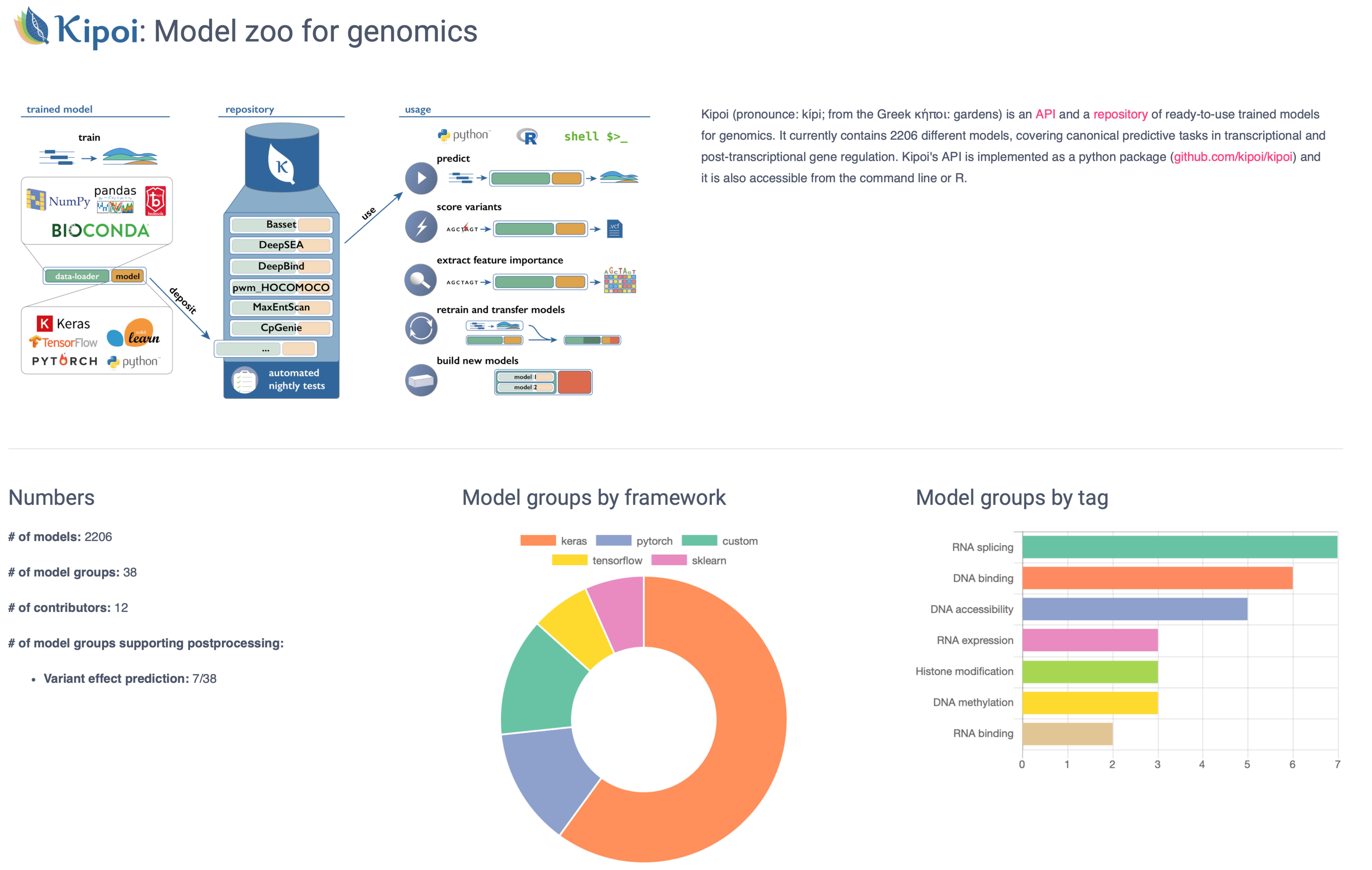
Kipoi
Kipoi (Continued)
import kipoimodel = kipoi.get_model("Basset") # load the modelmodel.predict_on_batch(x)## ormodel.pipeline.predict(dict(fasta_file="hg19.fa", intervals_file="intervals.bed"))
Hugging Face, Inc.
A private company develops computational tools for machine learning applications, known for its NLP-focused transformers library.
It provides a platform for sharing machine learning models and datasets, featuring hundreds of resources related to DNA, RNA, protein, and biology.
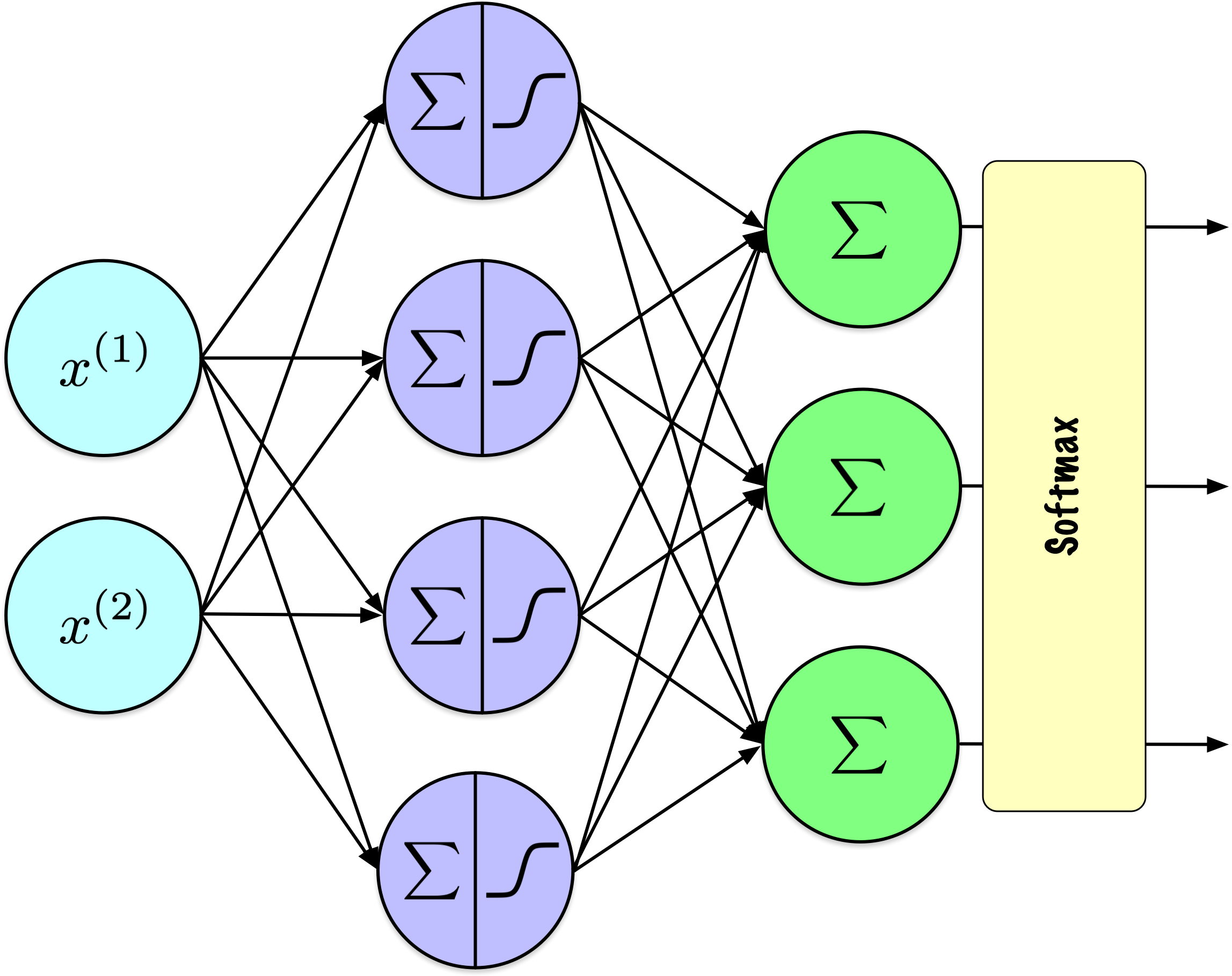
Deep learning (DL) is a machine learning technique that can be applied to supervised learning (including regression and classification), unsupervised learning, and reinforcement learning.
Inspired from the structure and function of biological neural networks found in animals.
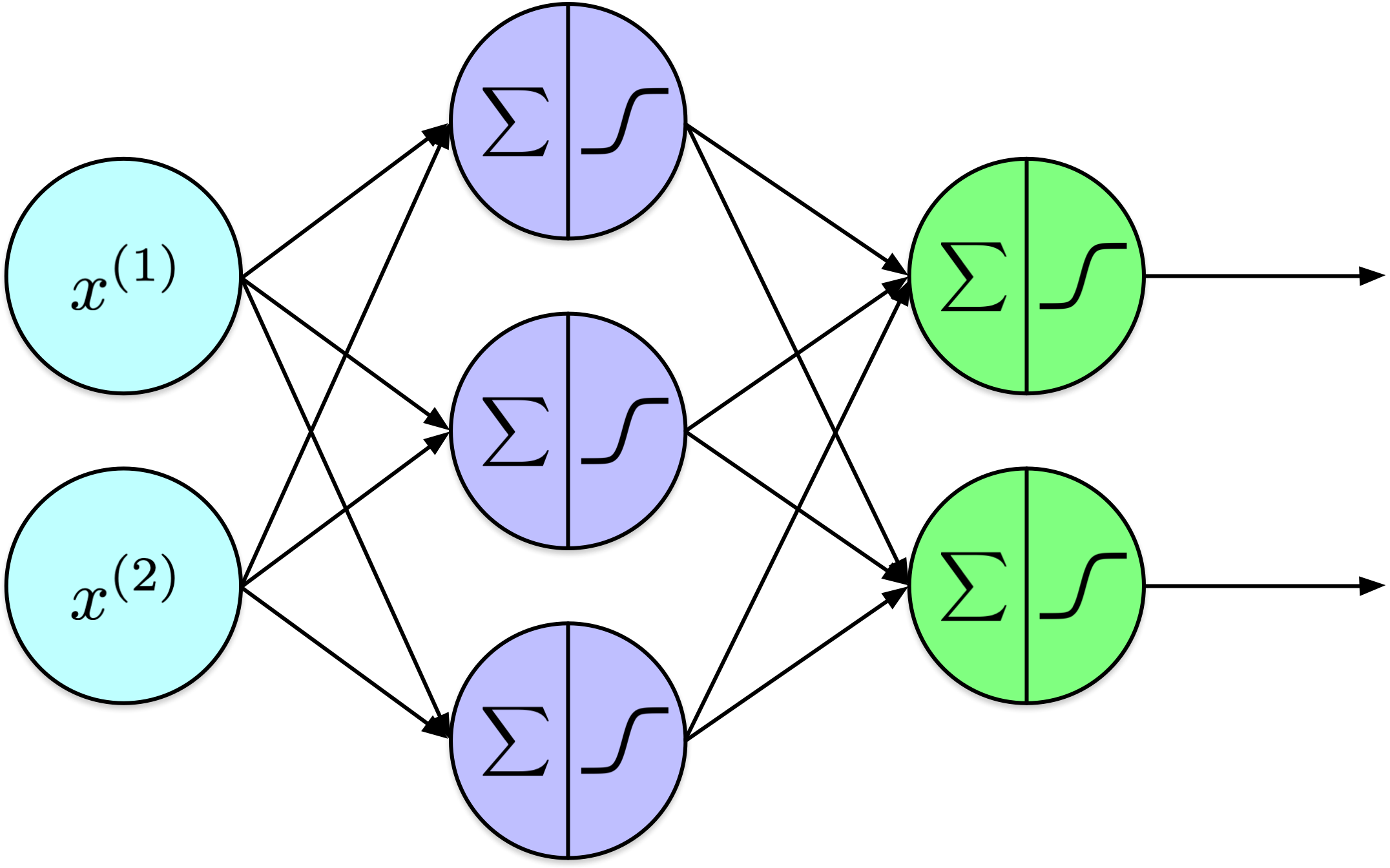
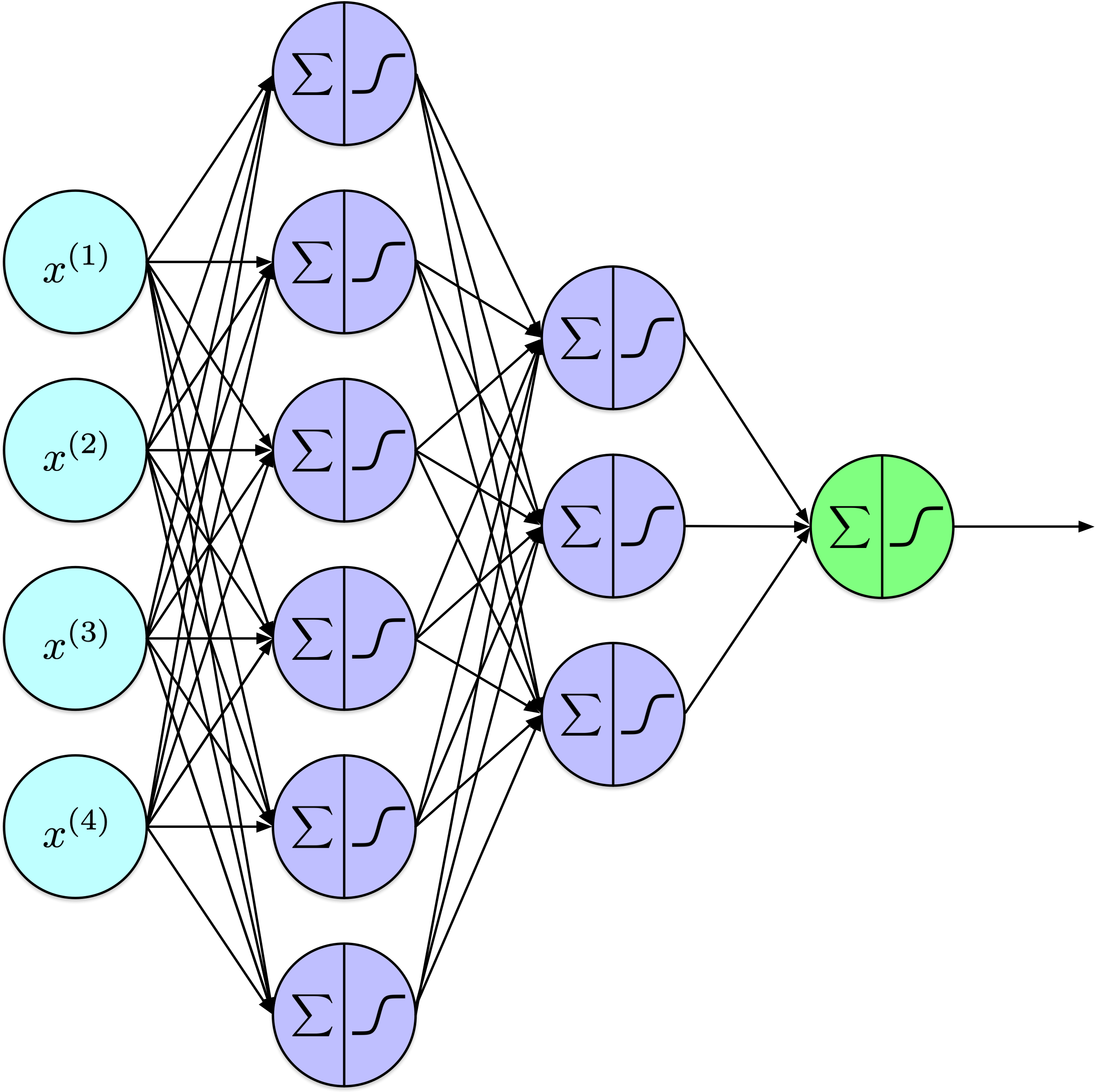
Comprises interconnected neurons (or units) arranged into layers.
The universal approximation theorem states that a feedforward neural network with a single hidden layer containing a finite number of neurons can approximate any continuous function on a compact subset of \(\mathbb{R}^n\), given appropriate weights and activation functions.
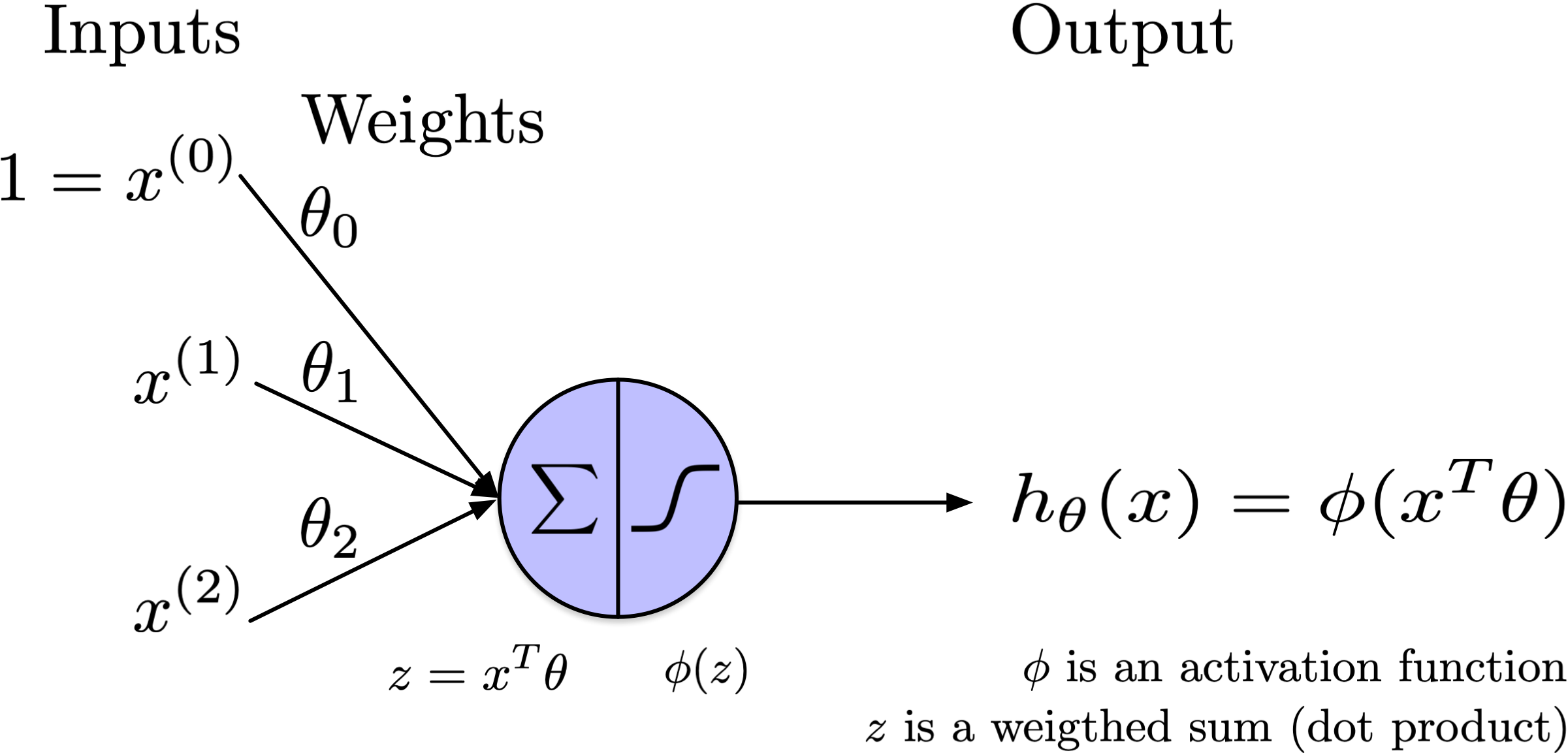
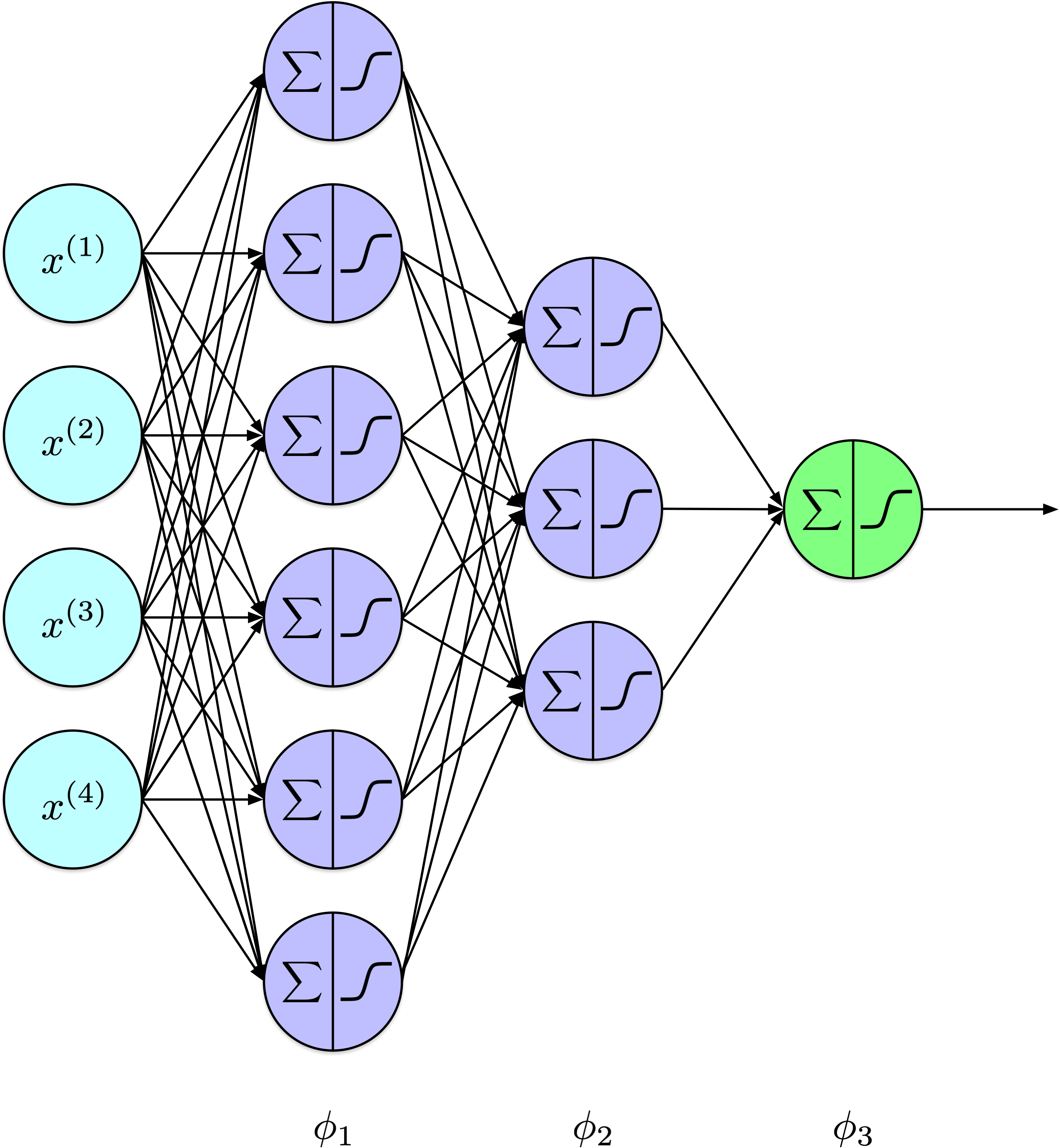
Notation
Notation
A two-layer perceptron computes:
\[
y = \phi_2(\phi_1(X))
\]
where
\[
\phi_l(Z) = \phi(W_lZ_l + b_l)
\]
Notation
A 3-layer perceptron computes:
\[
y = \phi_3(\phi_2(\phi_1(X)))
\]
where
\[
\phi_l(Z) = \phi(W_lZ_l + b_l)
\]
Notation
A \(k\)-layer perceptron computes:
\[
y = \phi_k( \ldots \phi_2(\phi_1(X)) \ldots )
\]
where
\[
\phi_l(Z) = \phi(W_lZ_l + b_l)
\]
Backpropagation
3Blue1Brown
Backpropagation
Learning representations by back-propagating errors
David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams
We describe a new learning procedure, back-propagation, for networks of neurone-like units. The procedure repeatedly adjusts the weights of the connections in the network so as to minimize a measure of the difference between the actual output vector of the net and the desired output vector. As a result of the weight adjustments, internal ‘hidden’ units which are not part of the input or output come to represent important features of the task domain, and the regularities in the task are captured by the interactions of these units. The ability to create useful new features distinguishes back-propagation from earlier, simpler methods such as the perceptron-convergence procedure.
Before the Backpropagation
Limitations, such as the inability to solve the XOR classification task, essentially stalled research on neural networks.
The perceptron was limited to a single layer, and there was no known method for training a multi-layer perceptron.
Single-layer perceptrons are limited to solving classification tasks that are linearly separable.
Backpropagation: Contributions
The model employs mean squared error as its loss function.
Gradient descent is used to minimize loss.
A sigmoid activation function is used instead of a step function, as its derivative provides valuable information for gradient descent.
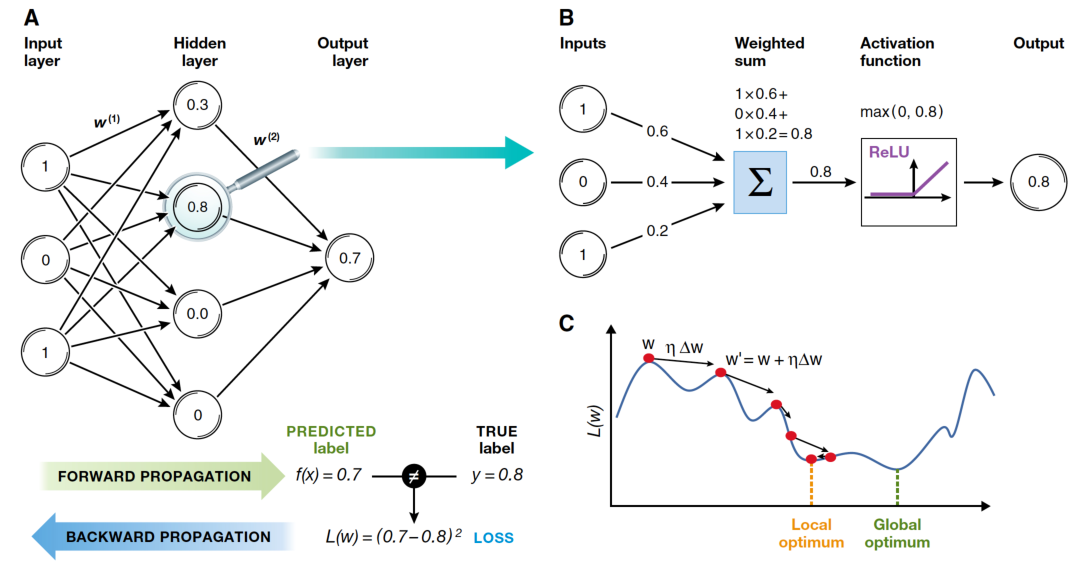
Shows how updating internal weights using a two-pass algorithm consisting of a forward pass and a backward pass.
Enables training multi-layer perceptrons.
Backpropagation: Top Level
Initialization
Forward Pass
Compute Loss
Backward Pass (Backpropagation)
Repeat 2 to 5.
Backpropagation: 1. Initialization
Initialize the weights and biases of the neural network.
Zero Initialization
All weights are initialized to zero.
Symmetry problems, all neurons produce identical outputs, preventing effective learning.
Random Initialization
Weights are initialized randomly, often using a uniform or normal distribution.
Breaks the symmetry between neurons, allowing them to learn.
If not scaled properly, leads to slow convergence or vanishing/exploding gradients.
Backpropagation: 2. Forward Pass
For each example in the training set (or in a mini-batch):
Input Layer: Pass input features to first layer.
Hidden Layers: For each hidden layer, compute the activations (output) by applying the weighted sum of inputs plus bias, followed by an activation function (e.g., sigmoid, ReLU).
Output Layer: Same process as hidden layers. Output layer activations represent the predicted values.
Backpropagation: 3. Compute Loss
Calculate the loss (error) using a suitable loss function by comparing the predicted values to the actual target values.
Backpropagation: 4. Backward Pass
Output Layer: Compute the gradient of the loss with respect to the output layer’s weights and biases using the chain rule of calculus.
Hidden Layers: Propagate the error backward through the network, layer by layer. For each layer, compute the gradient of the loss with respect to the weights and biases. Use the derivative of the activation function to help calculate these gradients.
Update Weights and Biases: Adjust the weights and biases using the calculated gradients and a learning rate, which determines the step size for each update.
Key Concepts
Activation Functions: Functions like sigmoid, ReLU, and tanh introduce non-linearity, which allows the network to learn complex patterns.
Learning Rate: A hyperparameter that controls how much to change the model in response to the estimated error each time the model weights are updated.
Gradient Descent: An optimization algorithm used to minimize the loss function by iteratively moving towards the steepest descent as defined by the negative of the gradient.
Summary
Training
Vanishing Gradients
Vanishing gradient problem: Gradients become too small, hindering weight updates.
Stalled neural network research (again) in early 2000s.
Sigmoid and its derivative (range: 0 to 0.25) were key factors.
Common initialization: Weights/biases from \(\mathcal{N}(0, 1)\) contributed to the issue.
Glorot and Bengio (2010) shed light on the problems.
Vanishing Gradients: Solutions
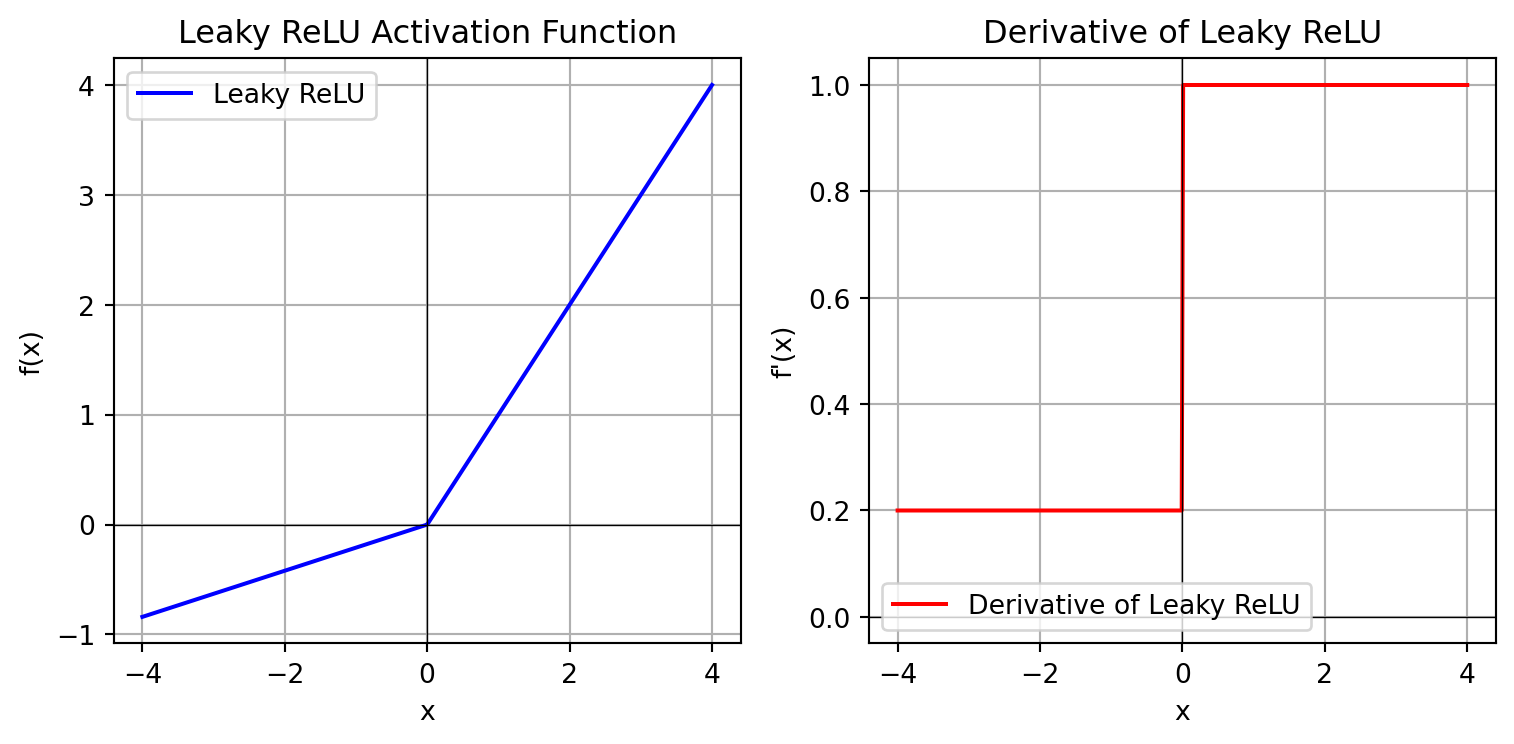
Alternative activation functions: Rectified Linear Unit (ReLU) and its variants (e.g., Leaky ReLU, Parametric ReLU, and Exponential Linear Unit).
Weight Initialization: Xavier (Glorot) or He initialization.
He Initialization
A similar but slightly different initialization method design to work with ReLU, as well as Leaky ReLU, ELU, GELU, Swish, and Mish.
Ensure that the initialization method matches the chosen activation function.
Randomly initializing the weights1 is sufficient to break symmetry in a neural network, allowing the bias terms to be set to zero without impacting the network’s ability to learn effectively.
Activation Function: Leaky ReLU
Code
import numpy as npimport matplotlib.pyplot as plt# Define the Leaky ReLU functiondef leaky_relu(x, alpha=0.21):return np.where(x >0, x, alpha * x)# Define the derivative of the Leaky ReLU functiondef leaky_relu_derivative(x, alpha=0.2):return np.where(x >0, 1, alpha)# Generate a range of input valuesx_values = np.linspace(-4, 4, 400)# Compute the Leaky ReLU and its derivativeleaky_relu_values = leaky_relu(x_values)leaky_relu_derivative_values = leaky_relu_derivative(x_values)# Create the plotplt.figure(figsize=(8, 4))# Plot the Leaky ReLUplt.subplot(1, 2, 1)plt.plot(x_values, leaky_relu_values, label='Leaky ReLU', color='blue')plt.title('Leaky ReLU Activation Function')plt.xlabel('x')plt.ylabel('f(x)')plt.grid(True)plt.axhline(0, color='black',linewidth=0.5)plt.axvline(0, color='black',linewidth=0.5)plt.legend()# Plot the derivative of the Leaky ReLUplt.subplot(1, 2, 2)plt.plot(x_values, leaky_relu_derivative_values, label='Derivative of Leaky ReLU', color='red')plt.title('Derivative of Leaky ReLU')plt.xlabel('x')plt.ylabel("f'(x)")plt.grid(True)plt.axhline(0, color='black',linewidth=0.5)plt.axvline(0, color='black',linewidth=0.5)plt.legend()# Show the plotsplt.tight_layout()plt.show()
Output Layer
Output Layer: Regression Task
# of output neurons:
1 per dimension
Output layer activation function:
None, ReLU/softplus, if positive, sigmoid/tanh, if bounded
1 if binary, 1 per class, if multi-label or multiclass.
Output layer activation function:
sigmoid, if binary or multi-label, softmax if multi-class.
Loss function:
cross-entropy
Softmax
Softmax
The softmax function is an activation function used in multi-class classification problems to convert a vector of raw scores into probabilities that sum to 1.
Given a vector \(\mathbf{z} = [z_1, z_2, \ldots, z_n]\):
where \(\sigma(\mathbf{z})_i\) is the probability of the \(i\)-th class, and \(n\) is the number of classes.
Softmax
\(z_1\)
\(z_2\)
\(z_3\)
\(\sigma(z_1)\)
\(\sigma(z_2)\)
\(\sigma(z_3)\)
\(\sum\)
1.47
-0.39
0.22
0.69
0.11
0.20
1.00
5.00
6.00
4.00
0.24
0.67
0.09
1.00
0.90
0.80
1.10
0.32
0.29
0.39
1.00
-2.00
2.00
-3.00
0.02
0.98
0.01
1.00
Softmax
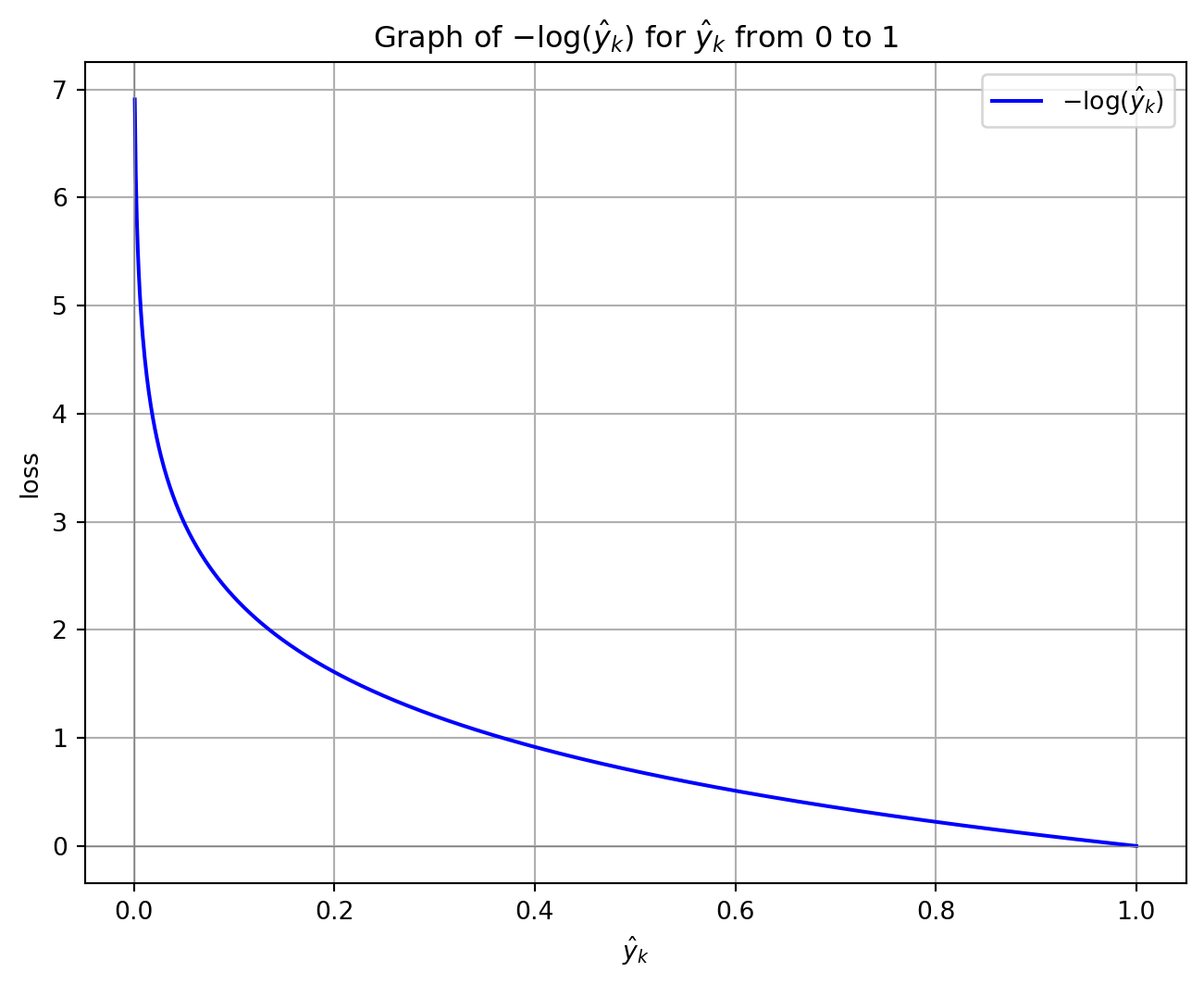
Cross-entropy loss function
The cross-entropy in a multi-class classification task for one example:
\[
J(W) = -\sum_{k=1}^{K} y_k \log(\hat{y}_k)
\]
Where:
\(K\) is the number of classes.
\(y_k\) is the true distribution for the class \(k\).
\(\hat{y}_k\) is the predicted probability of class \(k\) from the model.
Cross-entropy loss function
Classification Problem: 3 classes
Versicolour, Setosa, Virginica.
One-Hot Encoding:
Setosa = \([0, 1, 0]\).
Softmax Outputs & Loss:
\([0.22,\mathbf{0.7}, 0.08]\): Loss = \(-\log(0.7) = 0.3567\).
\([0.7, \mathbf{0.22}, 0.08]\): Loss = \(-\log(0.22) = 1.5141\).
\([0.7, \mathbf{0.08}, 0.22]\): Loss = \(-\log(0.08) = 2.5257\).
Case: one example
Code
import numpy as npimport matplotlib.pyplot as plt# Generate an array of p values from just above 0 to 1p_values = np.linspace(0.001, 1, 1000)# Compute the natural logarithm of each p valueln_p_values =- np.log(p_values)# Plot the graphplt.figure(figsize=(8, 6))plt.plot(p_values, ln_p_values, label=r'$-\log(\hat{y}_k)$', color='b')# Add labels and titleplt.xlabel(r'$\hat{y}_k$')plt.ylabel(r'loss')plt.title(r'Graph of $-\log(\hat{y}_k)$ for $\hat{y}_k$ from 0 to 1')plt.grid(True)plt.axhline(0, color='gray', lw=0.5) # Add horizontal line at y=0plt.axvline(0, color='gray', lw=0.5) # Add vertical line at x=0# Display the plotplt.legend()plt.show()
Case: Dataset
For a dataset with \(N\) examples, the average cross-entropy loss over all examples is computed as:
\[
L = -\frac{1}{N} \sum_{i=1}^{N} \sum_{k=1}^{K} y_{i,k} \log(\hat{y}_{i,k})
\]
Where:
\(i\) indexes over the different examples in the dataset.
\(y_{i,k}\) and \(\hat{y}_{i,k}\) are the true and predicted probabilities for class \(k\) of example \(i\), respectively.
Regularization
Definition
Regularization comprises a set of techniques designed to enhance a model’s ability to generalize by mitigating overfitting. By discouraging excessive model complexity, these methods improve the model’s robustness and performance on unseen data.
Adding penalty terms to the loss
In numerical optimization, it is standard practice to incorporate additional terms into the objective function to deter undesirable model characteristics.
For a minimization problem, the optimization process aims to circumvent the substantial costs associated with these penalty terms.
Below, \(\alpha\) and \(\beta\) determine the degree of regularization applied; setting these values to zero effectively disables the regularization term.
Dropout is a regularization technique in neural networks where randomly selected neurons are ignored during training, reducing overfitting by preventing co-adaptation of features.
Dropout
During each training step, each neuron in a dropout layer has a probability \(p\) of being excluded from the computation, typical values for \(p\) are between 10% and 50%.
While seemingly counterintuitive, this approach prevents the network from depending on specific neurons, promoting the distribution of learned representations across multiple neurons.
Dropout
Dropout is one of the most popular and effective methods for reducing overfitting.
The typical improvement in performance is modest, usually around 1 to 2%.
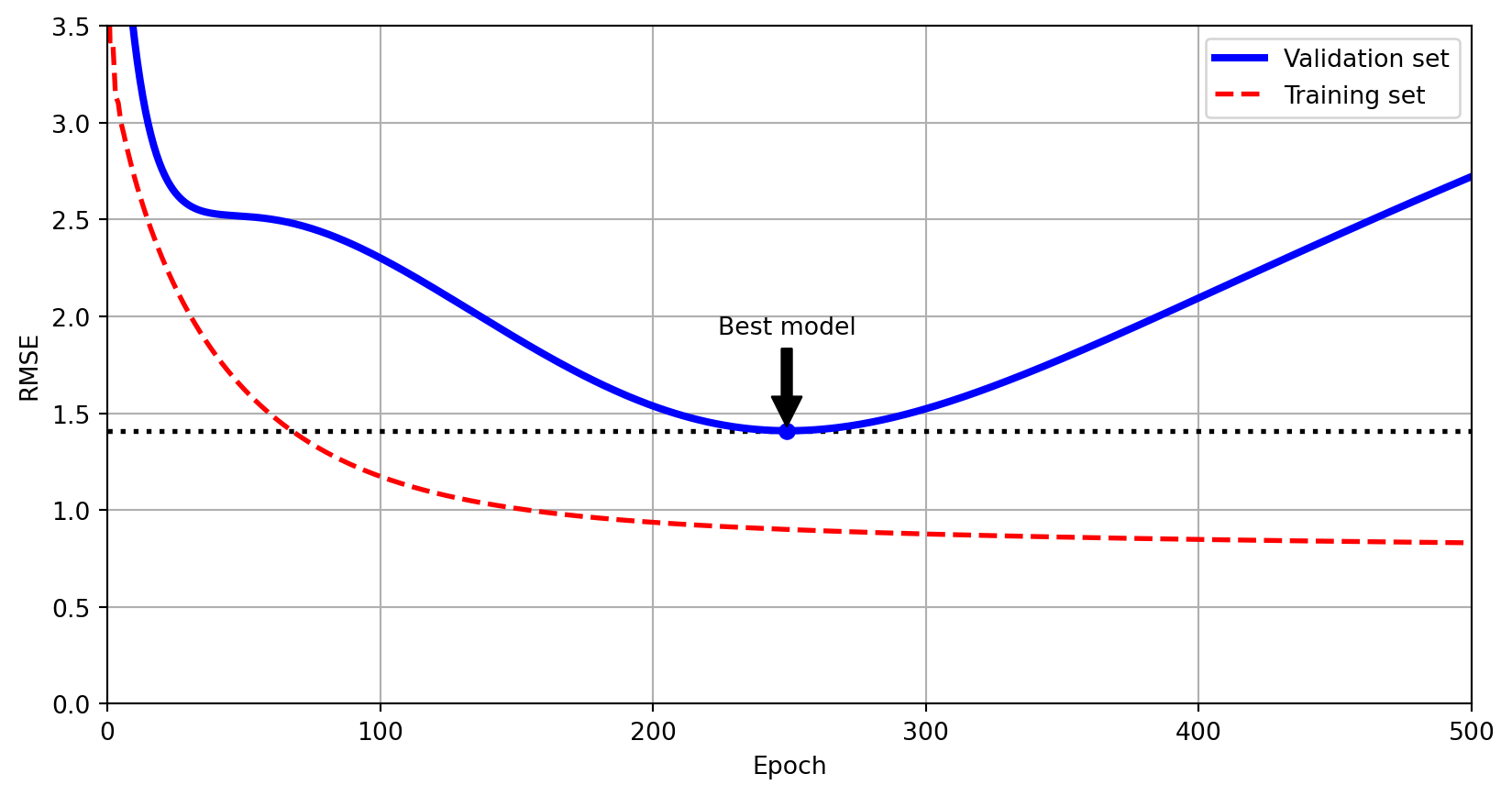
Early stopping is a regularization technique that halts training once the model’s performance on a validation set begins to degrade, preventing overfitting by stopping before the model learns noise.
Early Stopping
Code
from copy import deepcopyfrom sklearn.metrics import root_mean_squared_errorfrom sklearn.preprocessing import StandardScalerfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.linear_model import SGDRegressor# extra code – creates the same quadratic dataset as earlier and splits itnp.random.seed(42)m =100X =6* np.random.rand(m, 1) -3y =0.5* X **2+ X +2+ np.random.randn(m, 1)X_train, y_train = X[: m //2], y[: m //2, 0]X_valid, y_valid = X[m //2 :], y[m //2 :, 0]preprocessing = make_pipeline(PolynomialFeatures(degree=90, include_bias=False), StandardScaler())X_train_prep = preprocessing.fit_transform(X_train)X_valid_prep = preprocessing.transform(X_valid)sgd_reg = SGDRegressor(penalty=None, eta0=0.002, random_state=42)n_epochs =500best_valid_rmse =float('inf')train_errors, val_errors = [], [] # extra code – it's for the figure belowfor epoch inrange(n_epochs): sgd_reg.partial_fit(X_train_prep, y_train) y_valid_predict = sgd_reg.predict(X_valid_prep) val_error = root_mean_squared_error(y_valid, y_valid_predict)if val_error < best_valid_rmse: best_valid_rmse = val_error best_model = deepcopy(sgd_reg)# extra code – we evaluate the train error and save it for the figure y_train_predict = sgd_reg.predict(X_train_prep) train_error = root_mean_squared_error(y_train, y_train_predict) val_errors.append(val_error) train_errors.append(train_error)# extra code – this section generates and saves Figure 4–20best_epoch = np.argmin(val_errors)plt.annotate('Best model', xy=(best_epoch, best_valid_rmse), xytext=(best_epoch, best_valid_rmse +0.5), ha="center", arrowprops=dict(facecolor='black', shrink=0.05))plt.plot([0, n_epochs], [best_valid_rmse, best_valid_rmse], "k:", linewidth=2)plt.plot(val_errors, "b-", linewidth=3, label="Validation set")plt.plot(best_epoch, best_valid_rmse, "bo")plt.plot(train_errors, "r--", linewidth=2, label="Training set")plt.legend(loc="upper right")plt.xlabel("Epoch")plt.ylabel("RMSE")plt.axis([0, n_epochs, 0, 3.5])plt.grid()plt.show()
Prologue
Summary
Introduction to Deep Learning in Bioinformatics: Overview of models and repositories like Kipoi, Hugging Face, and DragoNN.
Neural Network Fundamentals: Discussion of network layers, activation functions (e.g., sigmoid, tanh, ReLU, Leaky ReLU, softmax), and the universal approximation theorem.
Notation and Architecture: Detailed explanation of how multi-layer perceptrons and feedforward networks are structured and notated.
Training Mechanics: Step-by-step breakdown of forward propagation, loss computation, and backpropagation using gradient descent.
Challenges and Solutions: Exploration of issues such as vanishing/exploding gradients and methods to mitigate them (e.g., proper initialization, dropout, early stopping).
Practical Code Examples and Visualizations: Demonstrations using Keras and TensorFlow to illustrate the concepts in action.
3Blue1Brown
3Blue1Brown
A series of videos, with animations, providing the intuition behind the backpropagation algorithm.
Angermueller, Christof, Tanel Pärnamaa, Leopold Parts, and Oliver Stegle. 2016. “Deep Learning for Computational Biology.”Mol Syst Biol 12 (7): 878. https://doi.org/10.15252/msb.20156651.
Avsec, Ziga, Roman Kreuzhuber, Johnny Israeli, Nancy Xu, Jun Cheng, Avanti Shrikumar, Abhimanyu Banerjee, et al. 2019. “The Kipoi Repository Accelerates Community Exchange and Reuse of Predictive Models for Genomics.”Nature Biotechnology 37 (6): 592–600. https://doi.org/10.1038/s41587-019-0140-0.
Géron, Aurélien. 2022. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 3rd ed. O’Reilly Media, Inc.
Glorot, Xavier, and Yoshua Bengio. 2010. “Understanding the Difficulty of Training Deep Feedforward Neural Networks.” In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, edited by Yee Whye Teh and Mike Titterington, 9:249–56. Proceedings of Machine Learning Research. Chia Laguna Resort, Sardinia, Italy: PMLR. https://proceedings.mlr.press/v9/glorot10a.html.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. “Deep Residual Learning for Image Recognition.” In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–78. https://doi.org/10.1109/CVPR.2016.90.
Hinton, Geoffrey E., Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2012. “Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors.”CoRR abs/1207.0580. http://arxiv.org/abs/1207.0580.
Hornik, Kurt, Maxwell Stinchcombe, and Halbert White. 1989. “Multilayer Feedforward Networks Are Universal Approximators.”Neural Networks 2 (5): 359–66. https://doi.org/https://doi.org/10.1016/0893-6080(89)90020-8.
Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. 1986. “Learning representations by back-propagating errors.”Nature 323 (6088): 533–36. https://doi.org/10.1038/323533a0.